0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

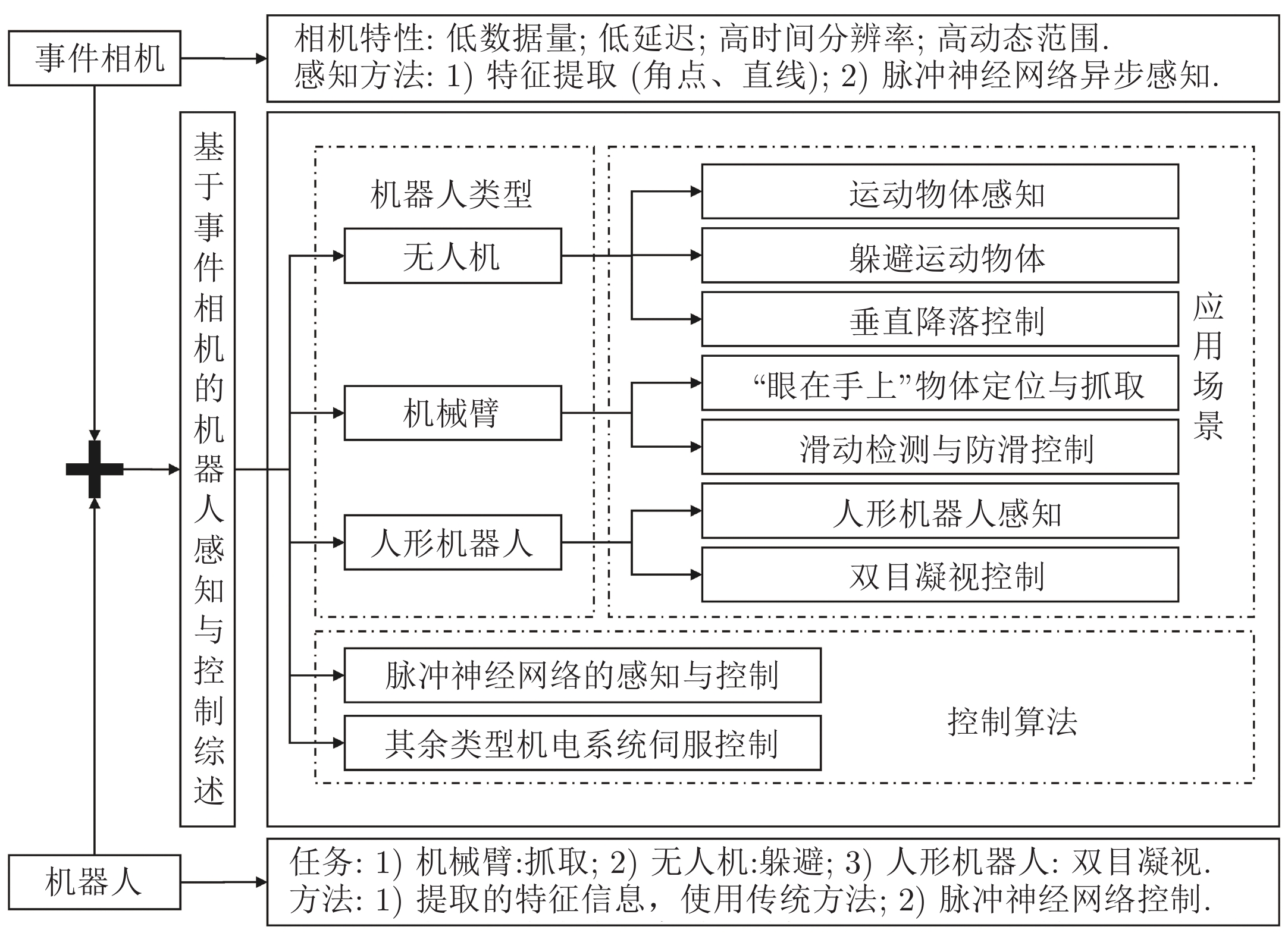
图 1 本文结构图
Fig. 1 Structure diagram of this paper
近年来, 类似无人机、机械臂等机器人系统在各个领域(如消防安防、植保农业、工厂制造等)得到日益广泛的应用, 四足机器人、人形机器人等系统也成为机器人领域的研究热点; 可以预见机器人系统将在未来的智能制造、工业4.0革命中发挥愈发突出的作用. 上述机器人系统均为结构复杂、高度集成的机电系统, 系统的运动规划和控制常依赖对所在环境和目标的感知测量. 目前大部分的无人机、机械臂均采用传统的帧相机作为感知器件, 但是, 帧相机具有固有的高数据量、低时间分辨率、高延迟等特点, 对快速运动的物体感知能力较弱, 极大地限制了机器人的操控能力.
在此背景下, 一种基于生物视觉成像原理的神经形态传感器——事件相机受到机器人领域学者的关注, 将其与机器人感知和控制结合, 涌现出一批突破传统帧相机限制的机器人控制成果. 本文从事件相机的基本原理开始, 依次综述事件相机与无人机、机械臂、人形机器人结合的最新成果, 并介绍在控制方法上, 结合事件相机特性的控制技术最新发展, 以期对这一快速发展的领域提供参考. 本文结构图如图1所示.
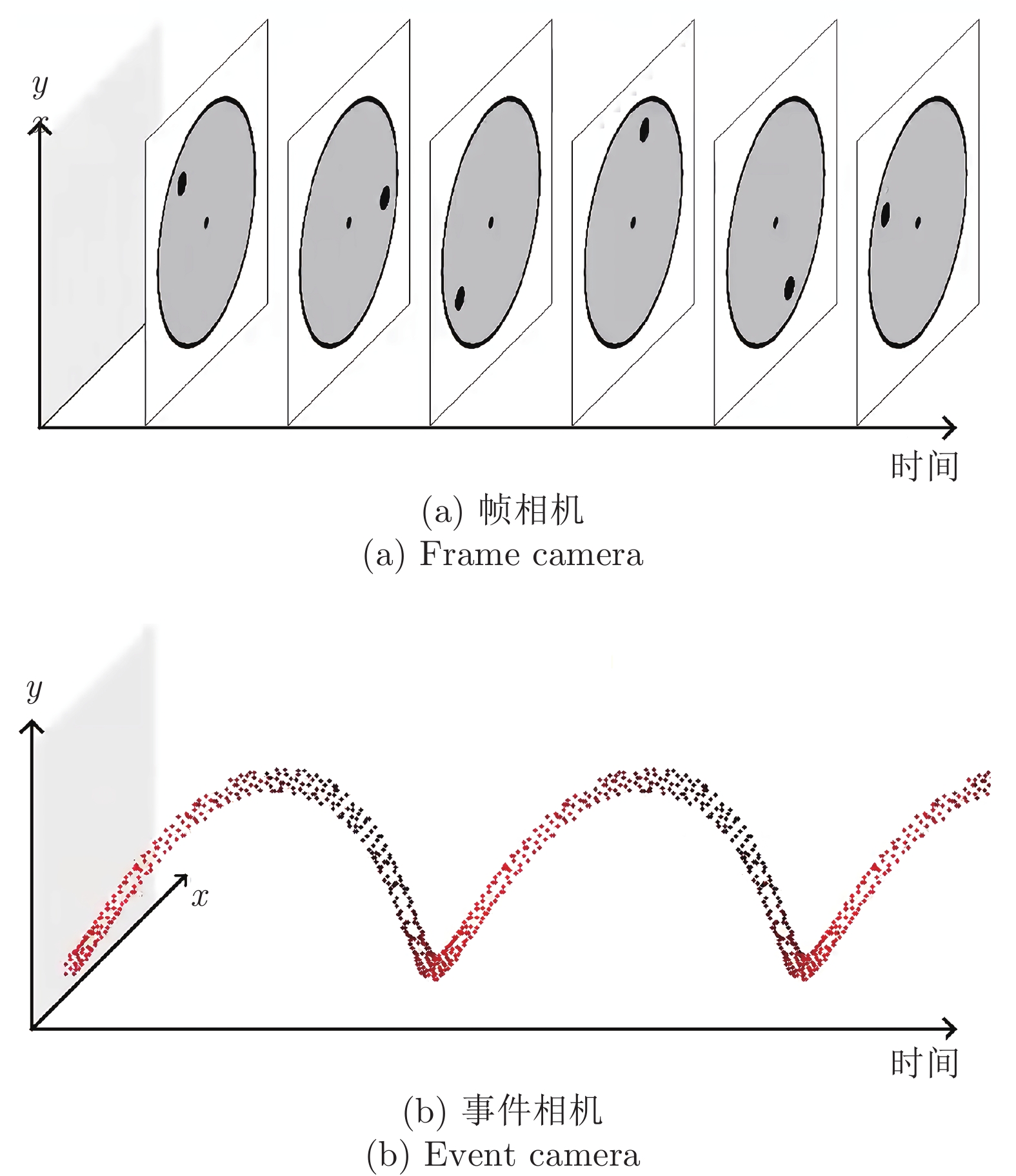
事件相机(Event camera)是受生物视觉系统启发的一类新型神经形态视觉传感器, 与基于帧的视觉传感器在工作原理上存在着不同. 帧相机(Frame camera)的曝光时间是固定的, 即便某个像素上的光照没有发生变化, 它也会重复曝光. 相比之下, 事件相机的每个像素点独立的检测其上的亮度变化, 生成异步的事件流数据, 该数据包括时间戳、像素地址和亮度变化的极性.
事件相机像素点上的亮度变化要由目标对象或传感器运动引起[1]. 当多个像素点同时请求事件输出时, 这些事件将以亚微秒级时延异步输出并构成事件流. 旋转圆盘场景下帧相机与事件相机输出对比如图2所示, 展示了传统帧相机与事件相机对高速转动圆盘上固定点进行一段时间跟踪拍摄得到的结果. 图2(a)显示传统帧相机以固定频率记录整个圆盘信息, 信息冗余度高, 帧间丢失了跟踪点的信息. 而图2(b)的事件相机则连续记录跟踪点对应的运动事件, 以异步的方式记录有用的运动信息, 具有低时延、低带宽需求的特点.
事件被触发以像素地址-事件流的形式输出, 地址−事件流数据包含事件的像素坐标、触发时间和极性(亮度变化的信号)三类信息. 触发的事件表示为
| (1) |
事件e表示在事件相机上位于
| (2) |
c为事件点的激发阈值, p为亮度变化值. 当亮度增量大于c时, 激发正极性事件点, 当亮度增量小于 −c时, 激发负极性事件点, 当亮度增量的绝对值小于c时, 事件相机无输出.
事件相机的出现, 可以追溯到1992年, Mahowald[4]在博士论文中提出了一种“硅视网膜”视觉传感器. 这是首个输出地址−事件流的视觉传感器, 但它只是事件相机的雏形, 像素面积过大导致它无法得到实际使用. Boahen[5]在2002年开发了编码增量视觉信号的视网膜启发芯片, 模拟生物视网膜的空间视觉通路(Parallel pathway).
Kramer[6]在2002年提出了一种积分光瞬态传感器, 缺点是传感器的对比灵敏度较低. Ruedi等[7]在2003年提出了空间对比度和局部定向视觉传感器, 其输出编码的是空间对比度而不是时间对比度. 在一个全局帧积分周期之后, 该设备按从高到低的空间对比顺序传输事件, 每个对比度事件后面都跟着一个编码梯度方向的事件. Luo等[8]在2006年提出了一种基于首次时间脉冲(Time-to-first-spike, TTFS)技术的CMOS (Complementary metal oxide semiconductor)相机, 该相机利用每个像素的单个脉冲时序来编码每个像素的光度. 这种光度的时间表示可以将图像传感器的动态范围扩大到100 dB以上, 并引入了异步地址事件读取技术以降低功耗. Chi等[9]在2007年提出了一种时间变化阈值检测相机, 它对传统源像素传感器(Active pixel sensor, APS)的像素进行了改进, 使其能够检测绝对光度变化, 该同步装置存储信号变化的像素地址, 构成一种同步地址事件表示(Address event representation, AER)的图像传感器. Lichtsteine等[10]在2008年提出了第一台商用的事件相机, 称为基于异步事件的动态视觉传感器(Dynamic vision sensor, DVS). 在DVS的基础上, 目前已经开发了几种具有附加功能的事件相机. 如DAVIS、ATIS等, 详见第1.4节.
