0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

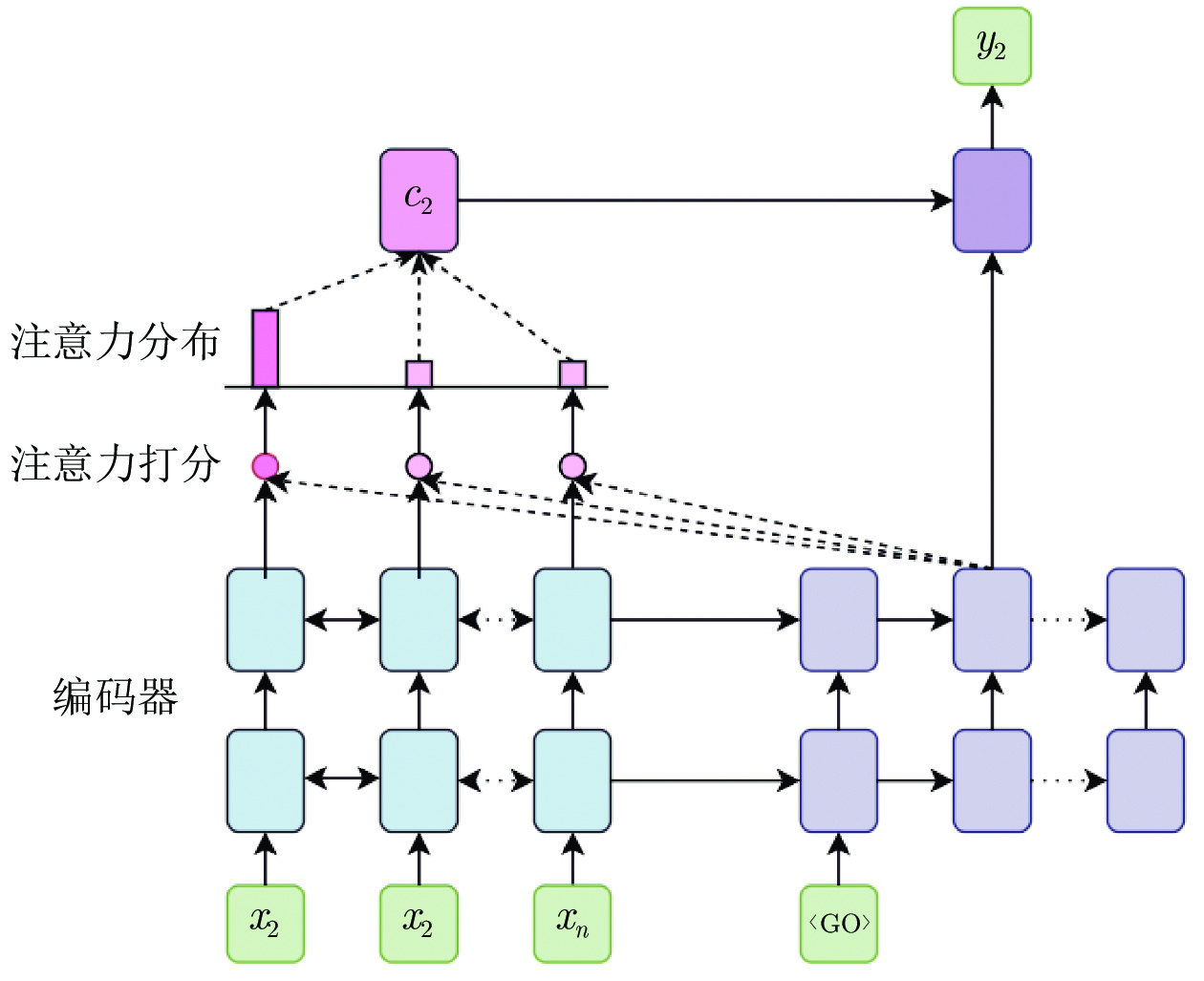
图 1 传统作用于最高层网络的注意力机制融入
Fig. 1 Model with traditional attention mechanism based on top-layer merge
自端到端的神经机器翻译(Neural machine translation)模型[1-2]提出以来, 神经机器翻译得到了飞速的发展. 基于注意力机制[2]的神经机器翻译模型提出之后, 更使得神经机器翻译在很多语言对上的翻译性能超越了传统的统计机器翻译(Statistical machine translation)[3], 成为自然语言处理领域的热点研究方向[4], 也因此促进了很多神经网络方法在其上的迁移与应用, 变分方法[5-6]即是其中一种重要方法. 变分方法已证明能够显著提升神经机器翻译的性能[7], 但是由于数据驱动特性, 其性能较依赖于平行语料的规模与质量, 只有当训练语料规模达到一定数量级时, 变分方法才会体现其优势. 然而, 在低资源语言对上, 不同程度的都面临平行语料缺乏的问题, 因此如何利用相对容易获取的单语语料、实现语料扩充成为应用变分方法的前提. 针对此问题, 本文采用能够同时利用平行语料和单语语料的半监督学习方式展开研究. 半监督神经机器翻译(Semi-supervised neural machine translation)主要通过两种方式对单语语料进行利用: 1)语料扩充−再训练: 利用小规模平行语料训练基础翻译模型, 在此模型基础上利用回译[8]等语料扩充方法对大规模单语语料进行翻译, 形成伪平行语料再次参与训练; 2)联合训练: 利用自编码[9-10] 等方法, 以平行语料和单语语料共同作为输入, 进行联合训练. 本文重点关注语料扩充后的变分方法应用, 因此采用语料扩充−再训练方式.
