 0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

基于分子指纹和拓扑指数的工质临界温度理论预测
引 言
临界温度(Tc)作为工质能维持液相的最高温度,是建立状态方程的基础,也可以用于计算工质其他物性如焓、熵、比热容、黏度、热导率等。同时,临界温度是超临界萃取过程中的重要参数。因此,获取工质准确的临界温度具有重要的科学意义和工程价值[1-5]。实验是获取临界温度最有效的方式。然而由于实验研究代价高昂、复杂性高,无法仅依靠实验手段获得工质的临界温度。因此,有必要提出一种能够准确预测工质临界温度的理论模型。
临界温度的预测方法主要包括经验公式法、状态方程法和定量结构-性质关系法(quantitative structure-property relationship, QSPR)。经验公式法采用一些易于测量的参数,如沸点、密度等,建立相应的关联式得到临界温度。Reid等[6]最早提出了临界温度与沸点的关联式Tc=1.5Tb。周传光等[7]基于沸点与对比密度,提出了部分化合物临界温度的关联式,平均偏差为1.35%。王新红等[8]以沸点、对比密度、相对分子质量为参数,提出了一个新的有机物临界温度计算模型,平均偏差为2.36%。经验公式法形式简单、计算精度较高,但缺乏理论基础。状态方程法可以基于pVT数据,拟合获得工质状态方程中相应参数,而后反推得到物质的临界温度。例如,Kontogeorgis等[9]采用状态方程法估算了6种烷烃的Tc,绝对平均偏差均在2%以内。Hsieh等[10]依据同样的思路,首先获得Peng-Robinson(PR)状态方程的参数,进而得到392种纯物质的临界温度,平均偏差为5.4%。状态方程法需要已知工质pVT数据,且计算流程复杂,适用于密度数据较为丰富的物质。定量结构-性质关系法(QSPR)根据分子结构-物质性质之间的构效关系,对物质相关性质进行建模和预测。基团贡献法是QSPR中最常用的一种方法,包括经典的Lydersen法[11]、Joback法[12]等。这些方法假设分子性质为各基团贡献的线性加和,而基团贡献度在不同分子中保持不变。这种线性加和的方法使用较方便,但没有考虑不同基团的位置信息,导致该方法不能有效区分同分异构体。尽管后续的一些方法如Constantinou-Gani法[13]、Marrero-Pardillo法[14]等,通过引入多级基团和键贡献在一定程度上缓解了上述缺陷,但适用范围依然有限。综合分析以上方法可知,现有模型无法对常见工质进行准确估算,须采用新的思路,以实现对包括同分异构体工质在内的常见工质临界温度的精准预测。
分子结构描述符[如分子指纹(molecular fingerprints, MF)[15]、拓扑指数(topological index, TI)[16]等]作为一种将分子结构编码为结构化数据的方法,可以将一种物质与其他物质进行明确区分。将分子描述符的概念引入QSPR模型,有望解决工质同分异构体的区分问题。在实际使用中,分子描述符通常与机器学习方法(machine learning, ML)相结合,以构建物质特性预测模型[17-19]。近年来,随着计算机性能的不断提高,有学者将分子描述符和机器学习应用于工质物性[20-24]的预测,预测效果良好。
本研究受上述分子描述符工作的启发,首先以分子指纹表征分子结构,并借助机器学习算法建立16种临界温度的QSPR预测模型。此外,为了进一步提升本文模型的预测精度,本研究还将分子指纹与拓扑指数相结合,得到新的MF+TI-ML模型(以分子指纹和拓扑指数表达分子结构,结合机器学习算法建立模型),以期取得良好的预测效果。
1 方 法
1.1 数据库的搭建
本研究中工质的临界温度实验数据取自物理性质设计研究所(DIPPR®801)[25]及相关文献[26]。根据实验数据不确定度对其进行筛选后,获得了155种工质的Tc (本文所涉及工质的详细信息,参见文末附录)。搭建的数据库中,临界温度的范围分布在190.56~583.00 K。数据库中工质可分为五种:烷烃、烯烃、卤代烷烃、卤代烯烃、醚类。为提升模型泛化能力,从每种类型工质中选取其中70%的数据点进入训练集,剩下的30%作为测试集。训练集用于建立工质临界温度的模型,测试集用于评估模型的预测性能。
