0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

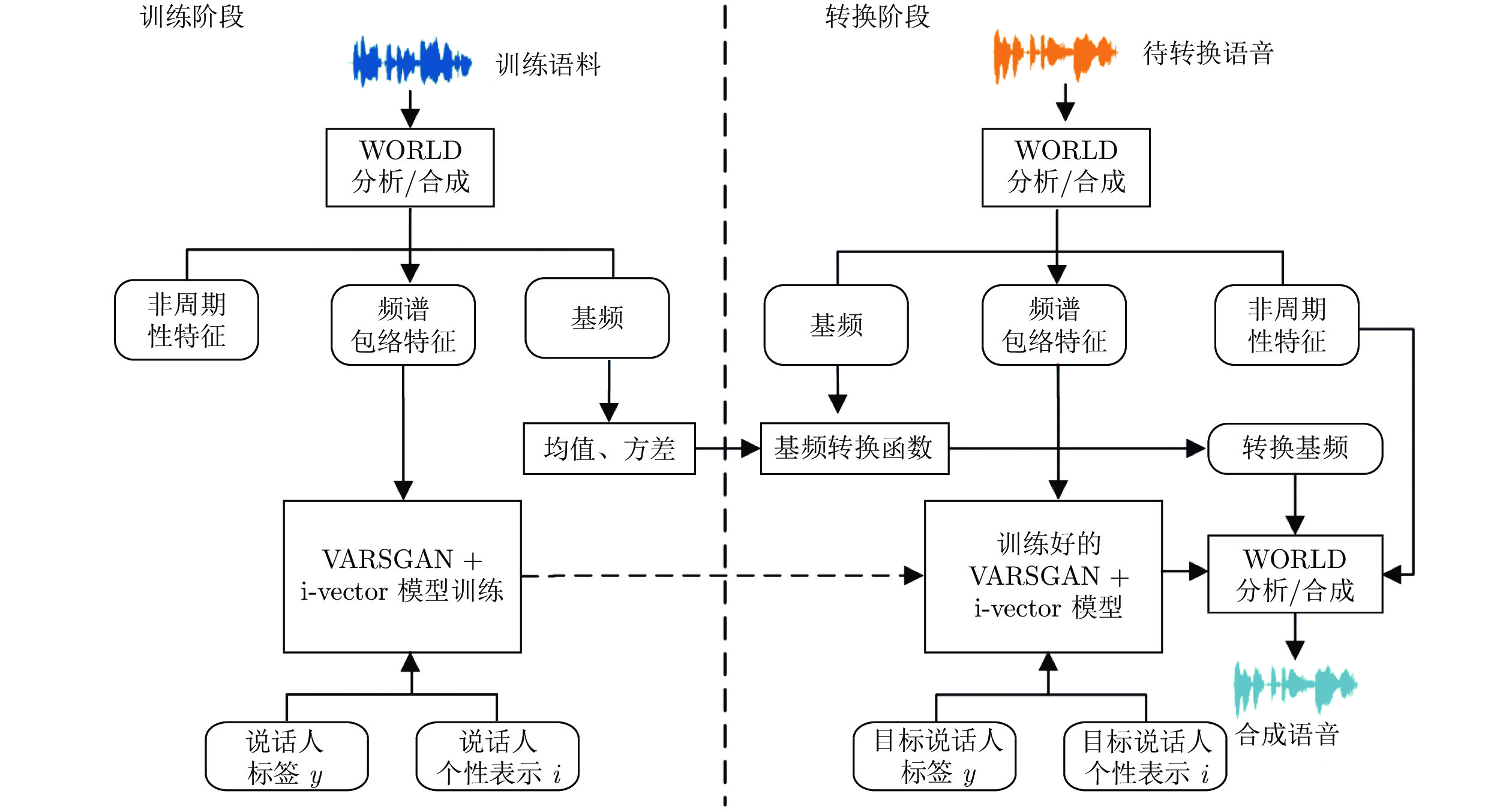
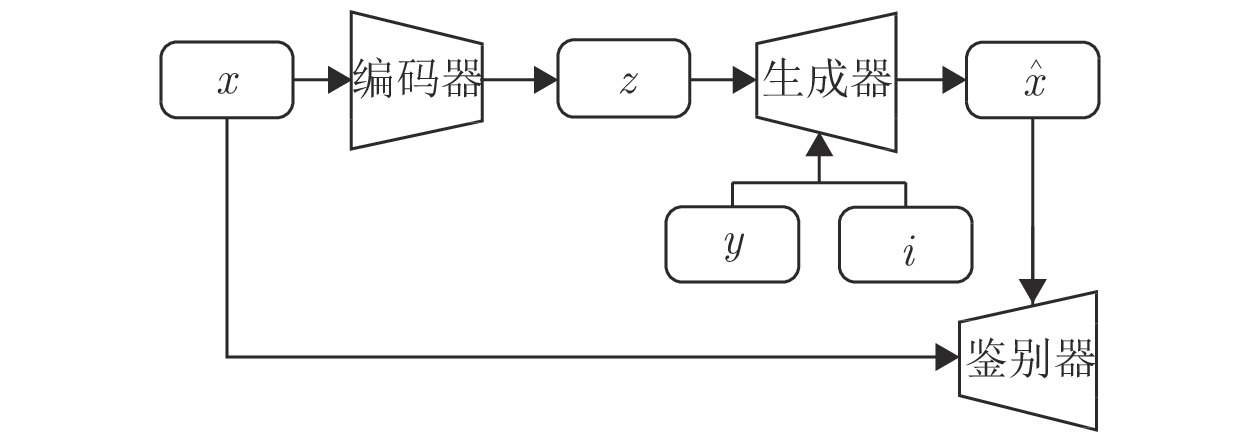
图 1 基于VARSGAN + i-vector 模型的整体流程图
Fig. 1 Framework of voice conversion based on VARSGAN + i-vector network
语音转换是在保持语音内容不变的同时, 改变一个人的声音, 使之听起来像另一个人的声音[1-2]. 根据训练过程对语料的要求, 分为平行文本条件下的语音转换和非平行文本条件下的语音转换. 在实际应用中, 预先采集大量平行训练文本不仅耗时耗力, 而且在跨语种转换和医疗辅助系统中往往无法采集到平行文本, 因此非平行文本条件下的语音转换研究具有更大的应用背景和现实意义.