目前被较多采用的语料扩充方法为: 首先利用小规模平行语料训练基础翻译模型, 在此基础上通过回译将大规模单语语料翻译为伪平行语料, 进而组合两种语料进行再次训练. 因此, 基础翻译模型作为任务的起始点, 它的性能直接影响后续任务的执行质量. 传统提升基础翻译模型性能的手段限于使用深层神经网络和在解码端最高层网络应用注意力机制. 然而, 由于深层神经网络在应用于自然语言处理任务中时, 不同层次的神经网络侧重学习的特征不同: 低层网络倾向于学习词法和浅层句法特征, 高层网络则倾向于获取更好的句法结构特征和语义特征[11]. 因此, 很多研究者通过层级注意力机制, 利用神经网络每一层编码器产生的上下文表征指导解码. 层级注意力机制使高层网络的特征信息得以利用的同时, 也挖掘低层网络对输入序列的表征能力. 然而, 上述研究多采用层内融合方式实现层级注意力机制, 其基本方式为将
本文的创新点包括以下两个方面: 1)通过融入跨层注意力机制加强基础翻译模型的训练, 在增强的基础翻译模型上利用回译产生伪平行语料、增大数据规模, 使其达到能够有效应用变分方法的程度. 2)首次将变分信息瓶颈应用于神经机器翻译任务, 在生成的语料的基础上, 利用变分特性提升模型的性能, 同时针对生成语料中的噪声, 利用信息瓶颈的控制特性进行去除. 概括来说, 方法整体实现的是一种语料扩充−信息精炼与利用的过程, 并预期在融合该方法的神经机器翻译中取得翻译效果的提升. 在IWSLT和WMT等数据集上进行的实验结果表明, 本文提出的方法能显著提高翻译质量.
注意力机制的有效性得到证明之后, 迅速成为研究者们关注的热点. 很多研究者在神经网络的不同层次上应用注意力机制构建层级注意力模型, 在此基础上展开训练任务. Yang等[14]将网络划分为两个注意力层次, 第一个层次为“词注意”, 另一个层次为“句注意”, 每部分通过双向循环神经网络(Recurrent neural network)结合注意力机制实现文本分类. Pappas等[15]提出了一种用于学习文档结构的多语言分层注意力网络, 通过跨语言的共享编码器和注意力机制, 使用多任务学习和对齐的语义空间作为文本分类任务的输入, 显著提升分类效果. Zhang等[16]提出一种层次结构摘要方法, 使用分层结构的自我关注机制来创建句子和文档嵌入, 通过层次注意机制提供额外的信息源来获取更佳的特征表示, 从而更好地指导摘要的生成. Miculicich等[17]提出了一个分层关注模型, 将其作为另一个抽象层次集成在传统端到端的神经机器翻译结构中, 以结构化和动态的方式捕获上下文, 显著提升了结果的BLEU (Bilingual evaluation understudy)值. Zhang等[18]提出了一种深度关注模型, 模型基于低层网络上的注意力信息, 自动确定从相应的编码器层传递信息的阈值, 从而使词的分布式表示适合于高层注意力, 在多个数据集上验证了模型的有效性. 研究者们通过融入层级注意力机制到模型训练中, 在模型之上直接执行文本分类、摘要和翻译等任务, 与上述研究工作不同的是, 本文更关注于跨层次的注意力机制, 并期待将融入跨层注意力机制的基础翻译模型用于进一步任务.
如何在低资源场景下进行单语语料的扩充和利用一直是研究者们关注的热点问题之一. 早在2007年, Ueffing等[19]就提出了基于统计机器翻译的语料扩充方法: 利用直推学习来充分利用单语语料库. 他们使用训练好的翻译模型来翻译虚拟的源文本, 将其与译文配对, 形成一个伪平行语料库. 在此基础上, Bertoldi等[20]通过改进的网络结构进行训练, 整个过程循环迭代直至收敛, 取得了性能上的进一步提升. Klementiev等[21]提出了一种单语语料库短语翻译概率估计方法, 在一定程度上缓解了生成的伪平行语料中的重复问题. 与前文不同, Zhang等[22]使用检索技术直接从单语语料库中提取平行短语. 另一个重要的研究方向是将基于单语语料库的翻译视为一个解密问题, 将译文的生成过程等同于密文到明文的转换[23-24].
以上的单语语料扩充方法主要应用于统计机器翻译中. 随着深度学习的兴起, 神经机器翻译成为翻译任务的主流方法, 探索在低资源神经机器翻译场景下的语料扩充方法成为研究热点. Sennrich等[8]在神经机器翻译框架基础上提出了语料扩充方法. 他们利用具有网络结构普适性的两种方法来使用单语语料. 第1种方法是将单语句子与虚拟输入配对, 然后在固定编码器和注意力模型参数的情况下利用这些伪平行句对进行训练. 在第2种方法中, 他们首先在平行语料库上训练初步的神经机器翻译模型, 然后使用该模型翻译单语语料, 最后结合单语语料及其翻译构成伪平行语料, 第2种方法也称为回译. 回译可在不依赖于神经网络结构的情况下实现平行语料的构建, 因此广泛应用于半监督和无监督神经机器翻译中. Cheng等[25]提出一种半监督神经机器翻译模型, 通过将回译与自编码进行结合重构源与目标语言的伪平行语料, 取得了翻译性能上的提升. Skorokhodov等[26]提出了一种将知识从单独训练的语言模型转移到神经机器翻译系统的方法, 讨论了在缺乏平行语料和计算资源的情况下, 利用回译等方法提高翻译质量的几种技术. Artetxe等[27]利用共享编码器, 在两个解码器上分别应用回译与去噪进行联合训练, 实现了只依赖单语语料的非监督神经机器翻译. Lample等[28]提出了两个模型变体: 一个神经网络模型和一个基于短语的模型. 利用回译、语言模型去噪以及迭代反向翻译自动生成平行语料. Burlot等[29]对回译进行了系统研究, 并引入新的数据模拟模型实现语料扩充. 与上述研究工作不同的是, 本文同时关注于伪平行语料生成所依赖的基础翻译模型的训练. 在训练过程中, 不仅利用注意力机制关注高层网络中对句法结构和语义信息的利用, 同时也关注低层网络信息对高层网络信息的直接影响.