事件相机异步地测量每个像素的亮度变化, 而非以固定速率捕获图像帧, 因此能克服传统帧相机的局限性并且具有特有的优异属性, 如高时间分辨率、低延迟、低功耗、高动态范围等, 在高速和高动态范围场景中有着广阔的应用空间.
1)高时间分辨率. 事件相机是通过检测像素点处的亮度变化产生事件, 其对亮度变化产生的响应速度极快, 输出频率可达1 MHz, 即事件时间戳分辨率为微秒级. 因此, 事件相机可以捕捉到高速运动, 不会受到运动模糊的影响.
2)低延迟. 事件相机可近乎实时地输出亮度变化, 平均延迟在
3)低数据量和低功耗. 事件相机以稀疏事件流的形式输出视觉信号, 事件流中不包含静态背景的任何信息, 因此过滤了大量冗余数据. 因为仅传输像素点的亮度变化, 不需要用于像素读取的模数转换器, 从而避免了大量冗余数据的传输, 能耗仅用于处理变化的像素. 大多数事件相机功耗约在10 mW级, 甚至有些相机原型的功耗低于
4)高动态范围. 事件相机不受白平衡、感光度等统一成像参数影响, 在图像过暗、曝光过度、光线突变等情况下, 依然可以通过触发事件来获取视觉信息. 因此, 具有极高的动态范围(>120 dB), 甚至可高达143 dB[15]. 而帧相机通常只能达到60 dB, 所以, 事件相机在光照条件良好的白天或者光线较暗的夜晚均能够有效地工作.
上述优点与各类机器人控制结合, 能够突破传统帧相机的限制, 实现机器人系统对快速运动目标的感知和响应、大大降低感知系统的功耗、提高在复杂光照(强光、暗光)条件中的感知能力. 尽管如此, 目前在应用上也存在一些挑战, 主要包括硬件缺陷造成的挑战以及处理范式转变带来的挑战[11]:
1)噪声. 光子中存在固有的散粒噪声以及晶体管电路中存在的噪声, 使得视觉传感器本身就携带大量的噪声事件, 当物体或相机运动时也会产生一系列噪声事件, 并且它们是非理想性的. 因此如何从噪声中提取有效事件信息是研究者所要解决的问题.
2)信息的处理. 与帧相机提供的灰度信息相比, 事件相机产生的每个事件仅提供二进制亮度变化信息(亮度增加或减少, 以事件的极性表示). 并且亮度变化不仅取决于场景亮度, 还取决于场景和相机之间的过去和当前的运动变化, 处理这种二进制信息具有挑战性.
3)新的算法. 事件相机的输出与帧相机有着根本的不同, 事件是异步的、空间稀疏的, 而图像是同步的、密集的. 因此, 现有的大多数计算机视觉算法在事件相机上无法直接使用, 因此开发特有的新算法是充分应用事件相机的前提.
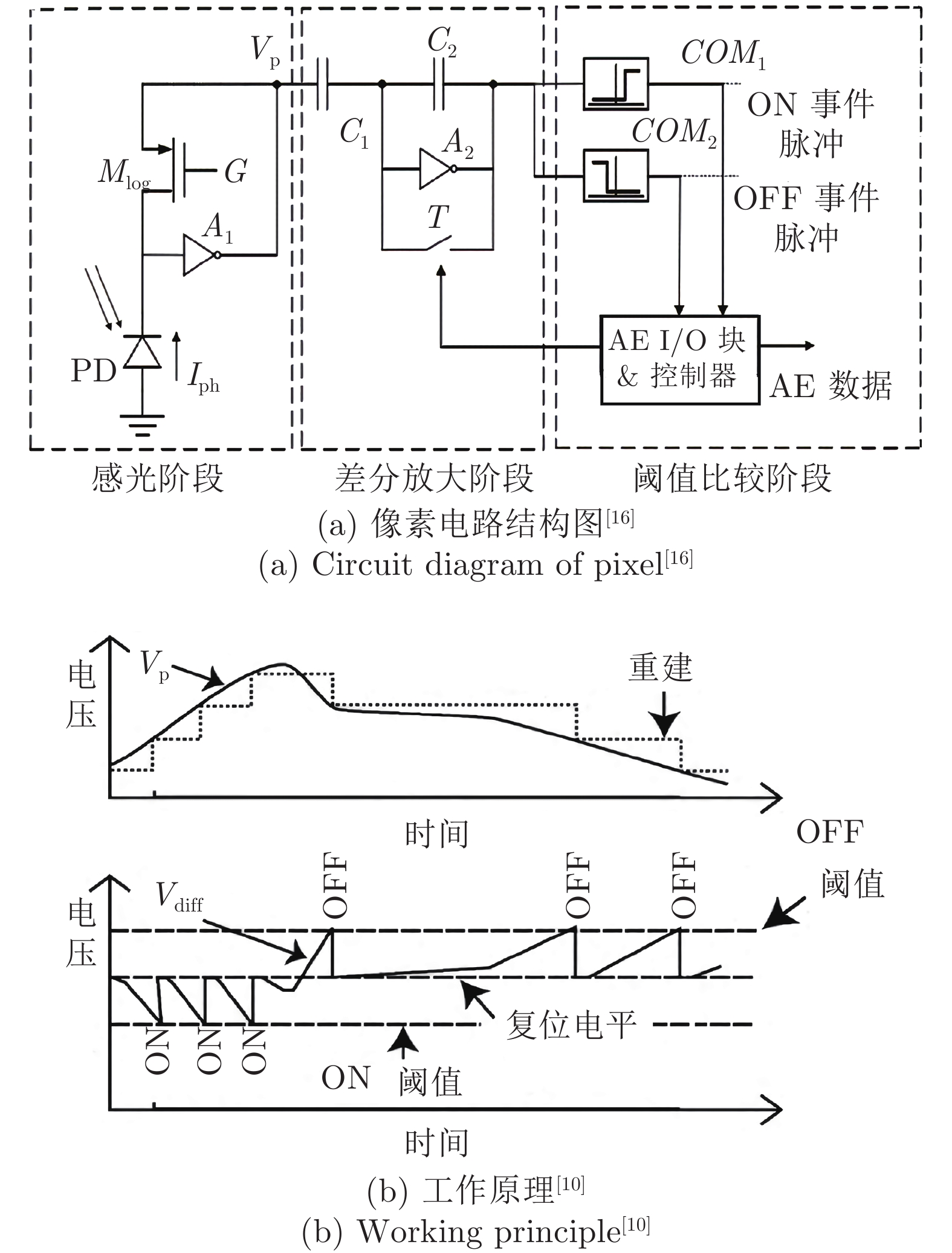
DVS为事件相机的一种, 是众多类视觉传感器的基础. 它是一种基于时间的异步动态视觉传感器, 模拟生物视网膜空间视觉通路的功能, 试图感知场景的动态信息. DVS像素由快速对数光感受器(Photoreceptor)、差分电路(Differencing)和两个比较器(Comparators)组成, 以微秒级时间分辨率响应亮度相对变化. 它的单个像素结构和工作原理简化图[10, 16]分别如图3(a)和图3(b)所示. 感光电路主要由一个光电二极管、一个串联的晶体管和一个负反馈回路构成, 它能感知光线强度变化并及时给出响应. 差分电路可以将感光电路的输出进行放大, 并减少晶体管因工艺制作带来的误差. 阈值比较电路主要是通过比较器比较电压的变化实现ON/OFF事件脉冲的输出. 若光线变亮, 电压变化量大于ON事件的阈值, 则会输出一个脉冲表示ON事件; 若光线变暗, 电压变化量小于OFF事件的阈值, 则会输出一个脉冲表示OFF事件. 如果电压达到饱和值, 复位信号会将电压进行复位, 不产生ON或OFF信号. 2020年Samsung开发的最新款DVS具有1280 × 960的分辨率, 每像素功耗低至122 nW与4.95 μm的像素间距[17].
Posch等[15, 18]在2011年提出基于异步时间的图像传感器(Asynchronous time-based image sensor, ATIS). ATIS在DVS上进行改进, 加入了脉冲宽度调剂环节, 在其受到光强变化产生事件信号时激发另一子像素进行曝光成像, 可以得到亮度变化超过阈值部分像素的强度图像, 也就是可以在输出光线强度变化信息的同时输出对应点的光线强度信息. Chronocam供应的系列最新款ATIS视觉传感器拥有304 × 240的分辨率, 最高达143 dB的动态范围与30 μm × 30 μm的像素面积.
为了解决DVS难以直接应用现有算法的问题, Brandli等[19]和Taverni等[20]开发了动态和有源像素视觉传感器(Dynamic and active pixel vision sensor, DAVIS). DAVIS是DVS相机和传统的APS相机的结合体, 将APS电路和DVS电路共用一个光电二极管, 实现异步事件和同步帧级图像的同时输出. DAVIS像素也分为两个子结构, 其中一个子结构用于监测光照变化的事件, 而另一个子结构像传统的APS相机一样进行同步的曝光. 不同于ATIS的是, DAVIS像素的两个子结构是共用同一个感光器的, 而ATIS像素的两个子像素有各自的感光器. 因此, DAVIS相机的像素面积较ATIS相机的像素面积更小, 前者的填充因数较后者的更大. 通过DAVIS获取的灰度图和通过传统APS相机获取的灰度图一样, 具有时间冗余性和空间冗余性, 并且无法承受高动态范围的环境. 由iniVation公司供应的系列最新款DAVIS 346视觉传感器拥有346 × 260的分辨率, 最高达120 dB的动态范围与18.5 μm × 18.5 μm的像素面积.
2019年上海芯仑科技发布CeleX-V事件相机[21], 具有1280 × 800的分辨率, 同时时域最大输出采样频率为160 MHz, 动态范围为120 dB, 是第一款达到百万像素级别的相机, 该传感器采用65 nm CIS (CMOS image sensor)工艺实现, 像素尺寸为9.8 μm × 9.8 μm, 具有高空间分辨率、高时域分辨率和高动态范围的优势, 引起了当前事件相机领域的关注. CeleX-V将多个视觉功能集成到一个图像传感器中, 实现全阵列并行运动检测和全帧图像输出, 它还可以实现片上光流提取.
表1总结了目前主流事件相机的性能.
无人机(Unmanned aerial vehicle, UAV)具有体积小、造价低、使用方便、对使用环境要求低、生存能力较强等优点, 广泛应用于航拍、植保、测绘、巡检等领域. 为了进一步提升无人机对环境的感知能力, 已有众多学者结合事件相机的低数据量、低延迟、高动态范围等特性, 对无人机运动控制问题进行了研究, 实现了在基于传统帧相机为感知器件时, 较难实现的快速感知、避障和垂直降落动作.
在无人机的实际应用中, 会受到如鸟类、敌方目标的干扰, 因此需要在较短的时间内进行障碍物的躲避. 无人机受到重量、功耗等限制, 对数据处理的计算复杂性、功耗、延迟有着极大的限制, 因事件相机低功耗、低数据量、低延迟的特性, 很适合装载于无人机上, 完成相应任务. 从理论上来说, 传统相机对环境的感知延迟约20 ~ 40 ms, 事件相机的感知延迟仅为2.2 ± 2 ms, 能够为无人机预留更长的机动时间. 下面分别从基于事件相机的无人机感知、避障、垂直降落等方面, 介绍该方向的工作.
因为无人机较快的运动速度, 对数据处理实时性提出了较高的要求, 为了研究事件相机的极限跟踪效果, Chamorro等[22]提出了一种超快速跟踪的方法. 使用如图4所示的实验环境, 事件相机静止放置于四杆装置前20 cm, 由直流电机驱动四杆装置进行快速晃动, 该装置上搭载画有几何图形的平面, 用以产生事件, 并通过事件相机进行观测, 用以求解物体的位姿.
图4(a)模拟了事件相机成像平面. 这项实验具有Lie参数化功能[23], 提出了一种新的Lie-EKF公式用于跟踪物体的6自由度状态. 为了测试该方法的追踪极限, 直流电机的速度逐渐增加, 直到大约950 r/min (15.8 Hz), 跟踪性能开始下降. 在这样的角速度下, 装置的速度分析报告的最大目标速度为2.59 m/s. 线性目标加速度达到253.23 m/s2或25.81 g, 远远高于最苛刻的机器人应用的预期范围. 根据所使用的运动模型和状态参数, 跟踪器能够处理89.1%到97.7%的输入数据, 达到实时性能, 并以10 kHz的速率产生姿态更新, 并且即使在亮度骤然变化时(开、关灯), 仍然能保证较好的性能.