性能良好的语音转换系统, 既要保持重构语音的自然度, 又要兼顾转换语音的说话人个性信息是否准确. 近年来, 为了改善转换后合成语音的自然度和说话人个性相似度, 非平行文本条件下的语音转换研究取得了很大进展, 根据其研究思路的不同, 大致可以分为3类, 第1类思想是从语音重组的角度, 在一定条件下将非平行文本转化为平行文本进行处理[3-4], 其代表算法包括两种, 一种是使用独立于说话人的自动语音识别系统标记音素, 另一种是借助文语转换系统将小型语音单元拼接成平行语音. 该类方法原理简单, 易于实现, 然而这些方法很大程度上依赖于自动语音识别或文语转换系统的性能; 第2类是从统计学角度, 利用背景说话人的信息作为先验知识, 应用模型自适应技术, 对已有的平行转换模型进行更新, 包括说话人自适应[5-6]和说话人归一化等. 但这类方法通常要求背景说话人的训练数据是平行文本, 因此并不能完全解除对平行训练数据的依赖, 还增加了系统的复杂性; 前两类通常只能为每个源−目标说话人对构建一个映射函数, 即一对一转换, 当存在多个说话人对时, 就需要构建多个映射函数, 增加系统的复杂性和运算量; 第3类是解卷语义和说话人个性信息的思想, 转换过程可以理解为源说话人语义信息和目标说话人个性信息的重构, 其代表算法包括基于条件变分自编码器 (Conditional variational auto-Encoder, C-VAE)[7]方法、基于变分自编码生成对抗网络(Variational autoencoding wasserstein generative adversarial network, VAWGAN)[8]方法和基于星型生成对抗网络 (Star generative adversarial network, StarGAN)[9]方法. 这类方法直接规避了非平行文本对齐的问题, 实现将多个源−目标说话人对的转换整合在一个转换模型中, 提供了多说话人向多说话人转换的新框架, 即多对多转换, 成为目前非平行文本条件下语音转换的主流方法.
基于C-VAE模型的语音转换方法, 其中的编码器对语音实现语义和个性信息的解卷, 解码器通过语义和说话人身份标签完成语音的重构, 从而解除对平行文本的依赖, 实现多说话人对多说话人的转换. 但是由于C-VAE基于理想假设, 认为观察到的数据通常遵循高斯分布, 导致解码器的输出语音过度平滑, 转换后的语音质量不高. 基于循环一致生成对抗网络的语音转换方法[10]可以在一定程度上解决过平滑问题, 但是该方法只能实现一对一的语音转换.
Hsu等[8]提出的VAWGAN模型通过在C-VAE中引入Wasserstein生成对抗网络(Wasserstein generative adversarial network, WGAN)[11], 将 VAE的解码器指定为WGAN的生成器来优化目标函数, 一定程度上提升转换语音的质量, 然而Wasserstein生成对抗网络仍存在一些不足之处, 例如性能不稳定, 收敛速度较慢等. 同时, VAWGAN使用说话人身份标签one-hot向量建立语音转换系统, 而该指示标签无法携带更为丰富的说话人个性信息, 因此转换后的语音在个性相似度上仍有待提升.
针对上述问题, 本文从以下方面提出改进意见: 1)通过改善生成对抗网络[12]的性能, 进一步提升语音转换模型生成语音的清晰度和自然度; 2)通过引入含有丰富说话人个性信息的表征向量, 提高转换语音的个性相似度. 2019年, Baby等[13]通过实验证明, 相比于WGAN, 相对生成对抗网络(Relativistic standard generative adversarial networks, RSGAN)生成的数据样本更稳定且质量更高. 此外, 在说话人确认[14-16]和说话人识别[17]领域的相关实验证明, i向量(Identity-vector, i-vector)可以充分表征说话人个性信息. 鉴于此, 本文提出基于i向量和变分自编码相对生成对抗网络的语音转换模型(Variational autoencoding RSGAN and i-vector, VARSGAN + i-vector), 该方法将RSGAN应用在语音转换领域, 利用生成性能更好的相对生成对抗网络替换VAWGAN模型中的Wasserstein生成对抗网络, 同时在解码网络引入含有丰富说话人个性信息的i向量辅助语音的重构. 充分的客观和主观实验表明, 本文方法在有效改善合成语音自然度的同时进一步提升了说话人个性相似度, 实现了非平行文本条件下高质量的多对多语音转换.