为了实现信息的压缩和去噪, Tishby等[30]提出基于互信息的信息瓶颈(Information bottleneck)方法. 深度神经网络得到广泛应用后, Alemi等[12]在传统信息瓶颈的基础上进行改进, 提出了适用于神经网络的变分信息瓶颈(Variational information bottleneck), 变分信息瓶颈利用深度神经网络来建模和训练, 通过在源和目标之间添加中间表征来进行信息过滤.
在神经机器翻译中, 尚未发现利用变分信息瓶颈进行噪声去除的相关研究工作, 但是一些基于变分的方法近期已经在神经机器翻译中得到应用, 有效提高了翻译性能. Zhang等[7]提出一个变分模型, 通过引入一个连续的潜在变量来显式地对源语句的底层语义建模并指导目标翻译的生成, 能够有效的提高翻译质量. Eikema等[31]提出一个双语句对的深层生成模型, 该模型从共享的潜在空间中共同生成源句和目标句, 通过变分推理和参数梯度化来完成训练, 在域内、混合域等机器翻译场景中证明了模型的有效性. Su等[32]基于变分递归神经网络, 提出了一种变分递归神经机器翻译模型, 利用变分自编码器将随机变量添加到解码器的隐藏状态中, 能够在不同的时间步长上进一步捕获依赖关系.
本节首先介绍传统基于注意力机制的基础翻译模型, 接着介绍了融入跨层注意力机制的基础翻译模型. 区别于传统的基础翻译模型, 本文通过融入跨层注意力机制, 除关注高层编码器产生的上下文表征向量之外, 也关注低层编码器产生的上下文表征向量对高层编码的直接影响. 最后介绍了变分信息瓶颈模型, 展示了利用该模型对回译方法生成的伪平行语料中的噪声进行去除的过程.
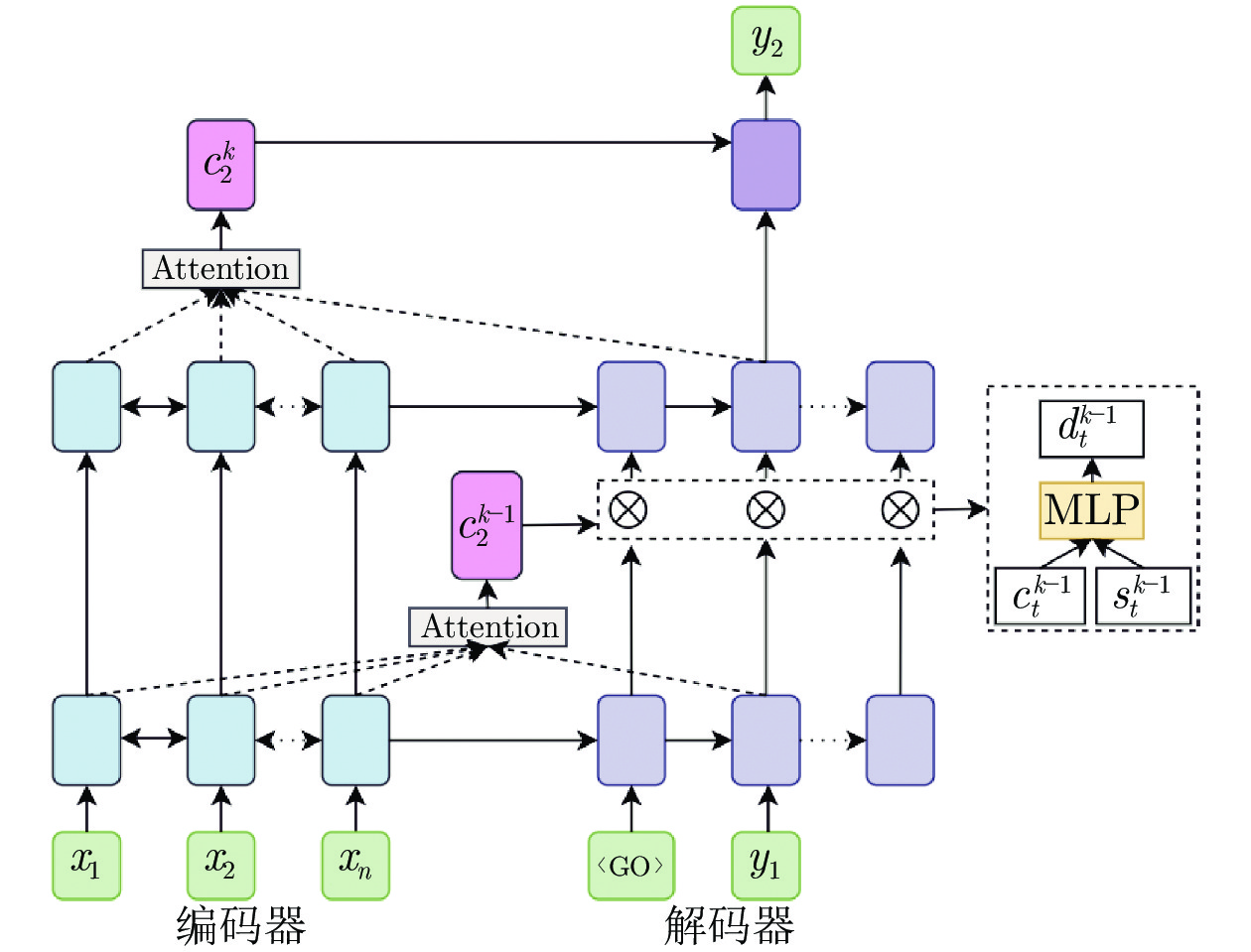