Mueggler等[2]提出了带有事件相机的四旋翼高速机动的全3D轨迹跟踪, 通过搭载在无人机上的事件相机记录事件流, 事件数据由无线网络传输到笔记本电脑上实时可视化, 同时记录了前置标准CMOS相机的视频. 实验过程成功演示了在四旋翼翻转期间转速高达1200°/s时的位姿跟踪. 但是该方法适用环境有限, 也不能用于闭环控制.
Dimitrova等[24]在装有事件相机的无人机平台上解决了一维姿态跟踪的问题, 并实现了闭环控制. 在双旋翼直升机上搭载事件相机作为感知设备. 实验装置如图5所示, 其中黑白圆盘为参考图, 位于事件相机前方10 cm的位置, 黑白两部分之间的分界线为要跟踪的参考基准线, 在该实验中, 将卡尔曼滤波器与改进的Hough变换算法相结合, 构成基于事件的状态估计器, 计算双旋翼直升机相对于基准线的滚转角和角速度. 并通过旋转编码器提供转盘和无人机的真实测量角度, 用于评估基于事件的状态估计器和控制器的性能. 实验中双旋翼无人机已最小化地面和周围结构的空气动力学影响, 状态估计器以1 kHz的更新速率和12 ms的延迟执行, 能够以1600°/s的速度跟踪基准线, 并同时控制无人机以1600°/s的高速跟踪基准线. 该方法呈现了良好的事件相机驱动闭环控制的结果. 但是实验中的状态估计步骤繁琐, 适用范围也不广. 该文作者后续也将继续研究如何使用事件直接编码控制信号, 完全消除状态估计步骤.
文献[25]是第一个使用事件相机进行躲避高速运动物体的工作. 基于无人机携带的双目事件相机, 设计了一种球形物体追踪器, 使用扩展卡尔曼滤波进行数据处理, 可以在250 ms内预测碰撞, 并可以躲避6 m远处以10 m/s的速度飞来的球. 但因实验平台的限制, 仅从理论上验证了在无人机这样的小型嵌入式平台上, 检测并躲避障碍物的可行性.
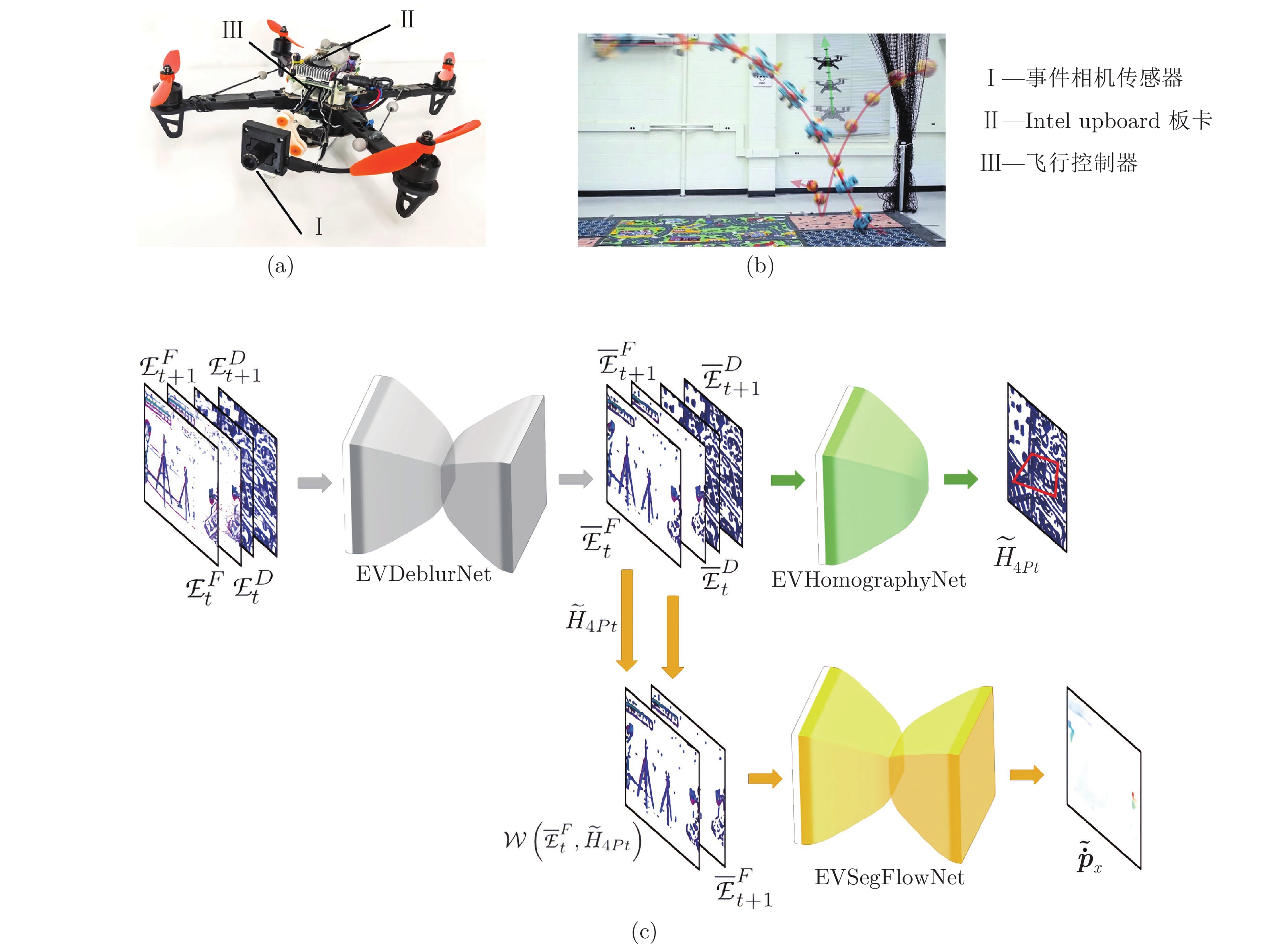
为了进一步探究事件相机的优势, Falanga等[26]对搭载单目、双目以及事件相机3种传感器的无人机进行了实验. 实验结果表明了在2 m的感知范围下, 事件相机的延迟(2 ~ 4 ms)(指从视觉传感器被触发到将数据传输到处理模块的时间)显著低于普通单目相机(26 ~ 40 ms)和双目相机(17 ~ 70 ms). 对于已知大小的障碍物, 使用聚类和光流算法对事件流数据进行处理来跟踪物体, 仅考虑水平移动, 搭载事件相机的无人机可在2 m的感知范围内躲避相对速度高达9 m/s的障碍物. 实验平台如图6(a)所示.
文献[27]使用了浅层神经网络从事件流中分割出独立运动对象, 并对其三维运动进行推理, 以执行闪避任务, 闪避场景如图6(b)所示, 四旋翼无人机使用EVDodgeNet进行障碍物躲避. 然后将其扩展到追踪任务, 这是第一个基于深度学习的解决方案, 网络如图6(c)所示, 由3个网络组成, 去模糊网络EVDeblurNet, 用于将
在文献[26-27]的理论基础上, 文献[28]在相同的实验环境下, 仅使用事件相机进行数据捕捉, 该方法使用精度换时间的策略, 从收到待处理事件到发出第一条避障指令, 时延仅为3.5 ms, 且成功率超过90%. 在感知环节, 为降低计算量, 对文献[29]中提出的方法进行改进, 仅使用IMU (Inertial measurement unit)进行自我运动补偿, 将事件数据区分为静态场景与动态对象. 再通过聚类区分不同物体并结合双目深度信息计算三维坐标, 并将该位置作为卡尔曼滤波的测量输入计算其速度信息. 而在避障环节, 为降低计算量, 使用了基于反应式的人工势场法回避方案[30], 避免了由于数值优化而引入延迟. 同时为方便处理, 利用二维平面中的数据将障碍物构造成椭圆体建立排斥场, 目标运动位置构造引力场, 最终向控制器输出运动速度. 算法的总延迟从文献[27]中的60 ms提升到了3.5 ms, 且能够在板载处理器上实时运行, 极大地提升了响应速度. 在室内及室外的实验中, 均可躲避相对速度10 m/s的障碍物, 可以连续躲避多个障碍物, 并且躲避成功率超过90%.
而在基于传统相机的避障工作中, Lin等[31]的单目方案延迟可优化到150 ms, 可以在2.2 m/s的移动速度下躲避障碍物. Oleynikova等[32]的双目方案, 从图像曝光到路点规划的整体时延为14.1 ms (曝光时间3 ms), 能够在5 m/s的飞行速度下, 对0.07 m远处的障碍物进行响应. Barry等[33]在无人机上搭载双目120 Hz相机, 能在14 m/s的速度下实现避障. Huang等[34]使用30 Hz的RGB-D相机在机载芯片上数据处理时间为25 ms. 因为传统图像数据量较大, 目前很多方案会将数据传回地面站进行计算, 更进一步加大了延迟, 可见因事件相机的独特优势, 已经逐渐展现出了应用潜力.
当前的这些工作中, 导致躲避失败的主要因素是检测到障碍物的时间太晚, 导致无人机无法及时地完成规避动作, 主要原因是: 1)当障碍物进入到相机视野时, 距离已经不足以使飞行器完成规避动作; 2)障碍物的运动没有产生足够的事件(如物体垂直于像平面运动, 仅物体边缘产生少量事件), 算法无法及时检测到障碍物.
文献[26]的研究中也发现事件相机的延迟并不是恒定的, 而是取决于相机与障碍物之间的距离与速度, 障碍物速度越大、距离越近, 响应时间越短. 因此该文献认为, 在当前, 双目相机在性能、成本上能够有很好的折衷, 仍然是无人机的最佳选择之一, 而随着技术的发展, 事件相机能够在未来提供更好的解决方案.
为了模仿鸟类着陆, 现有的无人机垂直着陆解决方案均在无人机底部安装事件相机, 如图7所示, 以观察地面信息.
文献[35]使用如图7所示的实验装置. 同时在事件流和基于事件帧的图像上进行直线追踪, 使用扩展卡尔曼滤波将二者结合, 利用前者的快速响应和后者的鲁棒性, 可以高速、有效地跟踪直线, 进而在时空中生成直线可能所在的平面, 整体频率高达339 Hz. 再利用Tau理论[36]进行位置调整可以有效地引导无人机, 为着陆、悬停提供空间信息.
Pijnacker Hordijk等[37]最先将基于事件的光流集成到无人机应用中, 提出了一种高效的平面几何光流估计技术, 尽管光流本身并不能提供运动的度量标度, 但是来自光流场的信息对于一些导航任务(包括着陆)十分有用. 实现了无人机的快速平稳着陆.
在文献[37]的理论基础上, 文献[38]使用神经进化(Neuro-evolution)优化人工神经网络, 设计了神经控制器, 学习现实世界中基于事件的光流控制. 对于使用事件相机与普通相机同时采集的数据, 该控制器输出了相近的控制策略, 证明了该控制器的鲁棒性.
文献[39]将文献[38]中的方法扩展到脉冲神经网络, 脉冲神经网络(Spiking neural network, SNN)是一种生物神经网络, 也是第三代神经网络模型[40]. 它采用脉冲神经元为基本单位, 脉冲神经元通过接收脉冲改变内部状态, 当状态超过阈值才会输出脉冲, 当未接收脉冲时脉冲神经元不工作, 因此SNN可以在极低的功耗下工作. 使用SNN可以更加充分地利用事件流信息, 以获得更有效的方案. 飞行昆虫能够在混乱的环境中快速飞行, 可以灵活地避开障碍物. 而自主微型飞行器(Micro aerial vehicle, MAV)远远落后于生物飞行器, 消耗的能量非常多. SNN不仅可以用来模拟人脑的神经网络, 文献[39]提出该网络还可以利用镜头向下的事件相机产生的光流散度控制MAV的飞行和着陆. 这项工作是第一次将SNN集成到真实飞行机器人的控制回路中. 不仅研究了如何大幅降低SNN控制器的脉冲率, 而且该方案可以节省大量的能量. 但是该控制器只能实现在常规芯片上, 不能在神经形态芯片上实现.