基于VAWGAN语音转换模型利用WGAN[11]提升了C-VAE的性能, 其中C-VAE的解码器部分由WGAN中的生成器代替. VAWGAN模型由编码器、生成器和鉴别器3部分构成. 完整的语音转换模型可表示为:
| (1) |
式中,
为实现语音转换, WGAN通过Wassertein目标函数[8]来代替生成对抗网络中的JS(Jensen-Shannon)散度来衡量生成数据分布和真实数据分布之间的距离, 在一定程度上改善了传统生成对抗网络[18]训练不稳定的问题.
综上分析可知, VAWGAN利用潜在语义内容
为进一步提升VAWGAN的性能, 通过找到一个生成性能更加强大的GAN替换WGAN是本文的一个研究出发点. 2019年Baby等[13]通过实验证明相比于最小二乘GAN[19]和WGAN[11], RSGAN生成的数据样本更稳定且质量更高. RSGAN由标准生成对抗网络发展而来, 通过构造相对鉴别器的方式, 使得鉴别器的输出依赖于真实样本和生成样本间的相对值, 在训练生成器时真实样本也能参与训练. 为了将鉴别器的输出限制在[0, 1]中, 标准生成对抗网络常常在鉴别器的最后一层使用sigmoid激活函数, 因此标准生成对抗网络鉴别器定义为:
| (2) |
式中,
| (3) |
| (4) |
式中,
| (5) |
可得
| (6) |
进而可得RSGAN的鉴别器和生成器的目标函数:
| (7) |
| (8) |
式中, sigmoid表示鉴别器最后一层使用sigmoid激活函数.
综上分析可知, 相比于WGAN, RSGAN生成的数据样本更稳定且质量更高, 若将RSGAN应用到语音转换中, 通过构造相对鉴别器的方式, 使得鉴别器的输出依赖于真实样本和生成样本间的相对值, 在训练生成器时真实样本也能参与训练, 从而改善鉴别器中可能存在的偏置情况, 使得训练更加稳定, 性能得到提升, 并且把真实样本引入到生成器的训练中, 可以加快GAN的收敛速度. 鉴于此, 本文提出利用RSGAN替换WGAN, 构建基于变分自编码相对生成对抗网络(Variational autoencoding RSGAN, VARSGAN)的语音转换模型, 并引入可以充分表征说话人个性信息的i向量特征, 以期望在改善合成语音自然度的同时, 进一步提升转换语音的个性相似度.
通过引入含有丰富说话人个性信息的表征向量, 从而提升转换语音的个性相似度是本文在上述研究基础上进一步的探索. Dehak等[14]提出的说话人身份i向量, 可以充分表征说话人的个性信息. i向量是在高斯混合模型−通用背景模型(Gaussian mixture model-universal background model, GMM-UBM)[15]超向量和信道分析的基础上提出的一种低维定长特征向量. 对于p维的输入语音, GMM-UBM模型采用最大后验概率算法对高斯混合模型中的均值向量参数进行自适应可以得到GMM超向量. 其中, GMM-UBM模型可以表征背景说话人整个声学空间的内部结构, 所有说话人的高斯混合模型具有相同的协方差矩阵和权重参数. 由于说话人的语音中包含了个性差异信息和信道差异信息, 因此全局GMM的超向量可以定义为:
| (9) |
式中,
首先, 将经过预处理的训练语料进行特征提取得到梅尔频率倒谱系数, 将梅尔频率倒谱参数输入高斯混合模型进行训练, 通过期望最大化算法得到基于高斯混合模型的通用背景模型, 根据通用背景模型得到均值超向量
基于以上分析, 本文提出VARSGAN + i-vector的语音转换模型, 在解码阶段融入表征说话人个性信息的i向量, 将one-hot标签和i向量拼接至语义特征上构成联合特征重构出指定说话人相关的语音. 其中, i向量含有丰富的说话人个性信息, 能够与传统编码中的one-hot标签相互补充, 互为辅助, 前者为语音的合成提供丰富的说话人信息, 后者作为精准的标签能够准确区分不同说话人, 相辅相成有效提升转换后语音的个性相似度, 进一步实现高质量的语音转换. 基于VARSGAN + i-vector模型的整体流程如图1所示, 分为训练阶段和转换阶段.
获取训练语料, 训练语料由多名说话人的语料组成, 包含源说话人和目标说话人; 将所述的训练语料通过WORLD[20]语音分析模型, 提取出各说话人语句的频谱包络、基频和非周期性特征; 利用第2.2节的i向量提取方法获得表征各个说话人个性信息的i向量
该模型完整的目标损失函数为:
| (10) |
式中,
| (11) |
式中,
式(10)中,
| (12) |
式中,
鉴别器网络的损失函数用
| (13) |
添加梯度惩罚项后, 鉴别器的损失函数更新为:
| (14) |
式中,
构建从源说话人语音对数基频
| (15) |
式中,
将待转换语料中源说话人的语音通过WORLD[20]语音分析模型提取出不同语句的频谱包络特征
本实验采用VCC2018[22]语料库, 该语料库是由国际行业内挑战赛提供的标准数据库, 为评估不同科研团队的语音转换系统的性能提供一个通用标准. 链接为
实验系统在Python平台环境下实现. 在Intel(R) Xeon(R) CPU E5-2660v4@2.00GHz, NVIDIA Tesla V100 (reva1)的Linux服务器上运行, 对语料库中的8个说话人的语音基于5种模型进行客观和主观评测, 将VAWGAN[8]作为本文的基准模型与本文提出的改进模型VARSGAN、VAWGAN + i-vector和VARSGAN + i-vector进行纵向对比, 并进一步与StarGAN模型[9]进行横向对比, 这5种模型都是实现非平行文本条件下的多对多转换.