传统方法中, 最初通过在解码端最高层网络引入注意力机制进行基础翻译模型的训练. 如图1所示的2层编解码器结构中, 它通过在每个时间步长生成一个目标单词
| (1) |
其中,
| (2) |
其中,
| (3) |
其中,
| (4) |
其中,
| (5) |
通过在最高层网络引入注意力机制来改善语义表征、辅助基础翻译模型的训练, 能够有效地提升翻译性能, 但仅利用最高层信息的方式使得其他层次的词法和浅层句法等特征信息被忽略, 进而影响生成的伪平行语料质量. 针对此问题, 能够利用每层网络上下文表征的层级注意力机制得到关注, 成为众多翻译系统采用的基础方法. 这些系统往往采用层内融合方式的层级注意力机制, 如图2所示的编解码器结构中, 第
| (6) |
| (7) |
| (8) |
其中,
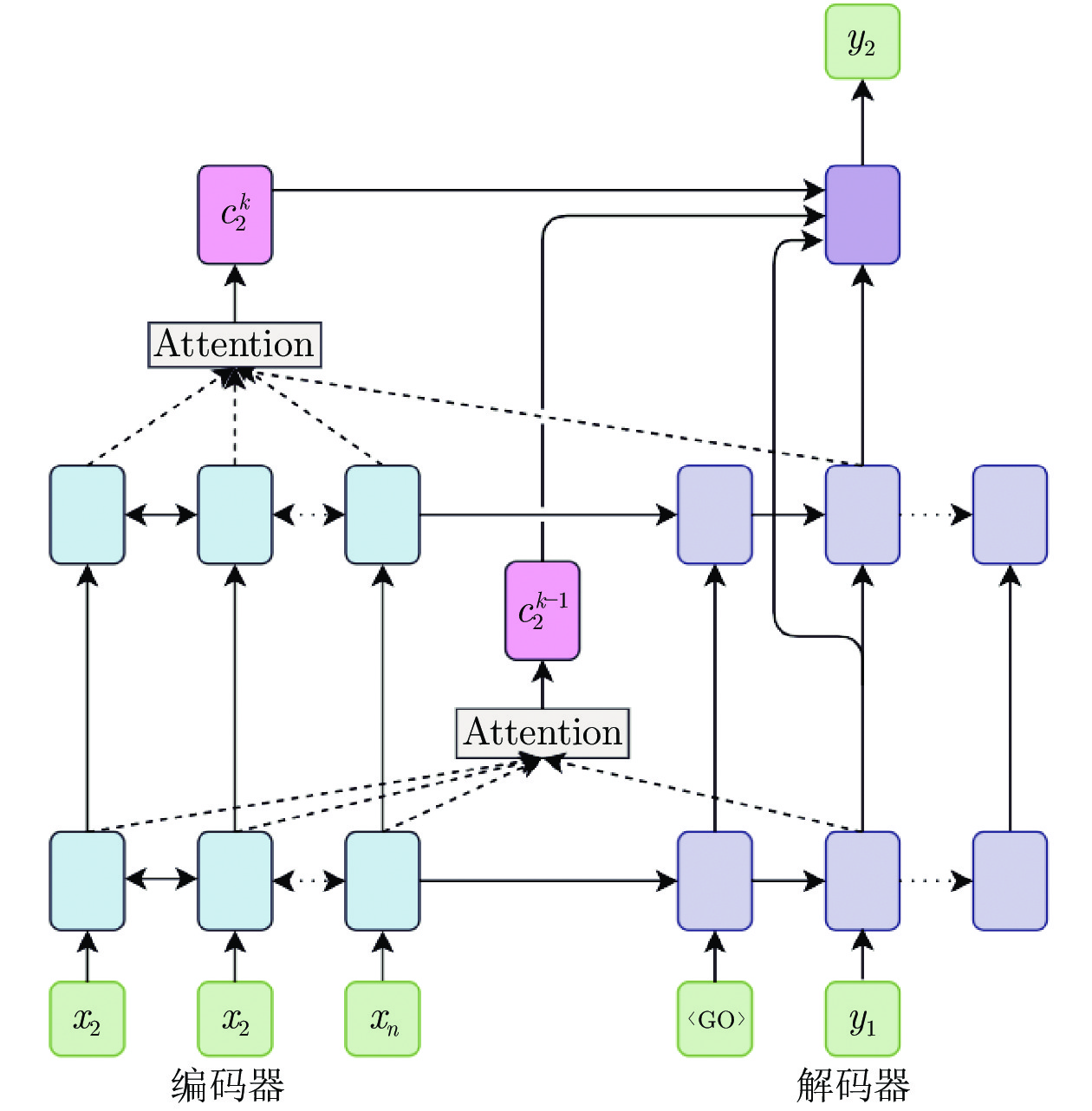
层内融合方式加强了低层表征利用, 但难以使低层表征跨越层次对高层表征产生直接影响. 因此, 本文设想利用跨层融合, 在利用低层表征的同时促进低层表征对高层表征的直接影响. 通过融入跨层注意力机制, 使各层特征信息得到更加充分的利用. 如图3所示, 模型通过注意力机制计算每一层的上下文向量
| (9) |
同样, 通过跨层拼接操作得到
| (10) |
| (11) |
在基础翻译模型的训练中, 通过融入不同层次的上下文向量来改善语义表征, 但也因此带来更多的噪声信息. 针对此问题, 本文通过在编解码结构中引入适用于神经网络的变分信息瓶颈方法来进行解决. 需要注意的是, 编解码结构中, 编码端的输入通过编码端隐状态隐式传递到解码端. 变分信息瓶颈要求在编码端输入与解码端最终输出之间的位置引入中间表征, 因此为了便于实现, 将变分信息瓶颈应用于解码端获取最终输出之前, 以纳入损失计算的方式进行模型训练, 其直接输入为解码端的隐状态, 以此种方式实现对编码端输入中噪声的过滤. 具体流程为: 在给定的