以上基于事件相机的无人机运动控制研究与结果描述如表2所示.
当前研究的主要目标为实现闭环控制以及实现低延迟高带宽的飞行控制. 但是当前研究中大部分仍然是基于传统的视觉算法, 并未充分利用事件相机异步更新的特性.
机械臂是由多个驱动关节串联组成的多自由度机电系统, 其通过安装于末端的执行器完成各类操作. 但是机械臂的运动规划和控制均依赖其对周围环境的感知, 确定被操作对象的位姿、状态、是否有障碍等等. 现有的感知手段包括视觉、触觉、力觉等. 其中基于视觉的感知具有低成本、易用性强等特点, 已成为机械臂感知的主流方法. 目前已有学者开始将事件相机作为机械臂的感知器件, 完成基于事件数据的静态物体抓取以及被夹持物体的滑动检测. 与传统的基于图像的方法相比, 事件相机在此场景中提供了更高的灵敏度、更低的延迟以及更少的功耗.
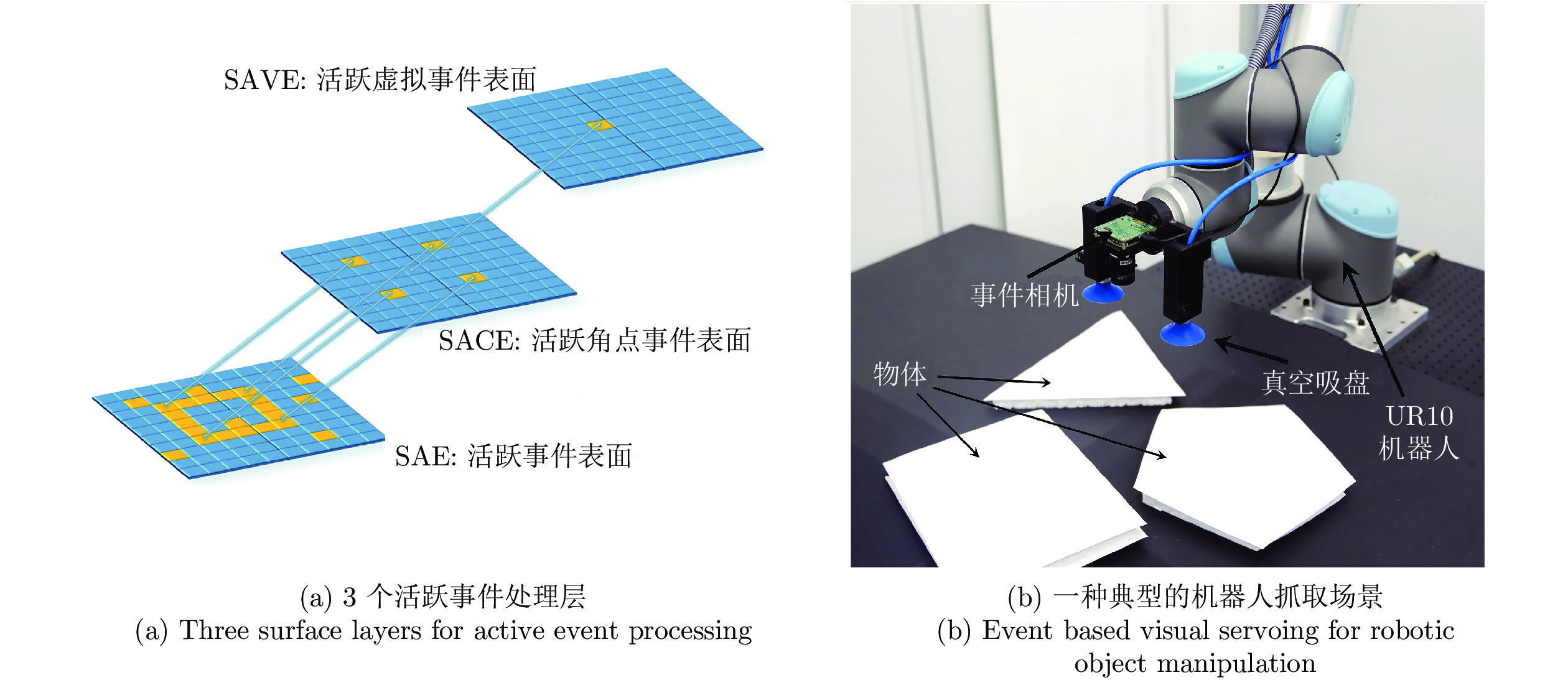
抓取物体是机械臂的基本能力. 眼在手上是指视觉传感设备安装于机械臂的末端, 伴随机械臂运动. Muthusamy等[41]首先在该问题上做出了尝试, 提出一种眼在手上的基于事件相机的机械臂抓取方案. 该方案初始化一个随机目标点, 控制机械臂使相机向该点运动以产生事件, 利用基于事件的视觉伺服(Event-based visual servoing, EBVS), 控制机械臂使目标中心与相机中心重合, 最后调整抓取角度以实现稳定抓取. 其中, EBVS采用活跃事件表面(Surfaces of active events, SAE)异步执行角点检测. 得到的角点储存在活跃角点事件表面(Surfaces of active corner events, SACE)并用于进一步跟踪和目标中心点计算.
目标中心点储存在活跃虚拟事件表面(Surfaces of active virtual events, SAVE), 用于二自由度视觉伺服和抓取角度计算. 3个活跃表面如图8 (a)所示. 该抓取方案采用如图8 (b)所示的结构, 机械臂末端安装两个真空吸盘, 在1.2 m × 1.0 m的工作台上对三棱柱、立方体、五棱柱三种物体进行了抓取实验. 在不同速度和不同光照条件下, 机械臂均能实现稳定抓取, 平均抓取误差(实际中心与抓取中心的误差距离)为16.1 mm. 但是这种抓取方式只适用于规则物体, 且要求像平面平行于工作台.
机械臂夹持物体后, 物体有可能产生滑动, 如果单纯地使用最大加持力, 则有可能损坏物体, 因此根据物体的滑动状态确定夹持控制方案, 能够恰到好处的完成机械臂夹取物体. 但是滑动是一瞬间发生的运动, 事件相机的低延迟特性, 恰好能够解决该场景对感知系统的需求.
文献[42]首次使用事件相机作为“触觉传感器”, 仅通过事件相机感知透明硅材料与不同物体之间的接触面积, 并通过传统的图像处理方法, 分析重建帧上的事件分布以进行滑动检测, 无需事先了解物体的属性或摩擦系数也可以成功检测到位移. 实验环境如图9所示, 在复杂光照下, 使用不同材质、形状、重量的物体上进行了实验, 滑动检测的平均精确率为0.85, 平均延迟为44.1 ms. 并同时使用高速相机进行了验证, 证明了方法的精确性. 但是不同的材质会对结果产生较大影响, 金属物体由于摩擦和物理粘性, 具有更好的效果. 并且会受到接触面积的影响, 接触面积较小的物体会产生更高的延迟.
相比于文献[42]中使用纯事件相机的方式, Taunyazov等将触觉传感器与事件相机结合, 提出了视觉−触觉脉冲神经网络(Visual-tactile spiking neural network, VT-SNN)[43], 将视觉和触觉两种感知方式用于监督学习中. 而且通过二者相结合的方式(Prophesee事件相机与NeuTouch触觉传感器), 实现了容器分类和物体的旋转滑动分类, 取得了比传统深度学习方法更好的效果. 最后在神经形态处理器Intel Loihi[44]上进行实验, 相比于使用GPU, 推理效率更高, 功耗表现更优.
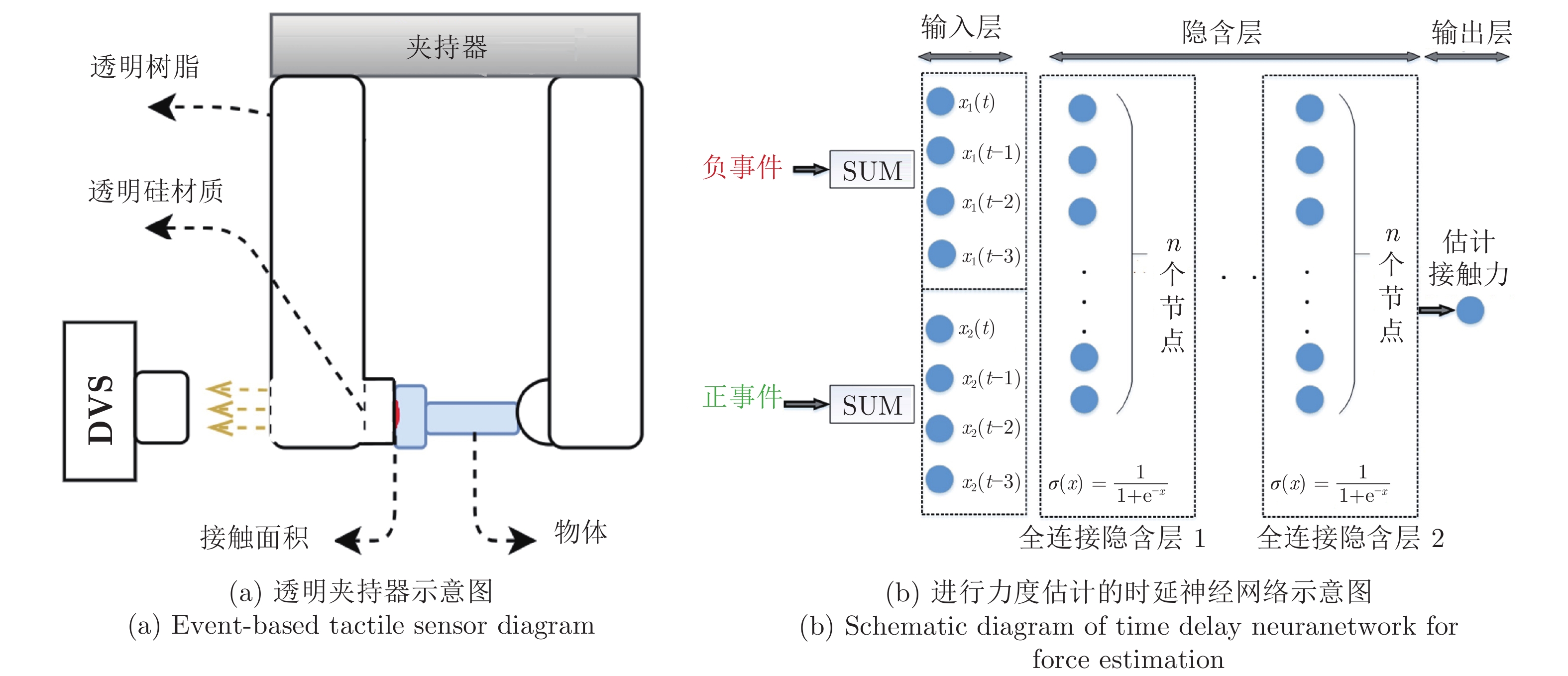
但是文献[42]中的实验场景显然不具备机动性, 因此Baghaei Naeini等[45]提出了一种新的基于视觉测量(Vision-based measurement, VBM)的方法, 夹持器示意图如图10 (a)所示, 直接采用透明硅介质作为夹持器. 这是第一个基于事件相机来测量接触力并在单次抓握中进行材料分类的方法, 提供了更高的灵敏度, 更低的时延以及更少的功耗. 实验通过图10 (b)中的时延神经网络(Time delay neural network, TDNN)和高斯过程(Gaussian process)估计相同形状、尺寸物体在抓取和释放两个阶段的接触力, 并使用深度神经网络仅通过接触力进行材料分类. 其中, TDNN方法的平均准确率为79.17%, 时延为21 ms, 均方误差(Mean square error, MSE)为0.16 N, 证明了基于事件的传感器对于机器人抓取应用的适用性.