1.2 分子指纹的生成
通过ChemDraw程序获得工质分子的线性输入规范(simplified molecular input line entry system, SMILES),随后利用在线转换工具ChemDes [27]将SMILES字符串转换为相同长度的二进制位串(即分子指纹)。为了研究不同长度/类型的指纹对QSPR模型性能的影响,本文选择了计算四种分子指纹,包括两种Key型指纹:MACCS(166位)和Pubchem(881位),一种Path型指纹:Extended(1024位)和一种Circular型指纹:Morgan(2048位)。
1.3 回归算法的选择
本文使用了四种机器学习算法,包括支持向量回归(support vector regression, SVR)、回归树(regression tree, RT)、随机森林(random forest, RF)以及多层感知机(multi-layer perceptron, MLP)。
支持向量回归通过核技巧将非线性数据映射到高维空间中,将非线性关系转换为线性的形式,其精度取决于参数的选择,例如核函数、宽度系数γ、不敏感损失系数ε、惩罚系数C等[28]。在本文中,将采用5折交叉验证和网格搜索确定参数的最佳组合。决策树(decision tree, DT)利用多节点的树结构来描述各变量与目标之间的非线性关系,回归树是决策树的回归版本。由于树模型具有较高的方差,可能导致结果不稳定,基于树模型的集成学习算法随机森林相对树模型有较大的改进[29],在物性预测中应用较多。人工神经网络(artificial neural network, ANN)模拟神经系统的结构,通过不断调整神经元间的权重和偏差,使整个网络能更好地拟合数据[30-34]。多层感知机(MLP)是一种前馈神经网络,通过相互连接的人工神经元和复杂的拓扑结构来模拟非线性关系[35]。本文利用深度学习库Keras搭建了具有双隐层的MLP,并通过试错法确定了神经元数、激活函数、学习率的最优组合。
1.4 评估指标的选择
本文选用均方根偏差(RMSE)、绝对平均偏差(AAD)、决定系数(R2)评估模型的预测性能, 相关定义式如下。
式中,m表示样本个数;
2 实验结果与讨论
2.1 模型的建立与评估
将四种分子指纹(MACCS、Pubchem、Extended、Morgan)分别用作四种机器学习算法(SVR、RT、RF、MLP)的输入特征,得到16种临界温度的QSPR模型。各模型在测试集中的预测性能(以绝对平均偏差AAD为评价指标)如图1所示。
图1
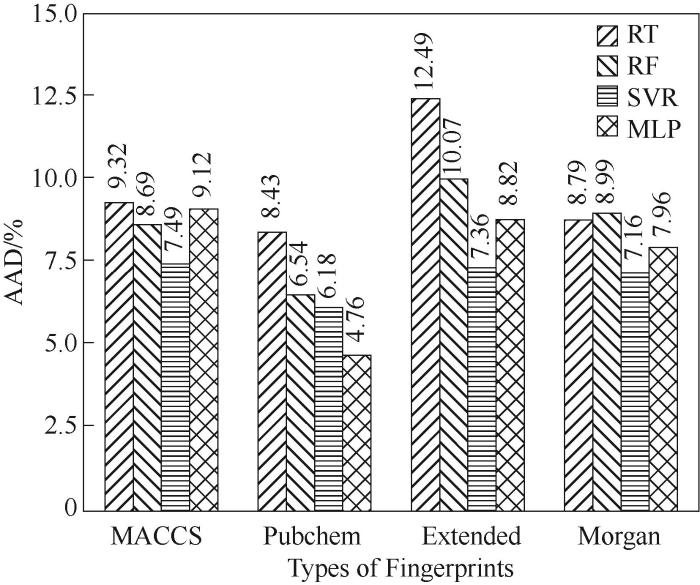
图1 以不同指纹为输入的各QSPR模型的预测精度
Fig.1 Prediction accuracy of QSPR models with different fingerprints as inputs
从图1可以看出,以MACCS指纹为输入特征的模型预测性能较差,其中表现最好的MACCS-SVR(以MACCS指纹为输入,结合SVR建立的模型)在测试集中的绝对平均偏差(AAD)也仅达到了7.49%。其原因是MACCS指纹长度过短,包含的结构信息有限,导致工质某些结构片段并不包含于MACCS指纹中。因此,以短位数的MACCS为输入,模型预测精度并不高。
Extended指纹结合SVR算法建立的模型在测试集的AAD为7.36%。这是因为在ChemDes中,Extended指纹最大路径长度默认设置为5 (即结构片段包含的最大键数为5),导致许多线性路径大于5的分子具有相同的Extended指纹。由于缺乏碳链长于5的工质Tc的实验数据,如果提高路径最大长度,特征维度会急剧增加,从而造成模型过拟合。因此目前来看Path型指纹不是建立工质QSPR模型的最优选择。