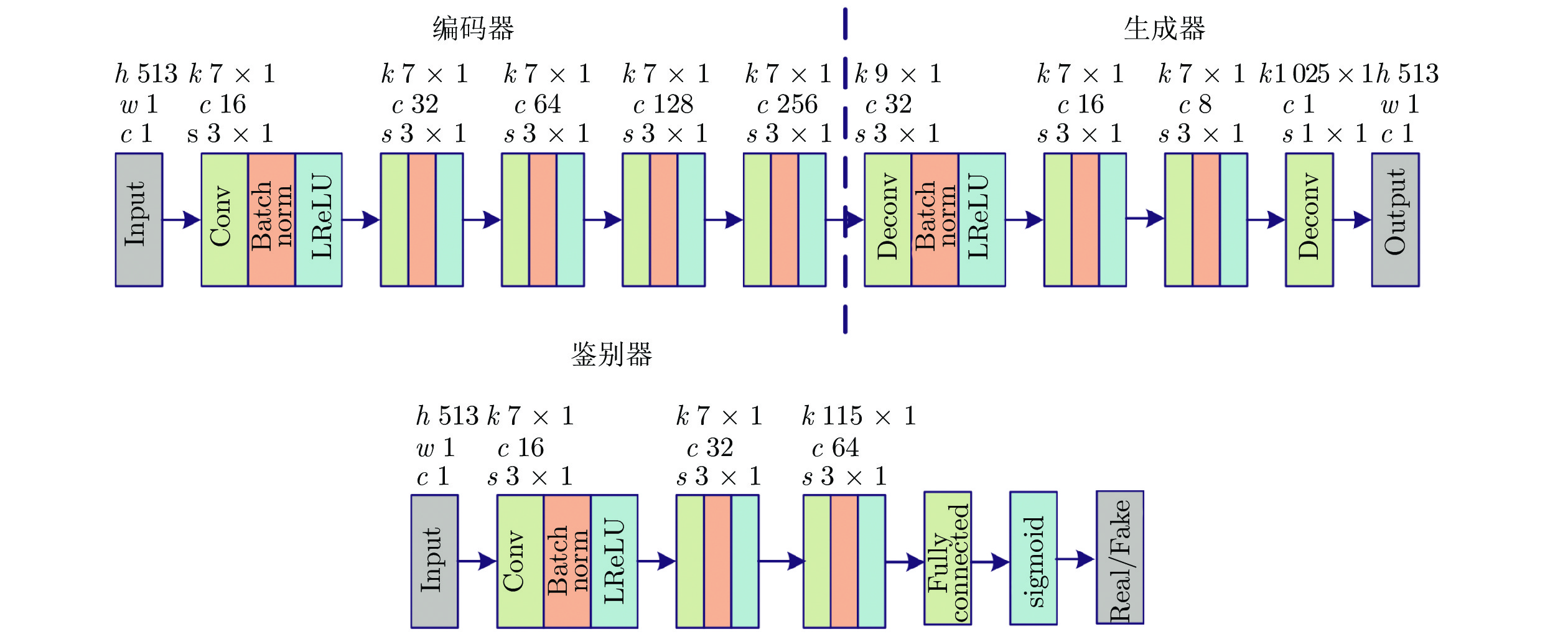
本文使用WORLD分析/合成模型提取语音参数, 包括频谱包络特征、非周期性特征和基频, 由于FFT长度设置为1024, 因此得到的频谱包络和非周期性特征均为1024 /2 + 1 = 513维. 使用VARSGAN + i-vector模型转换频谱包络特征, 使用传统的高斯归一化的转换方法转换对数基频, 非周期性特征保持不变. 在VARSGAN + i-vector模型中, 所述编码器、生成器、鉴别器均采用二维卷积神经网络, 激活函数采用LReLU函数[23]. 图3为VARSGAN + i-vector模型网络结构图, 其中编码器由5个卷积层构成, 生成器由4个反卷积层构成, 鉴别器由3个卷积层和1个全连接层构成.