但是因为不同尺寸的物体与透明硅材料的接触面积不同, 因此对于尺寸不同的物体, 需要复杂的动态方法来关联每个时间戳上的事件与力的测量值. 为了克服无法有效检测不同尺寸物体的问题, 因此在文献[45]的基础上, 提出了使用不同的长短记忆网络(Long short-term memory, LSTM)结构为传感器提供记忆, 进而动态估计接触力的方法[46]. 传感器在抓取的早期阶段识别物体的尺寸, 使用卷积网络与循环层结合的方式, 使传感器能够根据物体的大小估计相应的接触力. 在与文献[45]相同的实验条件下, 时延提升到10 ms, 误差从文献[45]中的0.16 N降低到0.064 N (MSE), 有着更优良的表现, 可以应用于实时抓取应用. 但是对于未知物体的泛化能力较弱.
Muthusamy等[47]使用事件相机作为滑动感知器件, 同样使用透明塑料板作为夹持器, 通过在物体上添加负载的方式使物体产生滑动; 能够以2 kHz的采样率实现夹持物体的滑动检测; 并根据检测到的滑动幅度, 使用Mamdani型模糊逻辑控制器来调节握力. 另外, 文献中提出了基于事件数量阈值与基于特征的两种滑动检测方法, 能够对环境进行噪声采样并自动校准. 其中对基于特征的滑动检测, 评估了3种特征检测算法、两种采样速率下以及复杂光照、震动环境下的性能. 实验证明, 使用e-Harries[48]特征的滑动检测具有更强的鲁棒性, 成功率超过90%. 但是需要被抓取对象有较为明显的纹理信息, 如边缘或角点.
文献[49]提出了一种基于事件的触觉图像传感器. 在黑色半球形的弹性体内表面嵌入白色标记点, 通过事件相机观测标记点的位移变化, 即可检测到指尖位置因受力而发生的形变, 能够以0.5 ms的响应速度进行检测, 处理之后可以检测到接触、滑动、位置、方向等信息. 但是这样的处理方式对于震动较为敏感, 容易出现误检测.
可以看出, 在当前滑动检测的应用中, 大部分论文都选择了将物体与透明板接触, 然后使用事件相机观测面积变化的方式. 但这种方法的问题就在于仍然要将事件流恢复成事件帧, 然后才能进行后续操作. 本节所述算法的总结如表3所示.
本节主要总结了基于事件相机的机械臂伺服控制研究. 尽管针对事件相机的机械臂伺服控制虽然已经有了一定的研究, 但很多方面仍处于起步阶段, 许多文献仅对于静态物体的抓取以及滑动检测有了较深入的研究, 而对于一些典型的视觉伺服场景, 同时也是事件相机最擅长的场景——运动物体的抓取, 尚未有深入研究, 这也是最能挖掘事件相机潜力的应用场景. 同时当前的研究也存在一定的缺陷, 如文献[41]中虽然实现了物体的抓取, 但仅能抓取静态的规则物体; 大部分文献中的方法仍然需要将事件流恢复为事件帧处理, 无法快速响应; 文献[45-46]使用的深度神经网络方法无法充分发挥事件流异步更新的优势.
总的来说, 当前基于事件相机的机械臂伺服面临的问题主要在于, 抓取应用仅适用于简单场景以及规则物体; 并且无法充分利用事件异步更新的优势. 前者使得事件相机的应用场景受到了极大的限制; 后者在很大程度上削弱了事件相机高时间分辨率的优势. 因此对基于事件相机的机械臂伺服的后续研究, 工作重点应尽可能减少复杂环境下, 静态场景的影响, 以及寻找异步处理事件的方法.
人形机器人是研制通用机器人的重要解决方案. 人形机器人能够自然地适应人类环境, 但是目前从各个层面, 如感知、规划、驱动、控制等, 现有能力均与人形机器人的预期有极大的差距. 事件相机基于生物视觉成像原理, 呈现出神经形态特性, 其特点符合对人形机器人的感知能力预期, 因此已有学者将其应用于人形机器人的感知和控制中. 本节系统介绍在此方向上, 事件相机的应用和发展.
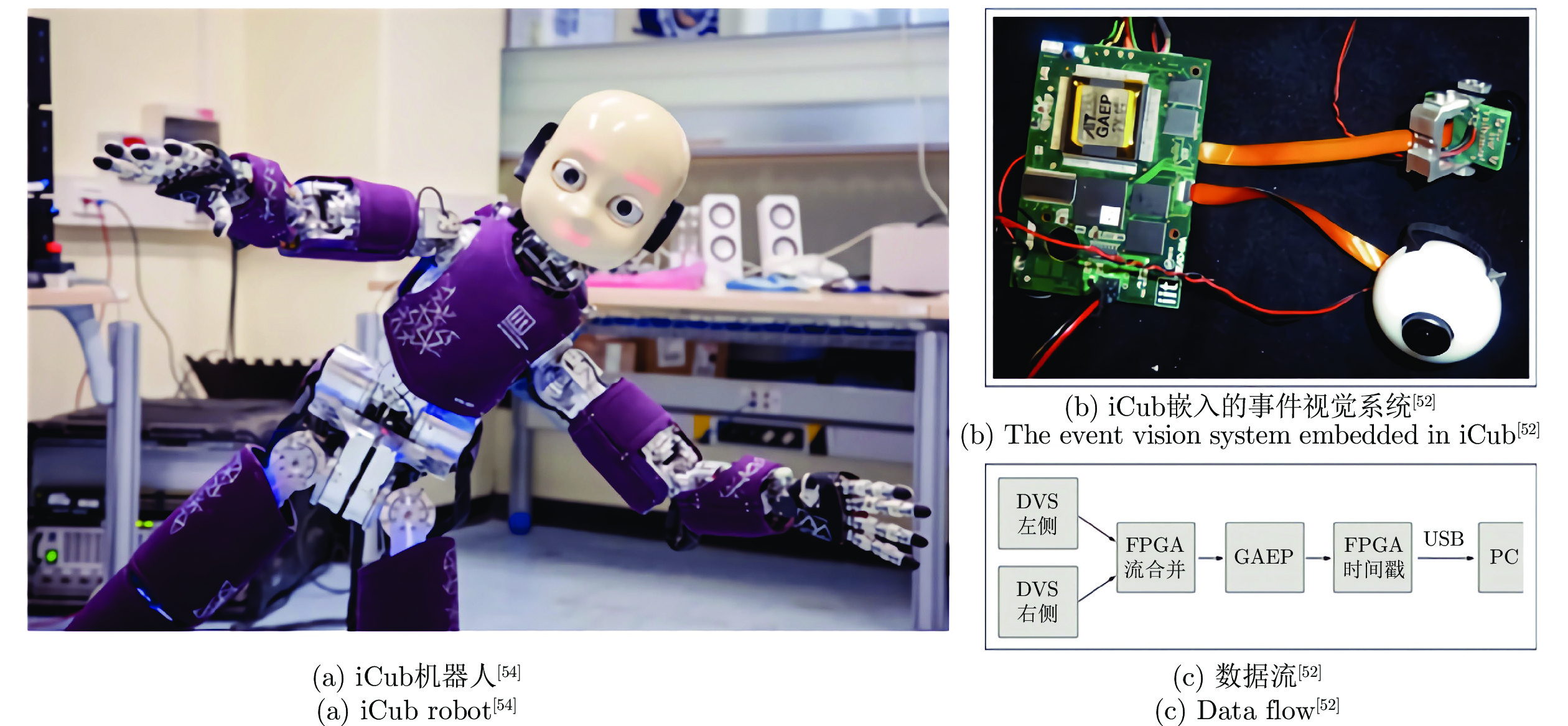
目前, 事件相机与人形机器人结合的研究, 大都是依托人形机器人iCub展开的. iCub是由意大利技术研究院(Italian Institute of Technology, IIT)建造的一个通用机器人开发平台, 无需任何特殊设备即可在任何实验室中工作, 可用于研究小型人形机器人的爬行、行走、视觉、触摸、人工智能、认知、操纵、学习等课题. iCub共具有53个自由度, 囊括了摄像头、麦克风、力/扭矩传感器、全身皮肤、陀螺仪和加速度计以及每个关节中的编码器等传感器; 在软件层面, iCub设有ROS (Robot operating system)接口, 并使用YARP (Yet another robot platform)作为中间件. 传统帧相机在数据的传输、储存和处理过程中需要消耗大量的计算资源, 难以满足iCub自主控制的低功耗、低延迟需求; 而事件相机由于其高时间分辨率、低延迟、低功耗、高动态范围等特点, 有助于iCub实现自主计算, 进而实现iCub自主控制.
为了实现事件相机与iCub的结合, IIT机器人事件驱动感知团队(Event-driven Perception for Robotics, EDPR)在iCub的眼球上嵌入了一套事件视觉系统[50–52], 同时将帧相机重新布置在iCub的头顶作为色彩等视觉信息的补充. 如图11所示, 事件视觉系统由两个DVS事件相机或ATIS事件相机、一个通用地址事件处理器以及一块FPGA芯片组成. 随着研究的逐步深入, 他们在YARP框架下开发了基于事件驱动的软件库[53], 这使得事件相机可以与包括iCub在内的基于YARP的机器人一起使用[54]. 该软件库可以不依赖iCub单独使用, 库中包含了光流、聚类追踪、角点检测、圆检测、粒子滤波、相机标定、预处理、可视化等功能模块, 并提供了示例程序及数据集.
基于在iCub上嵌入的事件视觉系统, 学者们在圆检测、角点检测、机器视觉注意力机制等方面开展了大量研究. 在圆检测方面, Wiesmann等[55]在桌面静置小球, 通过转动iCub的头部或眼球, 使小球与iCub产生相对运动, 进而产生边缘事件, 然后对事件聚类, 实现图像分割; 接着采用Hough圆变换检测出圆形, 精确识别出小球. 针对复杂背景下的圆检测问题, Glover等[56]提出了一种基于光流的定向Hough圆变换算法, 即利用光流信息估计圆心的运动方向, 只在该方向上开展Hough圆检测.
在角点检测方面, Vasco等[48]提出了事件驱动的e-Harris算法. e-Harris算法为每个异步事件创建一个局部检测窗口, 充分利用累计的事件在局部检测窗口应用Harris算法计算角点响应值. Vasco等通过转动iCub的头部及眼球扫描静置物体, 检测到了对应的角点事件, 验证了算法的有效性. 但是当事件相机与目标均在运动时, 会产生大量背景事件, 这使得跟踪或识别目标物体的运动变得更加困难. 因此需要将由目标自身运动所产生的目标角点事件, 与由事件相机运动所产生的背景角点事件进行区分. 在文献[57]中, Vasco等通过聚类追踪e-Harris检测到的角点, 并估计角点的运动速度; 同时根据iCub的关节运动, 应用支持向量机和径向基函数核开展有监督学习. 最终实现了背景角点事件与目标角点事件的区分, 且精度高达90%以上.
计算机视觉中的注意力机制具有广泛的应用, 这种机制能够忽略无关信息而关注重点信息, 进而节约有限的计算资源. Rea等[58]利用事件视觉系统, 为iCub开发了一套低延迟的人工注意力系统, 可以快速计算出需要聚焦的位置. 实验结果表明, 相比于基于帧相机的人工注意力系统, 事件驱动人工注意力系统的延迟要低两个数量级, 所占用CPU资源也要低近乎一个数量级. 在高动态场景中, 事件驱动的人工注意力系统可以准确识别出视野中需要聚焦的点, 而基于帧相机的人工注意力系统完全无法进行识别. Iacono等[59]将原型对象注意力模型与嵌入iCub人形平台上的神经形态事件驱动相机配合使用, 为机器人提供了低延迟、计算效率高的注意力系统.
此外, 基于iCub及其嵌入事件视觉系统, 结合机器学习技术, 还有许多有意义的研究项目. 例如Iacono等[51]将深度学习应用于iCub上的事件相机开展目标检测; Monforte等[50]采用长短期记忆人工神经网络开展轨迹预测等.
基于在iCub上嵌入的事件视觉系统, 可以实现驱动iCub的头部及眼球关节实现凝视追踪、深度估计等复杂操作. Glover等[56]利用基于光流的定向Hough圆变换检测算法识别小球的空间位置, 并驱动iCub转动眼球及头部, 实现对小球的实时凝视跟踪. 在大多数情况下, 定向Hough圆变换都能取得很好的检测效果. 但是由于Hough圆变换需要固定检测窗口, 当场景中有多个以不同速度移动的物体时, 事件发生率就会有很大波动, 最佳检测阈值将针对不同的对象而变化很大, 并且还会随时间而变化; 当相机追踪球体时, 若相对运动很小, 则可能丢失追踪目标. 为了解决上述问题, Glover等[60]又提出了一种粒子滤波算法, 展现出了更卓越的鲁棒性.