| (12) |
| (13) |
其中,
给定输入平行语料
| (14) |
其中,
| (15) |
本文引入信息瓶颈
| (16) |
同时加入约束, 目标为
| (17) |
其中,
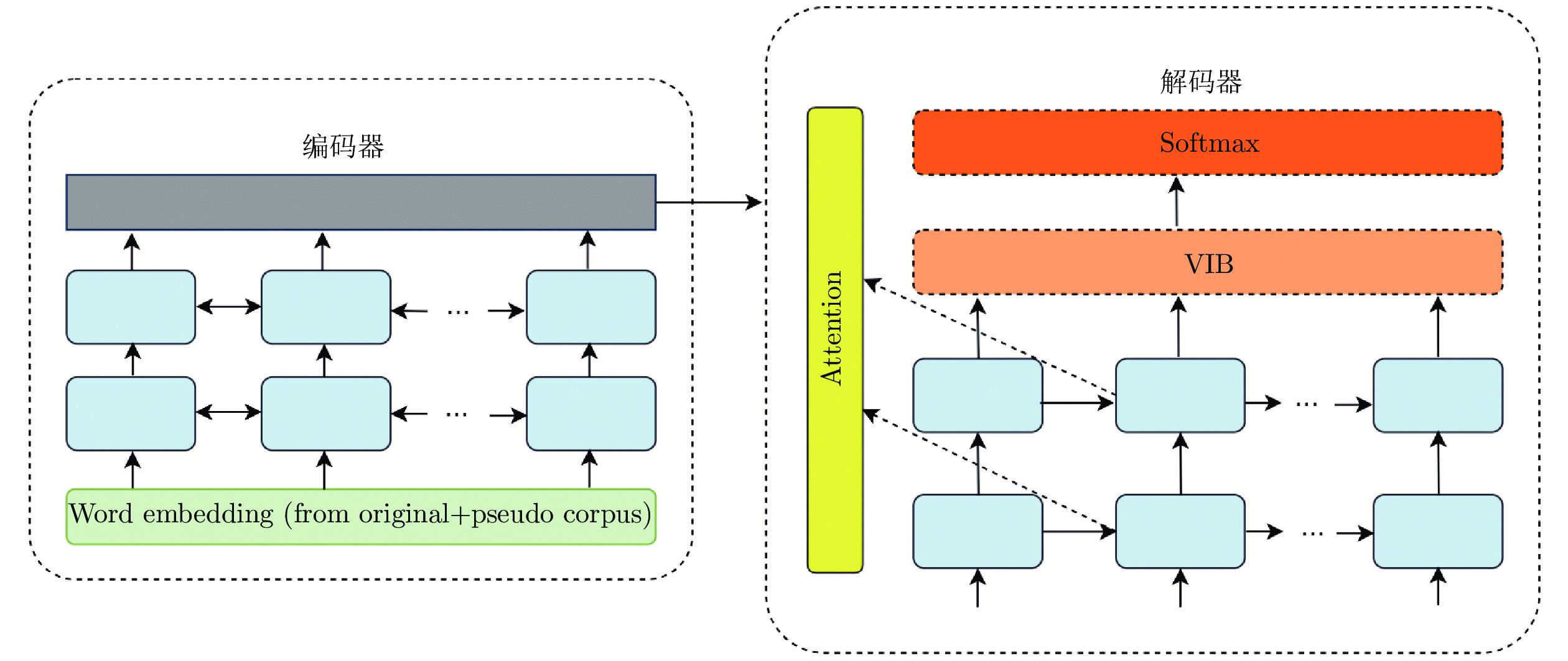
图4显示了引入了变分信息瓶颈后的模型结构, 同样地, 为了利用不同层次的上下文表征信息, 在变分信息瓶颈模型中也引入了跨层注意力机制. 模型的输入为平行语料和伪平行语料的组合. 以给定小规模平行语料
本文选择机器翻译领域的通用数据集作为平行语料来源, 表2显示了平行语料的构成情况. 为观察本文方法在不同规模数据集上的作用, 采用不同规模的数据集进行对比实验. 小规模训练语料中, 英−越、英−中和英−德平行语料均来自IWSLT15数据集, 本文选择tst2012作为验证集进行参数优化和模型选择, 选择tst2013作为测试集进行测试验证. 大规模训练来自WMT14数据集, 验证集和测试集分别采用newstest2012和newstest2013.
表3显示了单语语料的构成情况, 英−越和英−中翻译中, 英文和中文使用的单语语料来源于GIGAWORD数据集, 越南语方面为互联网爬取和人工校验结合处理后得到的1 M高质量语料. IWSLT和WMT上的英−德翻译任务中, 使用的单语语料来源于WMT14数据集的单语部分, 具体由Europarl v7、News Commentary和News Crawl 2011组合而成. 本文对语料进行标准化预处理, 包括词切分、过长句对过滤, 其中, 对英语、德语还进行了去停用词操作. 本文选择BPE作为基准系统, 源端和目标端词汇表大小均设置为30000.