Circular型指纹Morgan作为一种立体型指纹长度最长,包含的结构信息也最多,因此可以有效地表征分子结构,进而有效区分工质同分异构体。综合来看,虽然以Morgan指纹为输入特征的模型预测性能要比上述两种类型的指纹好,但仍不理想。其原因可能是位数过长导致了模型过拟合,因而Morgan指纹也不适用于搭建样本数较少的QSPR模型。
Pubchem-MLP模型(Pubchem指纹结合MLP算法建立的模型)在训练集、测试集的AAD分别为1.12%、4.76%。相比其他分子指纹而言,基于Pubchem指纹的QSPR模型预测表现最好。这说明Pubchem指纹可以合理表征工质的结构信息,从而在有限的训练样本中有效建立分子结构与临界温度之间的构效关系,准确预测工质临界温度。针对本文所研究的155种工质,Pubchem-MLP模型在工质临界温度实验值和计算值的比较如图2所示。
图2

图2 Pubchem-MLP模型在工质临界温度实验值和计算值的比较
Fig.2 Comparison between experimental and caculated values of Pubchem-MLP model
从结果来看,四种ML算法建立的模型对工质临界温度的综合预测效果排序如下:SVR > MLP > RF > RT。SVR模型预测精度最高且表现稳定。基于集成算法RF的模型相比RT,在预测精度上有了明显的提高,但和SVR仍有较大差距。
2.2 模型的优化
Pubchem指纹可以很好地表达工质结构。但由于该类型指纹需要预先指定子结构,可能会造成工质中极少数同分异构体(如顺反异构体)无法区分的问题。因此本文考虑在分子指纹的基础上添加拓扑指数,以“分子指纹+拓扑指数”(MF+TI)作为新型分子结构描述符,采用效果较好的SVR和MLP算法,以期完全解决区分工质中同分异构体的问题。
拓扑指数是一种量化分子结构的指标,通过对表征分子图的矩阵执行数值运算获得。这里引入拓扑指数(molecular topological index, MTI′),在MTI′的基础上添加几何校正数(geometric modification, GM)区分工质中的同分异构体,拓扑指数S的计算公式[16]如下:
式中, Dv、 DV、 Dw分别表示工质结构的价矩阵、顶点权重矩阵、邻接矩阵;N表示分子的原子总数; v 表示价向量; MGF是用以区分异构体的对角矩阵。文末附录给出了拓扑指数的具体计算流程和案例。
采用新型描述符后两种模型的回归和预测性能如图3、图4所示。可以看出引入拓扑指数S后,模型的预测精度明显提升。Pubchem+TI-SVR模型(新型描述符输入SVR算法建立的模型)在测试集的决定系数R2提高到0.8426,而Pubchem+TI-MLP模型(新型描述符输入MLP算法建立的模型)在测试集的AAD降低至3.99%,R2提高到0.9143。对比图2、图4可以发现,相比Pubchem-MLP模型,Pubchem+TI-MLP模型预测性能明显提高。这表明引入拓扑指数得到的新型描述符可以很好地解决区分工质中同分异构体的问题,提升模型的预测性能。
图3

图3 Pubchem+TI-SVR模型在工质临界温度实验值和计算值的比较
Fig.3 Comparison between experimental and caculated values of Pubchem+TI-SVR model
图4

图4 Pubchem+TI-MLP模型在工质临界温度实验值和计算值的比较
Fig.4 Comparison between experimental and caculated values of Pubchem+TI-MLP model
表1给出了本文搭建的Pubchem+TI-MLP模型在工质各数据集、各物质体系预测值和实验值的AAD。从表中可以看出,新提出模型对烷烃类工质临界温度的回归和预测都具有很高的精度,分别达到了0.90%和1.65%。模型对烯烃类工质的拟合回归效果很好,但预测效果较差。醚类、卤代烷烃类、卤代烯烃类工质的计算精度相比上述两类更低。从整个数据集来看,五种类型工质的绝对平均偏差均低于3%,取得了很好的计算效果。