在深度估计方面, iCub可以通过驱动双目运动, 使其视线聚焦, 进而通过双目之间的相对姿态获得深度信息[61]. 但帧相机存在延迟高、鲁棒性差等问题, 目标快速运动时算法甚至会失效. 针对该问题, Vasco等[62]用基于事件驱动的视差调谐双目Gabor滤波器得到双目视差, 然后驱动眼动使视差收敛, 进而估计出深度信息. 这一改进使得延迟从帧相机的1 s降低至事件相机的200 ms, 且降低了对光照等环境条件的要求, 实现了更好的鲁棒性.
在iCub上同时安装麦克风与事件视觉系统, 还可实现多信息融合. Akolkar等[63]在iCub的头部安装麦克风, 首先利用iCub上的事件视觉系统检测视觉空间中的物体“碰撞”信息. 基于视觉检测到的“碰撞”事件, 可能是真实碰撞, 也可能是假碰撞, 如两个物体在视觉空间中相互遮挡. 真实碰撞通常会产生声音, 因此发生真实碰撞时麦克风可以检测到声音事件. 当通过视觉与听觉同时检测到碰撞事件时, 即可认为视觉空间中发生了真实碰撞. 该基于视听信息融合的碰撞检测算法在iCub检测人拍掌的场景中得到了验证.
综上, 相比于传统帧相机, 事件相机在iCub上的应用, 以耗费更少的计算资源降低了系统的延迟, 提高了iCub在不同光照强度、复杂背景条件、高动态场景下的自主控制能力, 但目前的研究仍较为基础, 主要是驱动iCub的头部和眼球进行凝视追踪, 更进一步的应用还有待进一步挖掘, 如抓取、接球等更为复杂的操作.
事件相机的离散、异步的数据特点与脉冲神经网络的输入需求自然的契合, 因此将它们结合, 产生了一系列感知和控制的新方法. 本节重点介绍事件相机与脉冲神经网络结合的感知和控制工作, 侧重算法和网络的设计.
第2.3节中提到, 脉冲神经网络(SNN)采用脉冲神经元为基本单位, 由前馈型、递归型以及混合型3种拓扑结构, 而且可以在极低的功耗下工作. 脉冲神经元从神经科学角度出发进行建模, 现有的模型包括HH (Hodgkin-huxley)模型、LIF (Leaky integrate and fire)模型、SRM (Spike response model)模型等. 脉冲神经网络的训练方式包括有监督学习(如SpikeProp、Multi-SpikeProp、Hebbian、ReSuMe、Chronotron、SPAN、SWAT、Tempotron等)、基于STDP (Spike-timing-dependent plasticity)的无监督学习、强化学习等. 事件相机以事件流的形式输出, 这与脉冲神经网络的输入十分契合, 因此选择脉冲神经网络搭配事件相机工作具有相当优势.
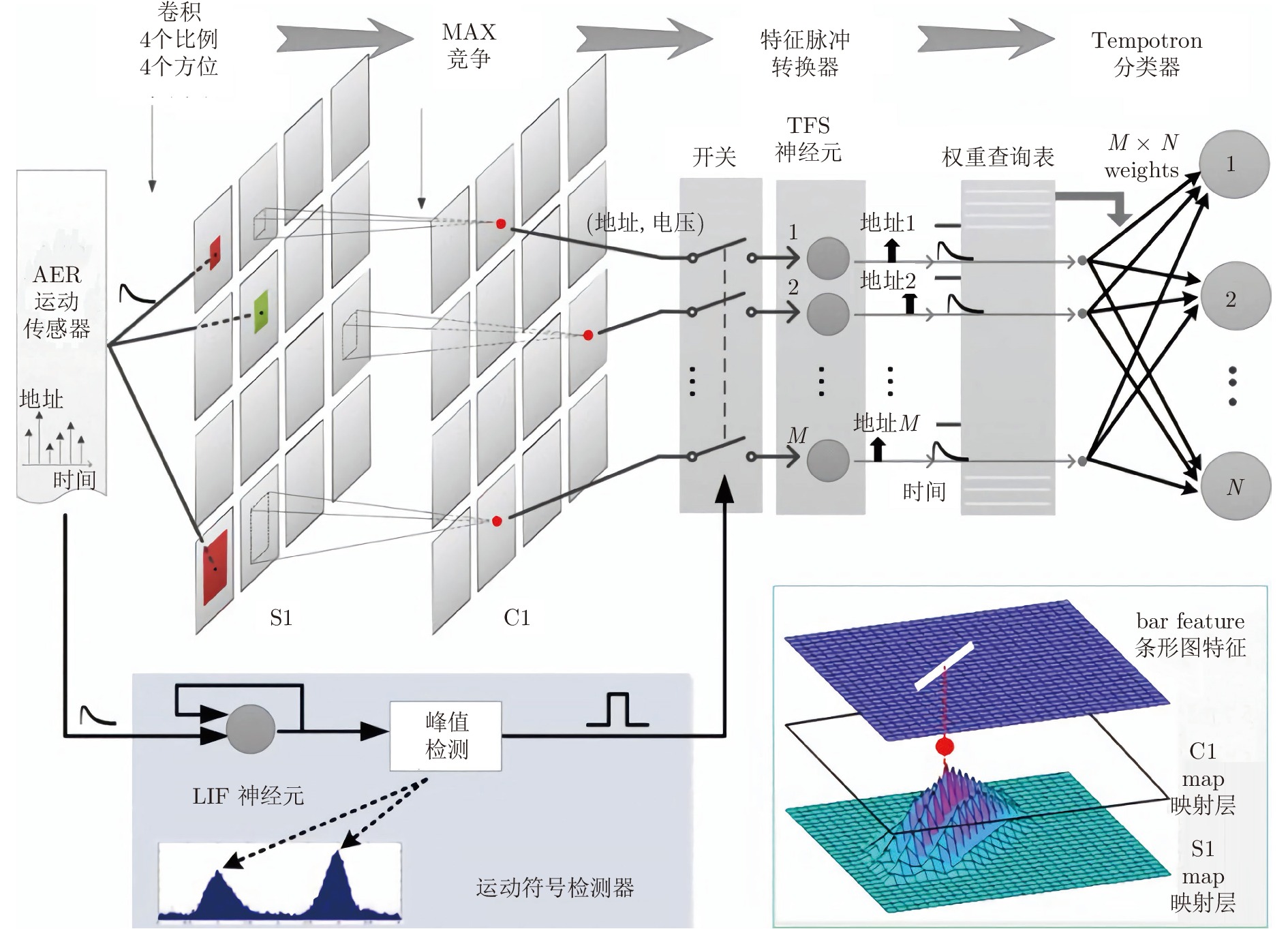
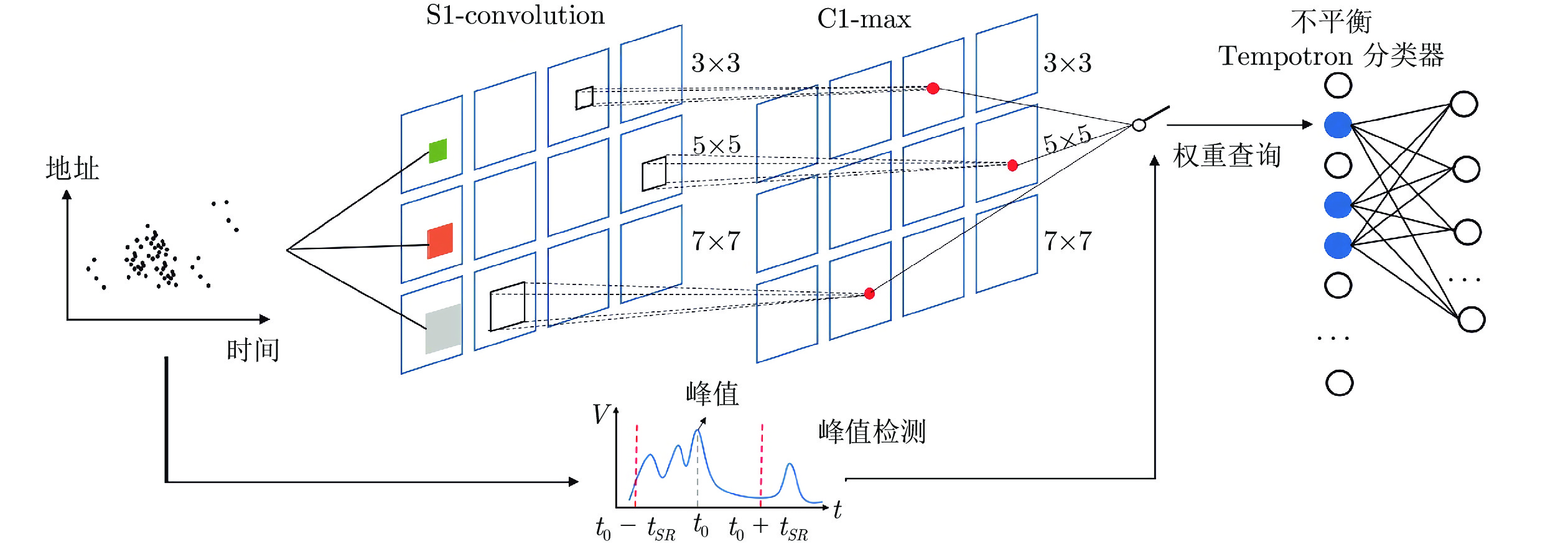
结合事件相机和SNN的识别研究工作较多. Zhao等[64-65]开发了一种基于事件的前馈分类系统, 该系统采用基于地址事件的Tempotron分类器实现分类. 如图12所示, 系统由卷积、竞争、特征脉冲转换器、运动符号检测器和Tempotron分类器构成. 事件相机所产生的每个地址事件都会先由Gabor滤波器滤波, 然后与领域事件竞争, 获胜者才能进入图12所示的C1特征层. 同时, 地址事件会传递到运动符号检测器(由LIF脉冲神经元和峰值检测单元组成)当中, 当LIF脉冲神经元的输出超过峰值时, 将产生脉冲, 进而导通图12中的开关, 此时可以将C1特征层中胜出的单元导入到特征脉冲转换器中, 由特征脉冲转换器将每个特征编码为时域脉冲. 最终由Tempotron分类器实现分类. Tempotron分类器由LIF脉冲神经元所构成, 是一类有监督学习算法. 上述分类器在基于事件相机的人体姿态识别、卡牌识别、数字识别等方面能取得较好效果.
Zhao等在文献[66]中, 对前述前馈分类系统结构进行简化, 取消了特征脉冲转换器和运动符号检测器, 同时由LIF脉冲神经元构建S1层. 对地址事件, 在采用Gabor滤波器滤波后, 经S1层、竞争之后, 直接由Tempotron分类器进行分类. 对该系统在MNIST-DVS数据集上进行测试, 准确性达到88.14%. Nan等[67]提出了一个基于事件的层次结构模型, 该模型由特征提取层和SNN组成. 特征提取层包括Gabor滤波、池化、事件时间表面特征提取等操作. SNN采用Tempotron算法训练, 人脸识别的精度可以达到92.5%.
Shen等[68]应用DVS128事件相机和SNN的结合, 开发了篮球比赛中的自动得分检测系统, 识别准确率高达91%. 地址事件处理框架如图13所示, 主要由特征提取器、峰值检测器和不平衡Tempotron分类器组成. 事件相机输出的地址事件先经Gabor滤波, 然后在S1层和C1层分别完成卷积和竞争; 峰值检测器由LIF脉冲神经元构成, 当神经元达到阈值后即输出脉冲, 此时将C1层提取的数据传输到Tempotron分类器处理.