图3中, h、w、c分别表示高度、宽度和通道数, k、c、s分别表示卷积层的内核大小、输出通道数和步长, Input表示输入, Output表示输出, Real / Fake表示鉴别器判定为真或假, Conv表示卷积, Deconv表示反卷积 (转置卷积), Fully Connected表示全连接层, Batch Norm表示批归一化. 实验中隐变量
本文选用梅尔倒谱失真距离(Mel-cepstral distortion, MCD)作为客观评价标准, 通过MCD值来衡量转换后的语音与目标语音的频谱距离[1-2], MCD计算公式如下:
| (16) |
式中,
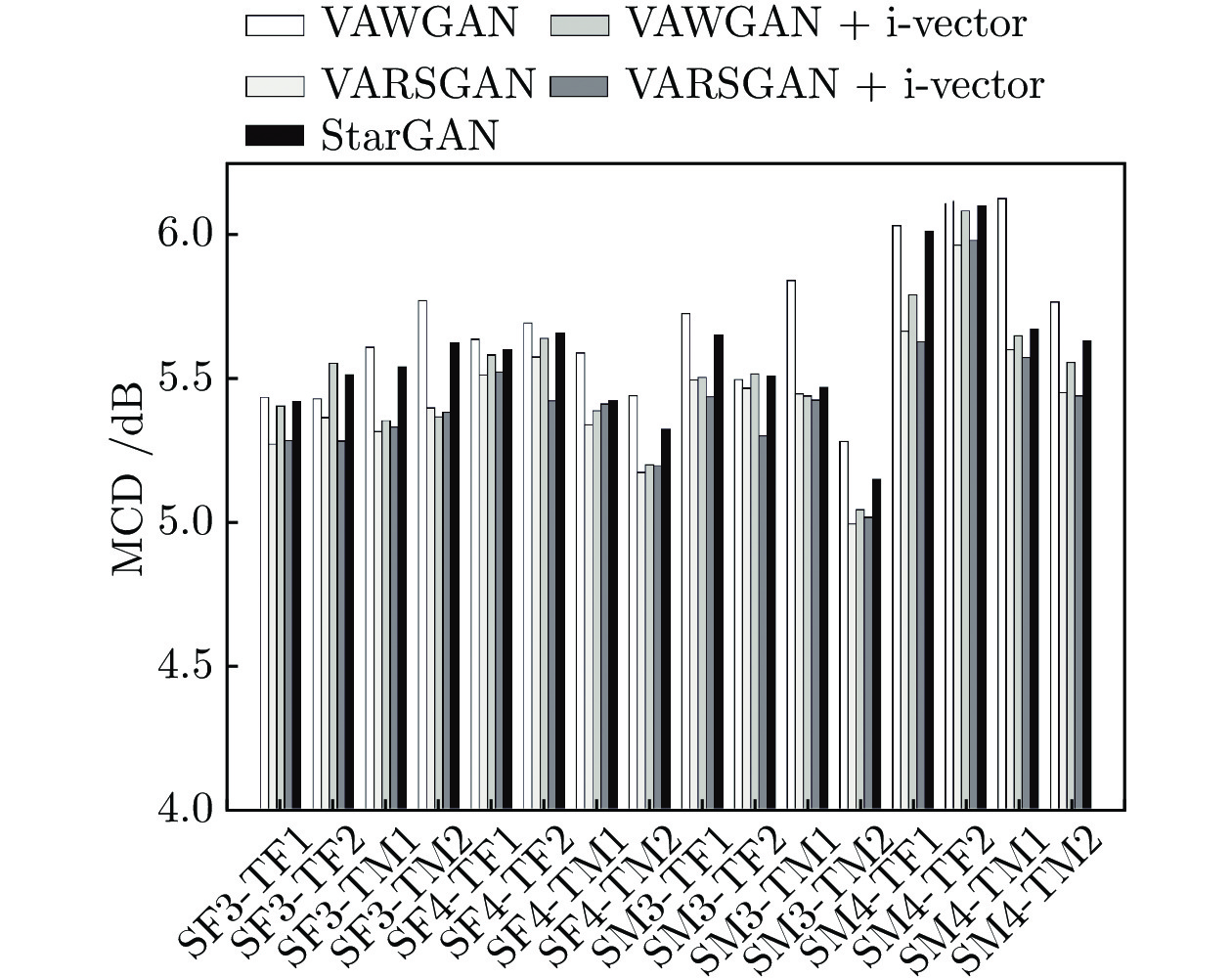
由图4可知, 16种转换情形下VAWGAN、VARSGAN、VAWGAN + i-vector、VARSGAN + i-vector和StarGAN模型的转换语音的平均MCD值分别为5.690、5.442、5.507、5.417和5.583. 本文提出的3种模型相比基准模型, 分别相对降低了4.36%、3.22%和4.80%. VARSGAN + i-vector模型相比StarGAN模型相对降低了2.97%. 表明相对生成对抗网络的结合和i向量的引入能够显著改善转换语音的合成自然度, 有助于提升转换语音的质量.
