0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

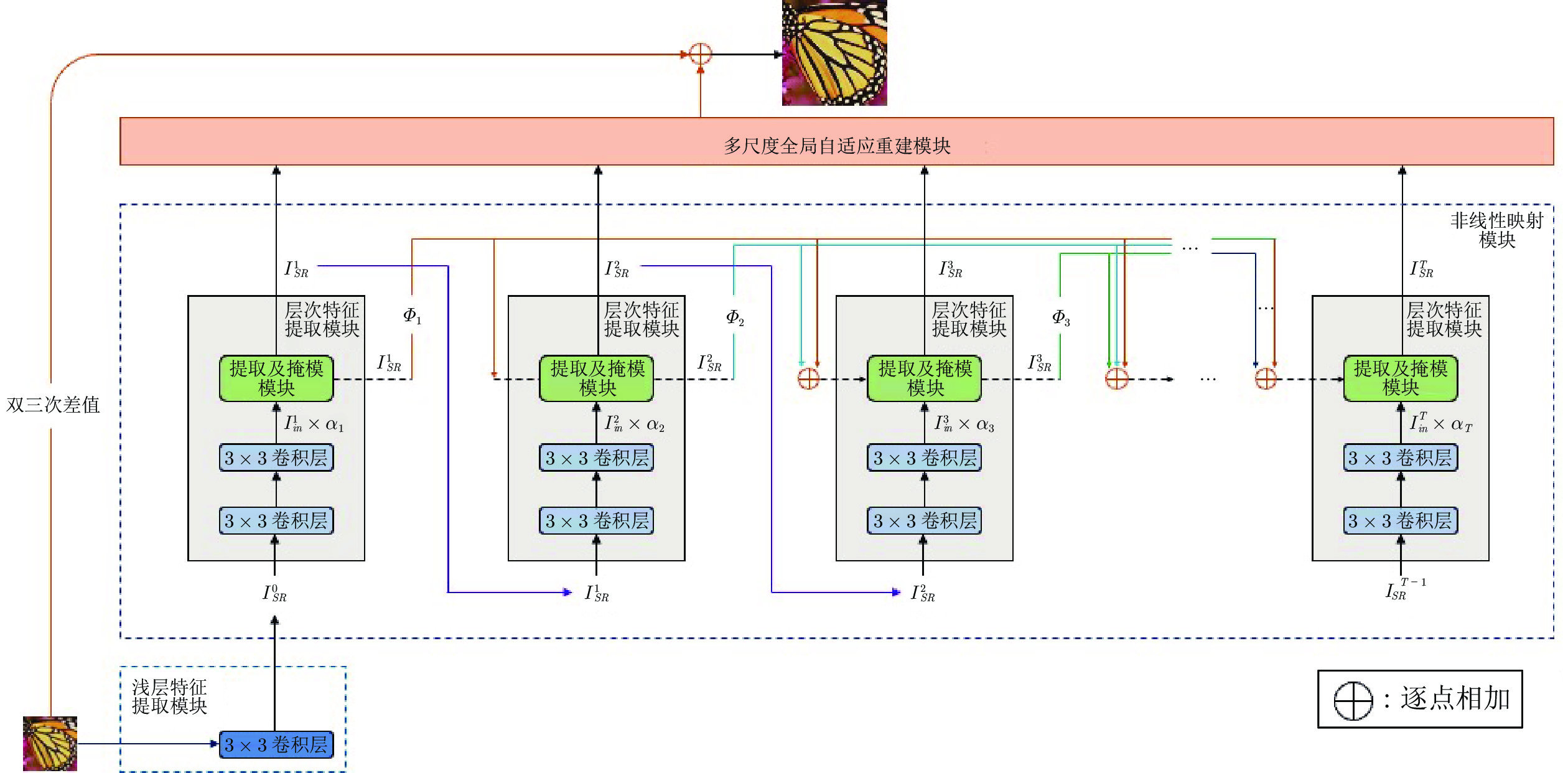
图 1 自适应级联的注意力网络架构(ACAN)
Fig. 1 Adaptive cascading attention network architecture (ACAN)
单图像超分辨率(Single image super-resolution, SISR)[1]技术是一个经典的计算机视觉任务, 旨在从一个低分辨率(Low-resolution, LR)图像生成对应的高分辨率(High-resolution, HR)图像, 在医学成像、监控和遥感等领域有十分广泛的应用. SISR是一个病态的逆问题, 要重建逼真的HR图像非常困难, 因为一个LR图像可与多个HR图像对应, 需要假定的先验知识, 正则化原HR图像解[2].