值得注意的是, 上述结合事件相机和SNN的识别算法结构具有很大的相似性, 决策端均是采用仅包含输入层与输出层的两层脉冲神经网络. Tempotron是一个二层网络学习算法, 对这样的两层脉冲神经网络的训练是有效的, 但是无法扩展到多层脉冲神经网络. Massa等[69]使用DvsGesture数据集训练深度神经网络, 通过将训练后的深度神经网络转换为脉冲神经网络, 并在Loihi上实现, 可以实现实时手势识别, 精度高达89.65%. Camunas-Mesa等[70-71]在Spartan6 FPGA上实现了一个4层卷积脉冲神经网络, 可以实现扑克牌花色识别. 该卷积脉冲神经网络中共包含4个卷积层、两个采样层以及一个决策层, 卷积模块基于LIF模型实现, 模型参数由图像驱动的卷积神经网络映射而来[72]. 在测试中, 他们使用DVS相机在1 s内拍摄了40张扑克牌, 可以达到97.5%的识别率.
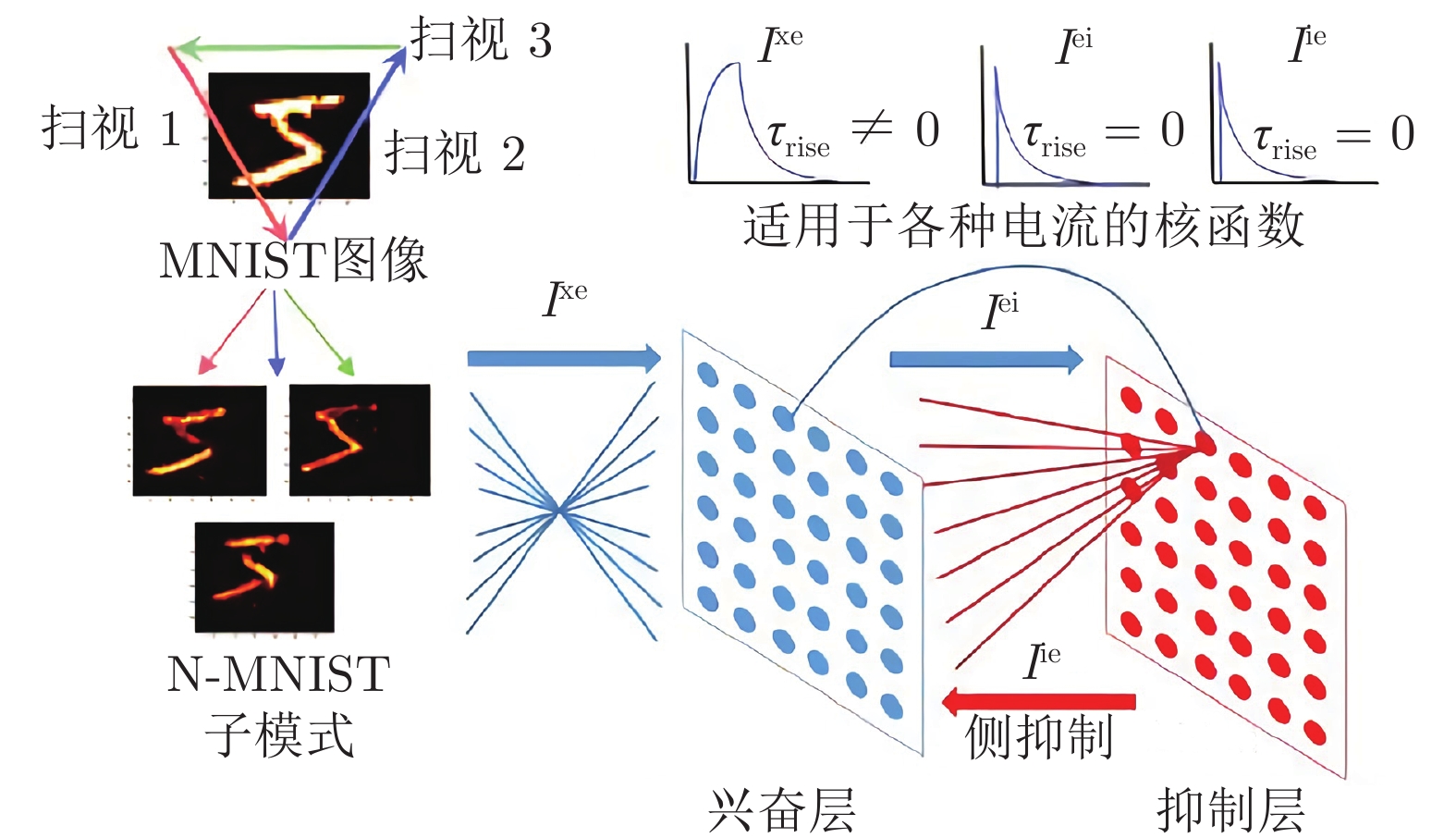
在SNN无监督学习方面, STDP是一种常用方法. Diehl等[73]提出了一种两层架构的脉冲神经网络结构, 第1层为28×28的输入层, 维度与输入数据相同; 第2层为处理层, 又可细分为兴奋层和抑制层, 两层由同等数量的兴奋性神经元和抑制性神经元组成. 输入层与兴奋层之间全连接; 每个兴奋性神经元一对一地连接到抑制性神经元(如图14中兴奋层左侧的射线), 同时抑制性神经元会投射到所有兴奋性神经元(如图14中抑制层左侧的射线). 对该网络采用STDP算法进行训练, 在MNIST数据集上可以达到95%的精度. 但是Diehl等[73]在预处理MNIST数据集时没有采用事件相机的数据格式. Iyer等[74]采用N-MNIST数据集(N-MNIST数据集为采用DVS事件相机记录的MNIST数据集)重新测试了Diehl等[73]提出的网络, 精度可以达到80.63%.
SNN与事件相机的结合, 不仅可用于识别工作, 还能进一步助力机电伺服、运动检测与追踪等. Cheng等[75]将DVS事件相机、SpiNNaker平台以及机电伺服模块集成到由脉冲神经网络控制的自主机器人当中, 实现守门任务. 机电伺服模块由伺服电机、长臂以及长臂末端的“守门员”组成. SpiNNaker平台上运行的脉冲神经网络仅有输入层和输出层, 不包含中间层, 共有8个输出神经元, 对应“守门员” 8个位置. 当球来临时, DVS相机捕捉到球的运动, 生成地址事件传递给单片机, 单片机将数据打包发送到SpiNNaker平台. 当某个输出神经元输出脉冲时, 由SpiNNaker平台向单片机发送数据包, 进而由单片机驱动机电伺服模块, 使“守门员”运动到指定位置拦截小球.
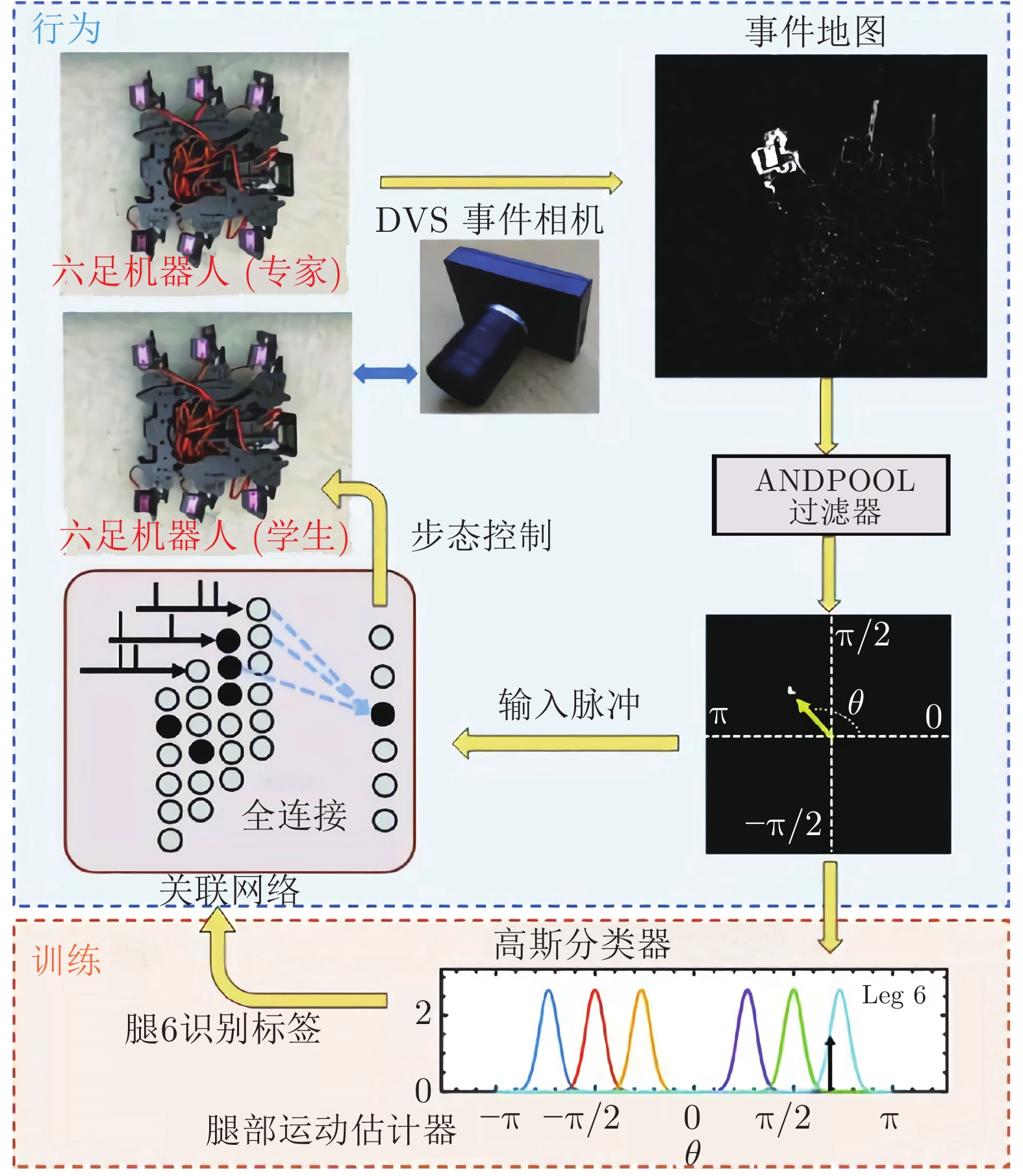
Ting等[76]提出了一种六足机器人的步态模仿解决方案, 该方案采用基于CeleX5事件相机的前馈脉冲神经网络实现. 如图15所示, 在该方案中, Ting等[76]采用CeleX5事件相机观察“专家”的步态, 所产生的事件采用Andpool进行滤波, 然后采用两层脉冲神经网络处理, 实现“学生”步态与“专家”步态的同步控制. 脉冲神经网络输出层有6个神经元, 对应“学生”的6条腿; 输入层与输出层全连接. Youssef等[77]在鳗鱼型水下机器人Envirobot头部安装双目DVS事件相机, 采用LIF脉冲神经网络处理事件数据, 产生Envirobot躯干关节控制信号, 驱动Envirobot向探测到的目标游动.
Blum等[78]在神经形态芯片ROLLS上部署SNN, 采用DVS事件相机作(像素为128×128)为敏感器, 采用Parallella并行计算平台进行实时计算, 实现了PushBot无人小车的避撞控制. 神经网络的输出分为3个簇, 每簇16个神经元, 分别输出信号控制PushBot左转、右转以及前进, 3个方向的速度与被激活的输出神经元的数目相关. 在进行避撞控制时, 将DVS视图的下半部分用于障碍探测, 每个4 × 64的像素阵列连接一个输入神经元, 共32个神经元构成输入层, 输入层与前进簇抑制连接; 像素阵列左右两侧连接的输入神经元分别与左转、右转簇神经元采用激活连接, 左转与右转簇之间有抑制连接. 同时为了在没有障碍物的情形下驱动PushBot持续前进, 在前进簇神经元旁边设置了8个神经元, 与前进簇激活连接. PushBot通过DVS视图的上半部分探测目标, 每个2×64的像素阵列连接一个输入神经元, 共64个神经元构成输入层, 用于指引PushBot的前进目标方向.
此外, Renner等[79]基于DAVIS 240C事件相机和在Loihi上实现的递归脉冲神经网络, 实现了用于选择性关注和跟踪的事件驱动视觉和处理系统. Gehrig等[80]使用卷积脉冲神经网络估计了一个旋转运动的DAVIS240C事件相机三自由度角速度. 该卷积脉冲神经网络由5个卷积层、一个全局平均池化层以及一个全连接层组成, 其神经元采用SRM模型, 采用一阶优化方法训练.