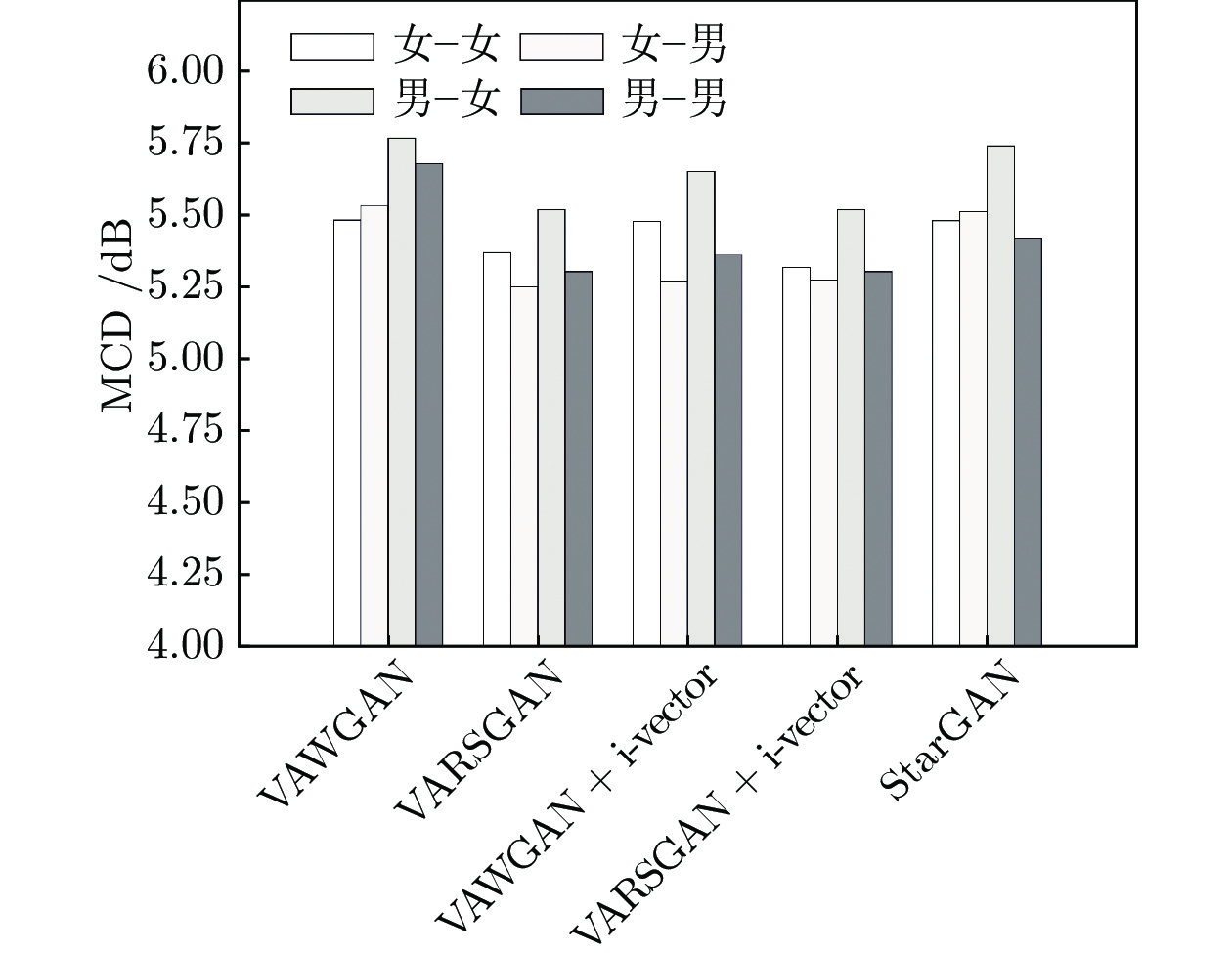
进一步将上述16种转换情形按照源−目标说话人性别划分为具有统计性的4大类, 即同性别转换女−女、男−男和跨性别转换男−女、女−男. 4大类转换情形下不同模型的MCD值对比如图5所示.
进一步分析实验结果可得, 本文提出的方法VARSGAN + i-vector在跨性别转换下, 女−男类别下的平均MCD值比男−女类别下的平均MCD值相对低4.58%, 表明女性向男性的转换性能稍好于男性向女性的转换. 而这一现象在基准系统VAWGAN、VARSGAN、VAWGAN + i-vector和 StarGAN中也不同程度地存在. 原因主要是, 语音的发音主要由基频和丰富的谐波分量构成, 即使同一语句, 由于不同性别说话人之间的基频和谐波结构存在差异较大[24-25], 会导致不同性别说话人之间的转换存在一定的性能差异.
本文采用反映语音质量的平均意见得分(Mean opinion score, MOS)值和反映说话人个性相似度的ABX值来评测转换后语音. 主观评测人员为20名有语音信号处理研究背景的老师及硕士研究生, 为了避免主观倾向以及减少评测人员的工作量, 从5种模型的各16种转换情形的35句转换语音里面为每个人随机抽取一句, 并将语句顺序进行系统置乱. 其中在ABX测试中, 评测人员还需同时测听转换语音相对应的源和目标说话人的语音.