表1 本文模型在各数据集、各物质体系的AAD
Table 1
| 集合 | AAD/% | ||||
|---|---|---|---|---|---|
| 烷烃类 | 烯烃类 | 卤代烷烃类 | 卤代烯烃类 | 醚类 | |
| 训练集 | 0.90 | 0.40 | 1.96 | 1.87 | 1.77 |
| 测试集 | 1.65 | 4.37 | 4.81 | 4.79 | 4.75 |
| 总数据集 | 1.14 | 1.45 | 2.78 | 2.85 | 2.76 |
图5给出了155种工质的相对偏差(ARD)分布情况,相对偏差的定义如
其中ARD<3%的工质有113种,占比72.9%,ARD>9%的工质仅7种,最大偏差为15.98%。
图5

图5 工质临界温度ARD分布情况
Fig.5 Distribution of ARD for Tc of working fluids
2.3 模型的对比
将新提出模型的计算结果与现有其他方法进行对比,用于对比的经典方法列在表2中,模型的比较结果如表3所示。从表3中可以看出,本文模型的计算精度最高,Lydersen法和Joback法次之,C-G法精度最低。基于沸点实验值的Joback法计算工质Tc精度很高。但必须注意的是,并非所有工质都具有准确的沸点数据。当使用估算的沸点值(
表2 现有预测临界温度的方法
Table 2
| 作者 | 模型表达式 |
|---|---|
| Klincewicz等[36] | |
| Lydersen[11] | |
| Joback等[12] | |
| Constantinou等[13] |
表3 提出模型与以往方法计算效果的对比
Table 3
| 方法 | AAD/% | RMSE | Err<5% | Err>10% |
|---|---|---|---|---|
| Lydersen | 1.16 | 8.84 | 116 | 1 |
| Joback( | 1.22 | 9.11 | 114 | 2 |
| Joback( | 7.63 | 46.63 | 69 | 24 |
| C-G(1st) | 5.99 | 39.05 | 84 | 23 |
| C-G(2nd) | 5.73 | 38.15 | 81 | 21 |
| Klincewicz-Reid | 2.85 | 17.88 | 102 | 5 |
| 本文模型 | 1.12 | 7.36 | 119 | 0 |
为了进一步验证本文新提出模型和C-G法在区分同分异构体性能上的差异,表4给出了C-G二级基团贡献法和本文模型在区分各类同分异构体(包括顺反异构、位置异构和碳架异构)上的案例,其中
表4 C-G法和本文模型对同分异构体的区分案例
Table 4
| 异构现象 | 工质 | Texp/K | ||
|---|---|---|---|---|
顺反 异构体 | (Z)-1,2-二氯乙烯 | 507.25 | 518.97 | 558.45 |
| (E)-1,2-二氯乙烯 | 535.80 | 533.20 | 558.45 | |
| (Z)- 1,2,3,3,3-五氟丙烯 | 379.25 | 376.13 | 435.30 | |
| (E)- 1,2,3,3,3-五氟丙烯 | 386.75 | 376.21 | 435.30 | |
| (Z)-2-丁烯 | 435.50 | 437.40 | 430.03 | |
| (E)-2-丁烯 | 428.60 | 426.33 | 430.03 | |
位置 异构体 | 1-氯丙烷 | 503.50 | 502.02 | 504.95 |
| 2-氯丙烷 | 482.40 | 484.07 | 480.82 | |