除了无人机、机械臂和人形机器人, 事件相机也在其余类型的机电系统中有典型的应用. 如铅笔倒立控制等小车的追踪控制等. Conradt等[13, 81]采用由两部DVS事件相机和一个由两台伺服电机驱动的工作台, 实现了铅笔倒立平衡控制, 如图16所示. 两部DVS相机分别安装在平台X、Y两个方向上, 当铅笔倾斜时会可以分别获得两个方向上的地址事件, 进而分别实现平面线检测; 基于两个相机平面线检测的结果可以对铅笔进行三维线估计, 进而采用PD控制律驱动两部伺服电机, 最终实现了铅笔倒立平衡控制.
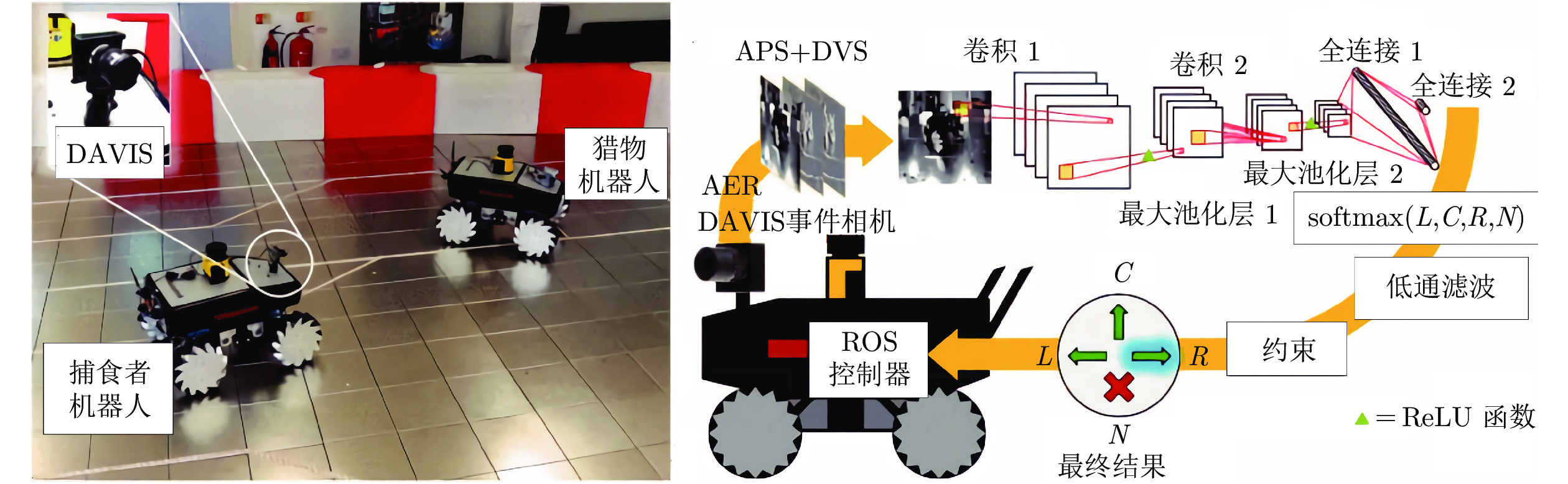
在机器人控制方面, Moeys等[82]在Summit XL小车上安装DAVIS相机, 结合卷积神经网络, 实现对另一部Summit XL机器人的追踪. DAVIS相机可以同时输出地址事件和帧图像, 在预处理数据时每记录5000个地址事件就合成一张直方图, 合成直方图和帧图像作为卷积神经网络的输入. 网络结构为4C5-R-2S-4C5-R-2S-40F-R-4F, 4个输出分别是左转、右转、前进、消失, 追踪的准确度可以达到80%, 如图17所示. 在守门机器人驱动方面, 除了Cheng等[75]采用的将事件相机与SNN结合的算法, Delbruck等[83-84]还采用聚类算法识别和追踪小球的运动, 应用小球的速度和位置信息驱动伺服系统到达指定位置实现拦截.
Mueller等[85-86]提出了一种基于事件反馈的控制方法, 直接利用事件相机高时间分辨率、低延迟、低功耗、高动态范围的特点. 在实验中, 基于PD控制律和控制实验LQR (Linear quadratic regulater)调节器控制伺服电机驱动滚筒装置, 取得了较好的效果. Delbruck等[87]将DAVIS安装在槽车轨道的上帝视角, 当小车行驶时会产生事件, 这些事件可用于计算小车的加减速指令. 与人才操控的小车比赛, 基于DAVIS控制的小车能赢超过80%的比赛. Censi[88]在将原始事件数据采用线性滤波器滤波后, 研究了在事件相机反馈下的图像空间中的航向调节问题. 在线性系统整定方面, Singh等[89-91]应用事件相机的成像机制, 研究了连续线性时不变系统的二次稳定问题, 并在考虑测量噪声和测量信号离散的基础上设计了一种
事件相机在机电系统控制、环境识别与感知等方面具有极其广泛的应用, 相比于传统帧相机具有显著优势. 但将事件相机应用于识别与控制仍具有相当的挑战性, 譬如事件相机与脉冲神经网络的结合, 结构简单的网络易于训练但性能有限、而复杂网络的训练仍面临许多挑战; 结合事件相机的机电系统控制能显著提高系统的响应时间, 但新算法、新应用的开发仍需要深入研究.
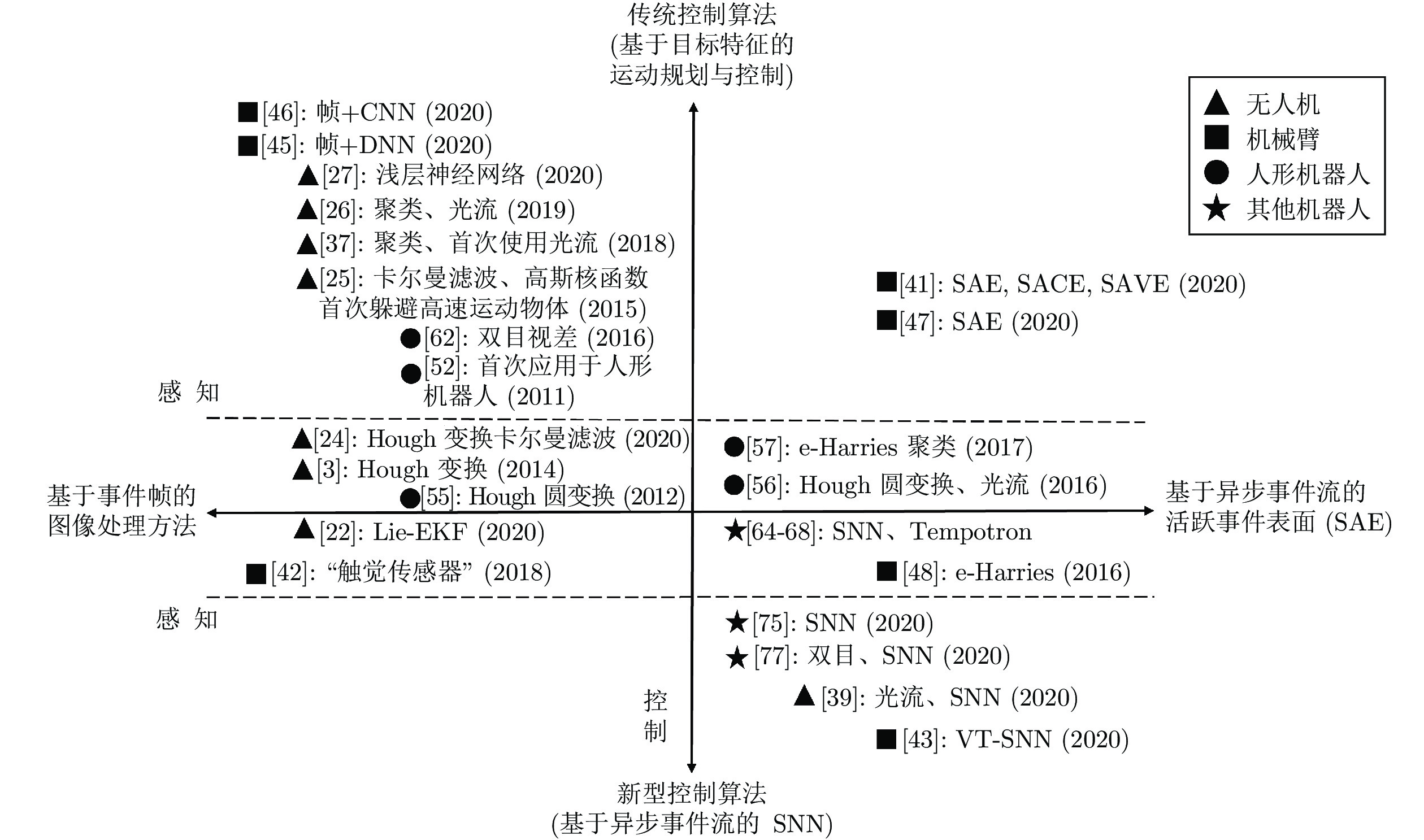
事件相机与传统帧相机具有完全不同的工作机理, 具有数据量小、延迟低、动态范围高的特点, 因此将其置于机器人控制回路的闭环之中, 降低了测量、感知环节的延迟和数据量. 本文介绍了事件相机在无人机、机械臂、人形机器人等机器人系统中感知与控制的最新工作以及结合事件相机发展的新型控制算法, 技术发展脉络如图18所示, 图中横轴对应感知部分技术, 主要分为两大类: 一类(负横轴)先将事件相机采集的事件流数据对应成事件帧, 可尝试利用图像处理方法解决高速、高动态的应用场景问题. 另一类(正横轴)则根据事件相机采集数据自身特点直接设计新的事件流处理算法, 如基于异步事件流的活跃事件表面; 纵轴对应控制部分技术也分为两大类, 包括基于目标特征的运动规划与控制的传统算法(正纵轴), 以及充分考虑事件相机异步事件流特性的新型控制算法(负纵轴), 代表如SNN. 目前的研究根据上述技术分类组合可得到四条主流技术路线, 但是仍处于起步阶段, 主要存在的问题和发展方向有:
1) 视觉系统是机器人完成跟踪、抓取以及操作的关键基础, 而目前基于事件的视觉算法难以满足复杂环境下物体检测、跟踪与识别任务的要求. 例如当事件相机随机器人(如无人机、机械臂末端等)运动时, 输出的数据包括静止物体、运动物体产生的事件以及噪声事件, 从这些杂乱的事件数据中提取可用的目标信息是一大难点. 因此, 有必要进一步研究基于事件的运动分割技术以及基于机器/深度学习的目标检测与识别技术.
2) 目前在结合事件相机的机器人控制系统中, 视觉模块的延迟占比较高, 为进一步提升机器人操控的灵活性, 有必要根据事件相机特性设计更加快速高效的视觉模块. 例如, 可深挖事件流的异步特性并开发异步、超低延迟的特征检测与跟踪算法. 另外, 随着近年来事件相机分辨率的不断提升, 在计算效率方面视觉算法将面临更多挑战.
3) 目前在结合事件相机的机器人控制系统中, 控制器设计较为简单. 由于事件相机对光照变化较为敏感, 可能产生包含大量噪声事件的视觉信号, 而这些噪声的不确定性将很容易影响控制系统的性能, 因此有必要进一步研究新型的控制算法, 以实现基于事件相机的机器人稳定控制. 同时, 也需要研究噪声事件的产生机理, 这将有助于去噪算法的设计以及控制器分析.
4) 目前结合事件相机的机器人控制系统仍依赖传统机器人的控制流程, 如首先进行视觉特征的检测跟踪, 再进行期望轨迹规划与轨迹跟踪等, 并没有发挥出事件相机神经形态与高时间分辨率的特点. 理论上, 事件相机与脉冲神经网络具有自然的适配性, 研究有效的脉冲神经网络训练方法, 以实现端到端的控制指令生成, 具有一定的研究意义.
综上, 在未来的研究中, 建议充分利用事件相机输出的异步事件流的特性, 设计低延迟、低计算量的视觉处理算法, 研究新型的控制算法以及研究事件相机与脉冲神经网络结合的方法以实现机器人的灵活与智能操控.