本文选择以下模型作为基准系统:
1) RNNSearch模型: 编码器和解码器分别采用6层双向长短期记忆网络(Bi-directional long short-term memory, Bi-LSTM)和长短期记忆网络(Long short-term memory, LSTM)构建. 隐层神经元个数设置为1000, 词嵌入维度设置为620. 使用Adam算法[33]进行模型参数优化, dropout率设定为0.2, 批次大小设定为128. 使用集束宽度为4的集束搜索(Beam search)算法进行解码.
2) Transformer模型: 编码器和解码器分别采用默认的6层神经网络, 头数设置为8, 隐状态和词嵌入维度设置为512. 使用Adam算法进行模型参数优化, dropout率设定为0.1, 批次大小设置为4096. 测试阶段使用集束搜索算法进行解码, 集束宽度为4.
利用IWSLT15数据集进行的小规模平行语料实验中, 本文参考了Sennrich等[34]关于低资源环境下优化神经机器翻译效果的设置, 包括层正则化和激进dropout.
本文选择大小写不敏感的BLEU值[35]作为评价指标, 评价脚本采用大小写不敏感的multi-bleu.perl. 为了从更多角度评价译文质量, 本文另外采用RIBES进行辅助评测. RIBES (Rank-based intuitive bilingual evaluation score)是另一种评测机器翻译性能的方法[36], 与BLEU评测不同的是, RIBES评测方法侧重于关注译文的词序是否正确.
本节首先通过机器翻译评价指标对提出的模型进行量化评价, 接着通过可视化的角度对模型效果进行了分析.
本文提出的方法和基准系统在不同翻译方向上的BLEU值如表4所示, 需要注意的是, 为了应用变分信息瓶颈、实现对源端噪声信息进行去除, 最终翻译方向与基础翻译模型方向相反(具体原因见第2.3节中对表1的描述). 表4中RNNSearch和Transformer为分别在基线系统上, 利用基础模型进行单语语料回译, 接着将获得的组合语料再次进行训练后得到的BLEU值. 表4同时展示了消融不同模块后的BLEU值变化, 其中CA、VIB分别表示跨层注意力、变分信息瓶颈模块.
通过实验结果可以观察到, 本文提出的融入跨层注意力和变分信息瓶颈方法在所有翻译方向上均取得了性能提升. 以在IWSLT15数据集上的德→英翻译为例, 相较Transformer基准系统, 融入两种方法后提升了0.69个BLEU值. 同时根据德英翻译任务结果可以观察到, BLEU值的提升幅度随着语料规模的上升而减小. 出现该结果的一个可能原因是在低资源环境下, 跨层注意力的使用能够挖掘更多的表征信息、使低层表征对高层表征的影响更为直接. 而在资源丰富的环境下, 平行语料规模提升所引入的信息与跨层注意力所挖掘信息在一定程度上有所重合. 另一个可能原因是相对于资源丰富环境, 低资源环境产生的伪平行语料占组合语料的比例更大, 变分信息瓶颈进行了更多的噪声去除操作.
上述实验证明了本文所提方法可以融入不同框架使用, 同时适用于资源丰富环境和低资源环境, 尤其在平行语料匮乏的低资源环境下, 能够通过充分利用神经网络各层信息来加大信息量, 同时通过去噪改善信息的质量, 在某种程度上与增加高质量平行语料具有同类效果.
为了观察单独或共同融入跨层注意力和变分信息瓶颈后在不同翻译方向上BLEU值的提升效果, 本文采用消融方式单独或组合使用两种方法并在表4中报告了实验结果. 以IWSLT15数据集上的英→越翻译为例, 相对于Transformer基准系统, 单独使用跨层注意力在测试集上获得了0.33个BLEU值的提升, 而单独使用变分信息瓶颈提高了0.76个BLEU值, 结合使用两种方法后则提高了0.97个BLEU值.
消融实验结果表明, 本文所提两种方法既可以独立地应用于翻译框架中, 也可以结合使用. 单独融入时均能带来一定的翻译性能上的提升, 而结合使用两种方法后, 则获得了进一步的提升. 因此我们认为, 结合使用跨层注意力和变分信息瓶颈能够在有效加大信息量的同时提升翻译质量.
此外, 将本文所提方法与Zhang等[38]提出的基于回译的半监督联合训练方法进行了对比实验. 该方法以联合学习方式, 在每步迭代中首先利用回译得到伪平行语料, 将其投入训练后通过极大似然估计交替优化源到目标和目标到源的翻译模型, 实现了翻译性能的较大提升. 为保持标准一致, 实验语料和训练参数均沿用该文设置: 平行语料为WMT14英德训练集(4.5 M), 单语语料截取自News Crawl 2012 (8 M); 选取RNNSearch为基础模型, 隐层神经元个数设置为1024, 词嵌入维度设置为256, 批次大小设定为128. 本文方法中, 同时使用了跨层注意力和变分信息瓶颈机制.
通过表5的实验结果可以观察到, 相较于对比方法, 本文所提方法在英−德和德−英方向上取得了1.13和0.67个BLEU值的提升.