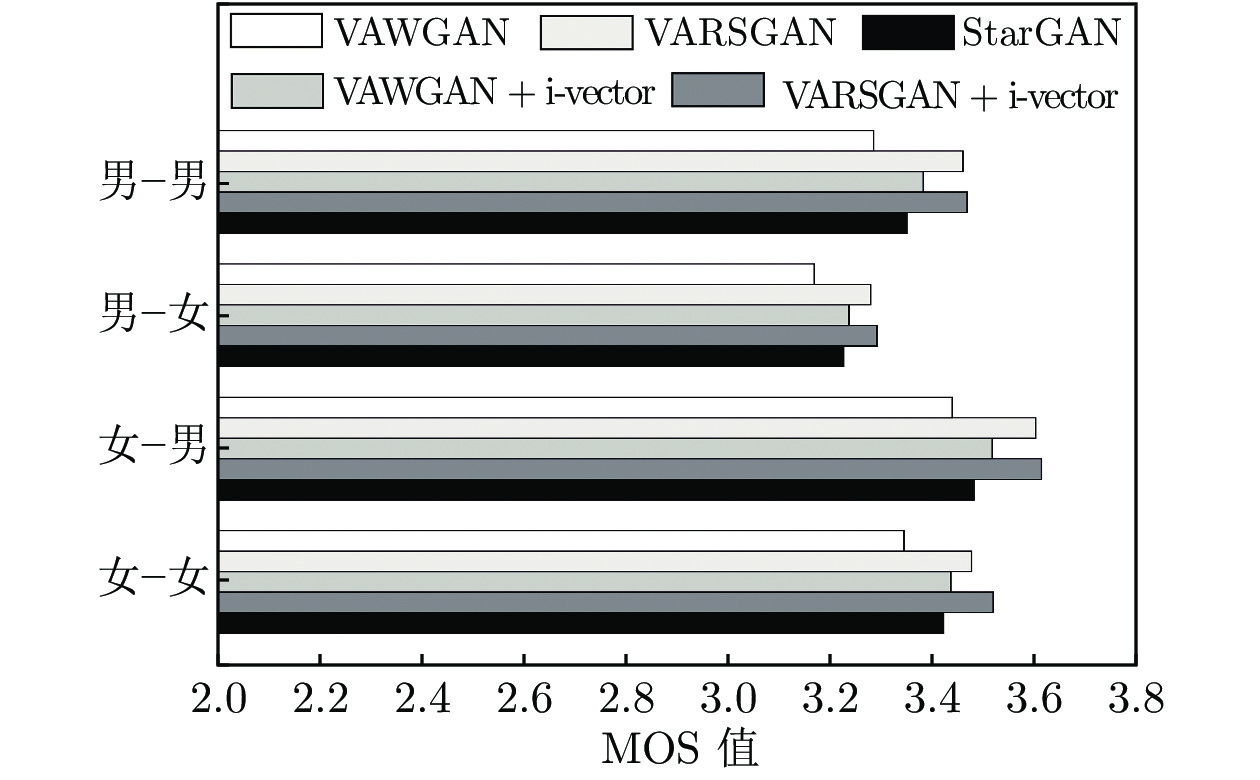
在MOS测试中, 评测人员根据听到的转换语音的质量对语音进行打分, 评分分为5个等级: 1分表示完全不能接受, 2分表示较差, 3分表示可接受, 4分表示较好, 5分表示非常乐意接受. 本文将16种转换情形划分为4类: 男−男, 男−女, 女−男, 女−女, 4类转换情形下5种模型的转换语音MOS值对比如图6所示.
通过分析实验结果可得, VAWGAN、VARSGAN、VAWGAN + i-vector、VARSGAN + i-vector和StarGAN的平均MOS值分别为3.382、3.535、3.471、3.555和3.446. 相比基准模型, 本文3种模型的MOS值分别相对提高了4.52%、2.63%和5.12%, VARSGAN + i-vector相比StarGAN提高了3.16%, 表明本文提出的相对生成对抗网络和i向量的引入能够有效地改善合成语音的自然度, 提高听觉质量.
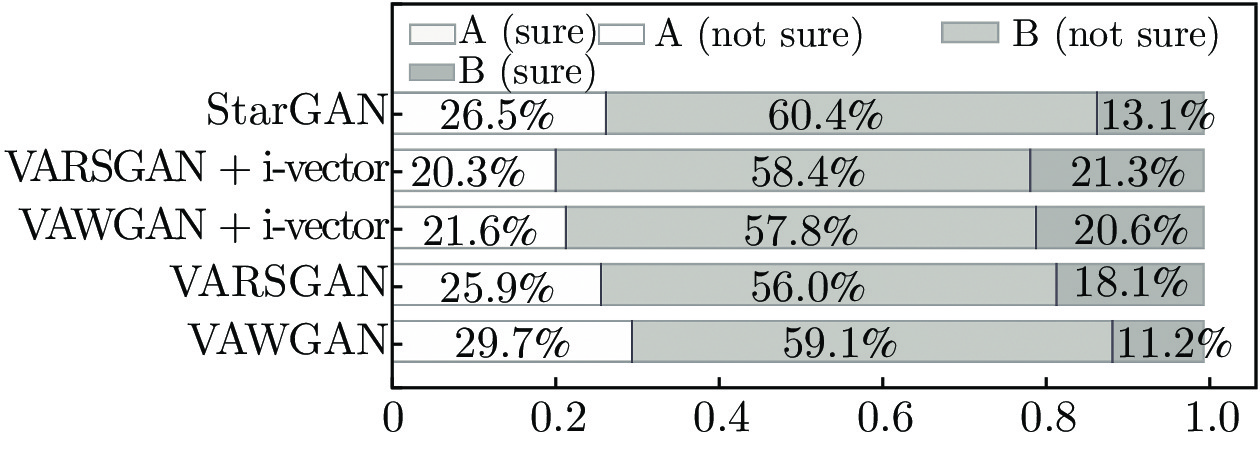
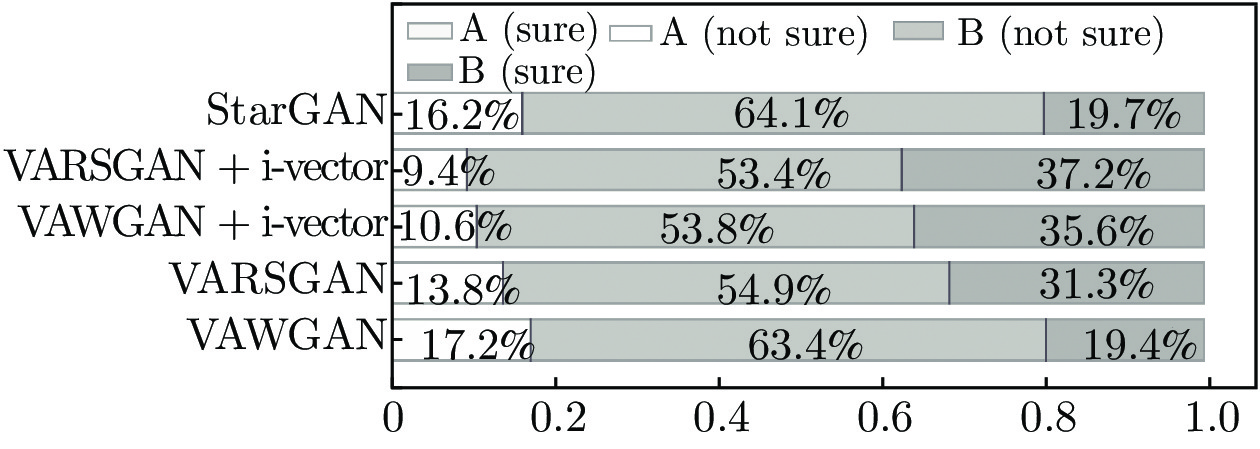
在ABX测试中, 评测人员测评A、B和X共3组语音, 其中A代表源说话人语音, B代表目标说话人语音, X为转换后得到的语音, 评测人员判断转换后的语音更加接近源语音还是目标语音. 一般将16种转换情形划分为同性转换和异性转换. 5种模型在同性转换下的ABX测试结果如图7所示, 异性转换下的ABX测试结果如图8所示.
图8中, A (sure)表示转换语音完全确定是源说话人, A (not sure)表示转换语音像源说话人但不完全确定, B (not sure)表示转换语音像目标说话人但不完全确定, B (sure)表示转换语音像目标说话人且完全确定. 在5种模型中, 没有评测人员认为转换后的语音确定是源说话人, 因此A (sure)没有得分, 即在图中没有比例显示. 在评测结果分析中, 将B (not sure)和B (sure)的比例之和作为转换语音更像目标说话人的衡量指标.