| 1,1,1,2,2,3-六氟丙烷 | 403.35 | 411.48 | 404.06 | |
| 1,1,1,2,3,3-六氟丙烷 | 412.45 | 411.01 | 494.52 | |
| 1,1,1,3,3,3-六氟丙烷 | 398.10 | 410.77 | 386.51 | |
碳架 异构体 | 2,2,3-三甲基戊烷 | 563.50 | 573.40 | 566.24 |
| 2,2,4-三甲基戊烷 | 543.80 | 545.11 | 545.16 | |
| 2,3,3-三甲基戊烷 | 573.50 | 573.06 | 594.42 | |
| 2,3,4-三甲基戊烷 | 566.40 | 567.14 | 588.60 |
从表4中可以看出,本文模型对于各类同分异构体的临界温度都取得了良好的预测精度。而C-G法对于所有顺反异构体的临界温度预测结果完全一致,这表明C-G法无法区分顺反异构体。
表5给出了本文模型和C-G二级基团贡献法对155种工质中三类同分异构体计算结果的统计结果。从表5中可以看出,C-G法在碳架异构体的计算表现良好,37种碳架异构体临界温度的AAD为1.87%,但是由于不能辨别顺反异构,对10种顺反异构体的计算精度较差。在位置异构体临界温度的计算上,C-G法的精度也较低。而本文提出的Pubchem+TI-MLP模型不仅可以有效区分工质中存在的各类同分异构体,在计算精度上也远高于C-G法。本文模型对顺反异构体、位置异构体、碳架异构体临界温度计算值和实验值的AAD分别为2.35%、2.51%、0.87%。
表5 C-G法和本文模型计算同分异构体的统计结果
Table 5
| 异构现象 | 模型 | N | AAD/% | RMSE |
|---|---|---|---|---|
| 顺反异构 | 本文模型 | 10 | 2.35 | 12.89 |
| C-G(2nd) | 8.54 | 50.39 | ||
| 位置异构 | 本文模型 | 21 | 2.51 | 15.60 |
| C-G(2nd) | 5.65 | 36.09 | ||
| 碳架异构 | 本文模型 | 37 | 0.87 | 7.25 |
| C-G(2nd) | 1.87 | 14.21 |
3 结 论
本文基于分子指纹和拓扑指数,采用机器学习算法建立了工质临界温度的Pubchem+TI-MLP模型。将新模型应用于155种常见工质的临界温度预测中,取得了良好的计算精度,针对测试集预测的绝对平均偏差为3.99%。通过与经典模型的比较可以得出,新模型不仅可以有效区分工质中各类同分异构体,其计算精度相比现有模型也更高。通过对模型进一步分析还可看出,对指纹长度的选择,必须综合考虑样本总数以及数据集包含的物质种类。在指纹类型的选择上,Key型指纹Pubchem虽然在本文工质的临界温度预测上表现最好,但其自身不能区分少数顺反异构体,需要引入拓扑指数以提高区分能力。长度更长的Path型和Circular型指纹对同分异构体的区分能力更好,但不适用于样本数少的数据集。随着以后工质实验数据的不断补充,可考虑使用更长的分子指纹搭建性能更加优异的QSPR模型。

- 我用了一个很复杂的图,帮你们解释下“23版最新北大核心目录有效期问题”。
- 重磅!CSSCI来源期刊(2023-2024版)最新期刊目录看点分析!全网首发!
- CSSCI官方早就公布了最新南核目录,有心的人已经拿到并且投入使用!附南核目录新增期刊!
- 北大核心期刊目录换届,我们应该熟知的10个知识点。
- 注意,最新期刊论文格式标准已发布,论文写作规则发生重大变化!文字版GB/T 7713.2—2022 学术论文编写规则
- 盘点那些评职称超管用的资源,1,3和5已经“绝种”了
- 职称话题| 为什么党校更认可省市级党报?是否有什么说据?还有哪些机构认可党报?
- 《农业经济》论文投稿解析,难度指数四颗星,附好发选题!
- 期刊知识:学位论文完成后是否可以拆分成期刊论文发表?
- 号外!出书的人注意啦:近期专著书号有空缺!!