近年来, 深度学习[3]技术显著改进了SISR性能, 并主导了当前SISR技术的研究. Dong等[4]提出了第1个基于卷积神经网络的SISR算法称为超分辨率卷积神经网络(Super-resolution convolutional neural network, SRCNN). SRCNN只有3个卷积层, 感受野较小. 之后的SISR方法的一个趋势是: 逐步加深网络, 从而获得更强的LR-HR映射能力, 同时拥有更大的感受野, 能够融入更多的背景信息, 改进了SISR性能[5]. 然而加深网络也会带来一些问题: 更大的网络(更深或更宽), 会有更多的参数, 需要更大的内存和更强的计算力, 这阻碍了在资源受限的设备, 如移动设备上的实际应用. 当前已有一些引人注意的基于轻量级网络的SISR方法被提出. Kim等[6]提出的深度递归卷积网络(Deeply-recursive convolutional network, DRCN)方法, 使用深度递归的方法, 在卷积层之间共享参数, 在加深网络的同时, 尽可能不增加网络参数量. Tai等[7]提出的深度递归残差网络 (Deep recursive residual network, DRRN), 也使用了深度递归的方法. 与DRCN的区别在于DRRN在残差块之间共享参数, 不仅显著地减少了参数量, 而且性能也显著更好. Tai等[8]也提出了深度持续记忆网络(Deep persistent memory network, MemNet)方法, 使用记忆模块, 并多次递归, 既能控制参数量, 也能更好地利用多层特征信息. Ahn等[9]提出的级联残差网络(Cascading residual network, CARN)方法, 使用级联残差的形式, 重用不同层次的信息. Li等[5]提出的轻量级超分辨率反馈网络 (Lightweight super-resolution feedback network, SRFBN-S)方法, 使用循环神经网络结构, 共享隐藏层的参数, 并多次利用各个隐藏层的输出, 从而改进了网络性能.
本文提出了一个新的轻量级SISR模型, 称为自适应级联的注意力网络(Adaptive cascading attention network, ACAN). 与当前类似的尖端SISR方法相比, ACAN有更好的性能和参数量平衡. 的主要贡献包括: 1)提出了自适应级联的残差(Adaptive cascading residual, ACR) 连接. 残差块之间的连接权重, 是在训练中学习的, 能够自适应结合不同层次的特征信息, 以利于特征重用. 2)提出了局部像素级注意力(Local pixel-wise attention, LPA)模块. 其对输入特征的每一个特征通道的空间位置赋予不同的权重, 以关注更重要的特征信息, 更好地重建高频信息. 3)提出了多尺度全局自适应重建(Multi-scale global adaptive reconstruction, MGAR)模块, 不同尺寸的卷积核处理不同层次的特征信息, 并自适应地组合处理结果, 以产生更好的重建图像.
注意力机制在计算机视觉领域中已经引起了越来越多的关注[10-12]. 在图像分类问题中, Wang等[11]设计了软掩模支路, 同时探索特征在空间维度和通道维度上的关系. Hu等[12]提出了轻量级的挤压和激励(Squeeze-and-excitation, SE)模块, 在网络训练过程中探索特征通道之间的内在联系. 在图像理解问题中, Li等[13]提出了引导的注意推理网络, 网络预测结果能够聚焦于感兴趣的区域. Liu等[14]首次将注意力机制引入到SISR中, 提出了全局的注意力产生网络, 能够定位输出特征的高频信息, 以改进SISR性能. Zhang等[15]提出的残差通道注意力网络 方法, 使用通道注意力机制, 能够选择携带信息丰富的特征通道. 本文主要受Wang等[11]和Liu等[14]的启发, 提出了局部像素级注意力模块. 在像素级别上定位高频信息丰富的区域, 以更好地利用特征.