如图7和图8所示, 5种模型在异性转换下的说话人个性相似度均优于同性转换下的说话人个性相似度, 其中在同性转换情形下,VAWGAN、VARSGAN、VAWGAN + i-vector、VARSGAN + i-vector和StarGAN的ABX值的比例分别为 70.3%、74.1%、78.4%、79.7%和73.5%, 相比基准模型, 本文3种模型分别提升了3.8%、8.1%和6.2%, VARSGAN + i-vector 相比StarGAN模型提升了4.4%. 在异性转换情形下5种模型的ABX值的比例分别为82.8%、86.2%、89.4%、90.6%和83.8%, 相比基准模型, 本文3种模型分别提升了3.4%、6.6%和7.8%, VARSGAN + i-vector相比StarGAN提升了6.8%. 在同性和异性2种情形下, 本文提出的3种模型相比基准模型,平均ABX值分别提升了3.6%、7.35%和8.6%, VARSGAN + i-vector模型相比StarGAN模型提升了5.6%, 由分析可以看出, 相对生成对抗网络的改进不仅有效地改善了合成语音的自然度, 而且也有助于说话人个性相似度的提高; 结合传统说话人编码one-hot实现多对多语音转换的同时, 在解码阶段融入含有丰富说话人个性信息的特征i向量, 能够有效增强目标说话人的个性信息, 显著提升说话人的个性相似度. 因此, 本文方法能够显著改善模型的性能.
综上所述, VARSGAN + i-vector 模型相比基准模型 VAWGAN和StarGAN, 平均MOS值相对提高了5.12%和3.16%, 平均ABX值提升了8.6%和5.6%, 表明本文提出的相对生成对抗网络和i向量的引入, 能够显著提高合成语音的自然度和个性相似度.
本文提出一种基于VARSGAN + i-vector的语音转换模型, 该方法利用RSGAN 替代基准模型中的WGAN, 改进了语音转换模型中生成对抗网络的性能, 从而生成语音自然度更好的转换语音. 进一步将i向量引入基于VARSGAN的语音转换模型, 在模型训练和转换过程中利用i向量表征说话人的个性信息, 有效提升转换语音的个性相似度. 充分的客观和主观实验结果表明, 相比于基准模型 VAWGAN 和 StarGAN, 本文提出的方法在有效改善转换语音的合成质量的同时, 也显著提升了说话人个性相似度, 实现了高质量的语音转换. 今后工作将研究序列到序列的语音转换, 进一步考虑韵律特征的建模和转换, 此外, 降低对训练数据量的需求以实现小样本语音转换[26]也是课题组后续进一步研究的关注点和探索方向, 这也是该技术真正进入工业领域需要接受的挑战之一.