本文利用RIBES方法对IWSLT数据集中2个语言对评测结果如表6所示, 其中基准模型为实现层内注意力机制的Transformer模型. 从表中可以观察到, 相较基准系统, 融入跨层注意力机制后在所有翻译任务上均取得了RIBES值的提升, 其中英→越翻译任务上, 提升了最高的0.69个RIBES值, 在此基础上使用变分信息瓶颈模型, 则获得了1.45个RIBES值的提升. 因此实验结果表明, 相较基准系统, 融入跨层注意力机制可完善译文的句子结构信息, 起到了词序优化的作用. 在此基础上结合使用变分信息瓶颈方法, 生成的译文则具有更佳的词序.
为了更直观地验证融入跨层注意力机制是否更能促进高层网络的句法结构信息完善, 同时验证融入变分信息瓶颈是否具有噪声信息去除的作用, 本文在中−英翻译结果中随机选取了300句译文, 并对译文质量进行分析.
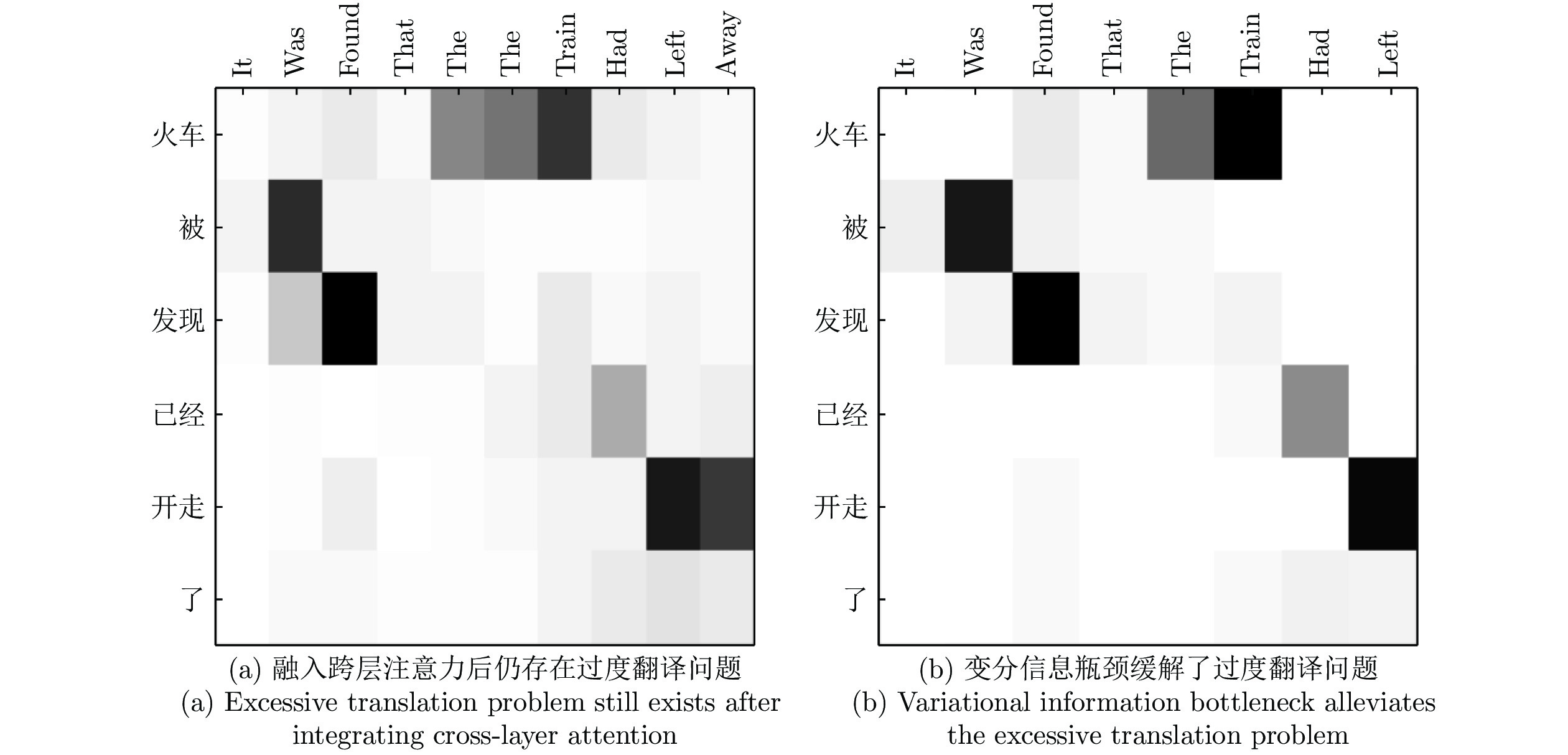
表7展示了一个翻译实例(TA、CA、CA+VIB分别表示传统注意力、跨层注意力、跨层注意力加变分信息瓶颈方法): 给定中文源句“火车被发现已经开走了”, 作为基准系统的传统注意力模型产生的译文为“Found that the train had gone”, 句中缺少形式主语造成句子结构并不完整. 而融入跨层注意力机制后的译文为“It was found that the the train had left away”, 缺失的形式主语被补全, 句子结构得到了完善. 通过对全部300句译文进行分析发现, 融入跨层注意力机制后产生的译文, 其结构完整性普遍增强. 因此, 实验证明, 使用跨层注意力机制, 在学习到低层网络所产生的词法和浅层句法特征同时, 对学习高层网络所产生的句法结构特征也具有促进作用, 有助于提升句子结构的完整性.