上采样层是SISR重建中很重要的一个组成部分. 早期基于深度学习的SISR方法[4, 8, 16], 一般先将LR图像, 用双三次插值到目标HR图像的尺寸, 再输入到网络模型. 这有助于减轻学习难度, 但大大增加了网络的计算量与参数量[17]. 目前常用的重建方法是直接输入原始的LR图像[18-19], 再将网络模型的输出上采样得到重建的HR图像. 文献[18]和文献[20]使用转置的卷积作为上采样层, 文献[15]和文献[19]使用亚像素卷积进行上采样. 这些单尺度上采样能缓解预上采样的弊端, 但是, 其同样存在难以充分利用网络模型产生的丰富的特征信息的问题. 本文提出了一种多尺度全局自适应的上采样方式: 针对不同的层次特征使用不同尺寸的卷积核, 多尺度地利用网络模型产生的特征信息, 并能够根据自适应参数, 自适应选择不同层次特征的结合方式, 以改进超分辨率的重建效果.
本文ACAN网络模型主要包括: 浅层特征提取模块(Shallow features extract block, SFEB)、非线性映射模块(Non-linear mapping block, NLMB)、多尺度全局自适应重建模块和全局残差连接, 如图1所示. SFEB是一个3 × 3卷积层, 提取输入LR图像的浅层特征, 并将提取的特征输入到NLMB模块. 本文使用的所有大小的卷积层的尾部都伴随着激活层, 并且使用PReLU作为所有激活层的激活函数, 后文不再详细说明. 受SRFBN[5]的启发, 本文在NLMB中采用类似结构, 并在层次特征提取模块(Hierarchical features extract block, HFEB)之间参数共享, 以减少参数量. NLMB是HFEB的多次递归, 在SFEB的基础上进一步进行深层特征的提取. HFEB由2个3 × 3的卷积层和一个提取及掩模(Extract-and-mask, EM)模块组成. 由于本文设计的ACR连接, 第1个HFEB的输入仅为SFEB的输出, 之后递归的每一次, HFEB的输入都包含两个部分: 1)上一层HFEB的输出; 2)前面所有HFEB的输出与对应的自适应参数相乘后的和, 并直接输入到当前HFEB的EM模块中. MGAR模块则接收NLMB所有输出重建残差图像; 最后, 全局残差连接产生双三次插值的LR图像, 与残差图像相加之后即为重建的HR图像. 由于文献[21]已经指出L2函数作为损失函数所谓缺点, 所以本文使用L1损失函数, 如下式所示:
| (1) |
式中,
第2.1 ~ 2.3节详细介绍HFEB、EM模块和MGAR模块.
HFEB的重要特征是: 每个HFEB的输入来源不同. 由于信息在流动过程中会不断损耗, 因此希望使用跳跃连接解决这个问题. 为了有效地进行特征重用, 同时考虑参数量的问题, 最终搭建了自适应级联残差(ACR)连接, 如图1所示. ACR连接结构上类似于级联连接, 但本质上仍为残差连接, 并通过自适应参数控制信息流动. 由图1可知, 由于ACR连接, 除第1个HFEB的输入只接收SFEB的输出外, 之后的每个HFEB的输入都包括两个部分: 1) 上一层HFEB的输出; 2) 前面所有HFEB的输出与对应的自适应参数相乘后的和.