神经机器翻译中, 源端语料中的噪声信息会导致过度翻译问题. 在本文讨论的低资源场景下, 利用回译构建伪平行语料实现语料扩充, 但由于在过程中缺乏足够的监督信号, 导致语料规模扩充的同时产生了噪声信息, 进而引发过度翻译问题. 通过第4.3节的实验发现, 融入跨层注意力机制可以缓解句子结构缺失问题, 但未能消除句子中存在的噪声信息. 通过表7中的示例可以观察到: 利用传统方法得到的译文中, “the” 被重复翻译了一次, 而在使用跨层注意力后, 重复的“the” 并没有被消除; 同时虽然“gone” 被翻译为更合理的“left”, 但也产生了多余的译文“away”. 因此, 跨层注意力机制虽然能够通过使用更多的特征信息来提升句子的完整性, 但并未解决的噪声信息问题. 针对该问题, 本文在融入跨层注意力机制后应用变分信息瓶颈模型, 并对结果进行可视化处理. 如图5所示, 可以观察到图5(a)中冗余的“the” 和“away” 在图5(b)中被去除. 除此以外, 在图5(a)中, 由于噪声信息“the”和“away” 的出现, 使得“train” 和“left” 等译文的关注度相对分散; 而通过图5(b)可以观察到, 在消除了噪声信息后, 译文的关注更加集中.
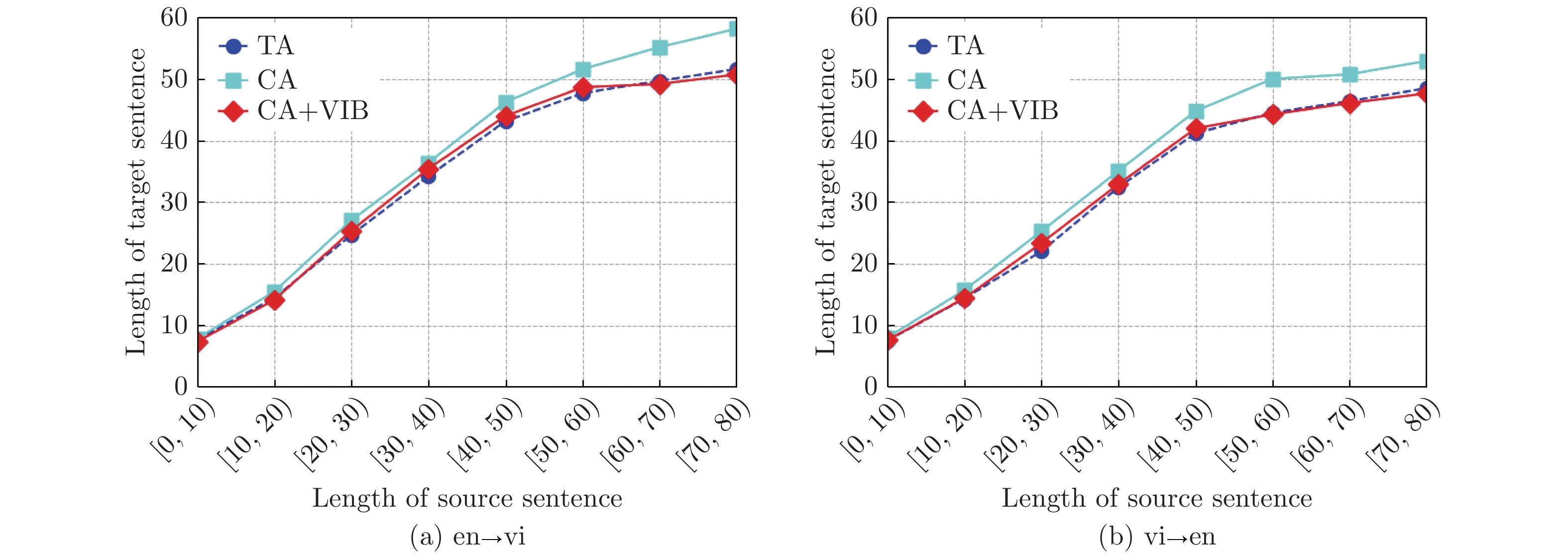
本文将测试集中的源语言句子按长度分为8组, 然后评测翻译产生的相应译文的长度. 英−越翻译任务的译文长度评测结果如图6所示, 从图6(a)中观察到, 英→越翻译方向上, 只使用跨层注意力机制(CA)后, 基础翻译模型所产生的译文长度优于作为基准系统的传统模型(TA). 而在此基础上应用变分信息瓶颈后(CA+VIB), 在区间[10, 60]内的译文长度高于基准系统, 在其余长度区间内低于基准系统. 实验表明, 跨层注意力机制通过引入多层特征, 能有效地提升译文句长. 而在应用变分信息瓶颈模型进行噪声信息过滤后, 译文长度下降, 但在译文的常规分布区间[10, 60]内仍优于基准系统.
变分信息瓶颈中的超参数
传统的回译模型侧重于关注产生的伪平行语料规模, 在生成基础翻译模型时, 缺乏对神经网络跨层次信息的重视. 在使用深层神经网络进行初步模型训练时, 仅局限于利用最高层或各层内部的语义信息作为上下文表征, 忽略了低层网络对高层网络表征的直接促进作用, 因此对句法结构等信息表征不足, 造成伪平行语料生成过程中的信息缺失. 针对此问题, 本文首先通过引入跨层注意力机制加强对各层网络信息的利用, 随后基于此基础训练模型进行语料扩充, 使语料在规模上能够满足变分方法的应用需求. 然而, 跨层注意力机制在加强特征信息利用、改善基础翻译模型的同时, 会进一步引入噪声信息, 针对此问题, 本文通过引入变分信息瓶颈来进行噪声的消除. 在多个翻译数据集上的实验结果表明, 相较基准系统, 本文提出的方法在有效提高译文质量的同时保持了译文句长, 并在一定程度上解决了传统神经机器翻译中出现的过度翻译问题.