在第
| (2) |
式中,
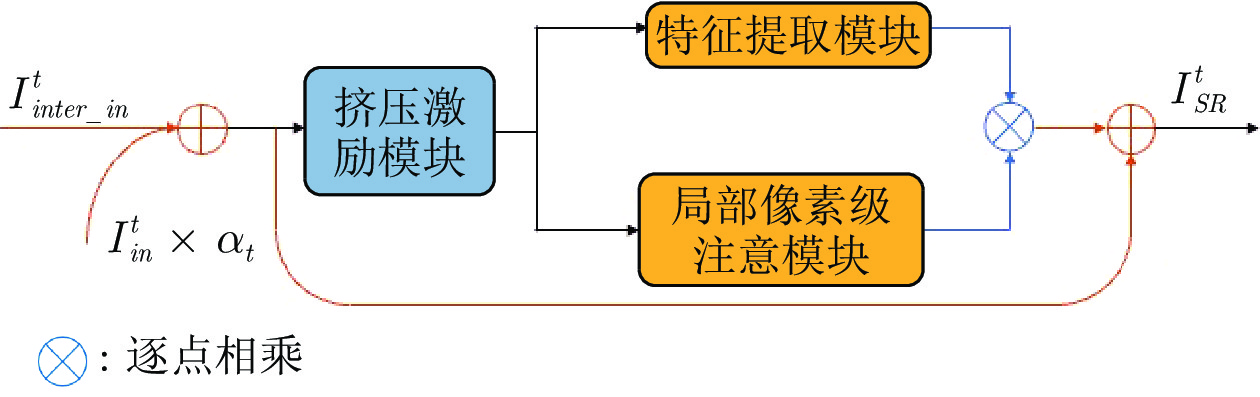
在每个HFEB中, 使用EM模块选择和提取高频特征信息. EM模块主要由特征预处理单元、特征提取模块和局部像素级注意力模块3个部分组成, 如图2所示.
如前所述, 第
| (3) |
| (4) |
式中,
为了缓解梯度消失的问题, 在EM模块外增加了局部残差连接. 第
| (5) |
下面详细介绍EM模块的各个组成部分.
为了初步选择信息更丰富的特征, 先在EM模块中, 使用类似于Hu等[12]提出的SE模块, 进行通道级的特征选择. 为了加权各个特征通道, 将SE模块中的Sigmoid门函数替换成Softmax门函数. 同时为了减少因Softmax门函数引起的信息损失, 增加了局部残差连接. 修改的SE模块, 可表示如下:
| (6) |
式中,
修改后的SE模块的输出
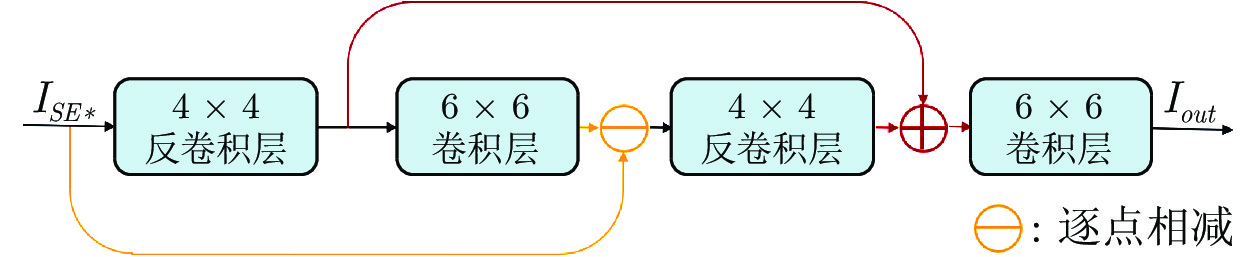
Haris等[22]已经证明了使用递归的上下采样进行特征提取的有效性. 因此, 也使用这种采样方式进行特征提取. 输入特征
| (7) |
| (8) |
然后使用局部残差连接将
| (9) |
| (10) |
特征提取模块中, 使用的两次转置卷积和两次卷积, 都使用了参数共享. 特征提取模块
| (11) |
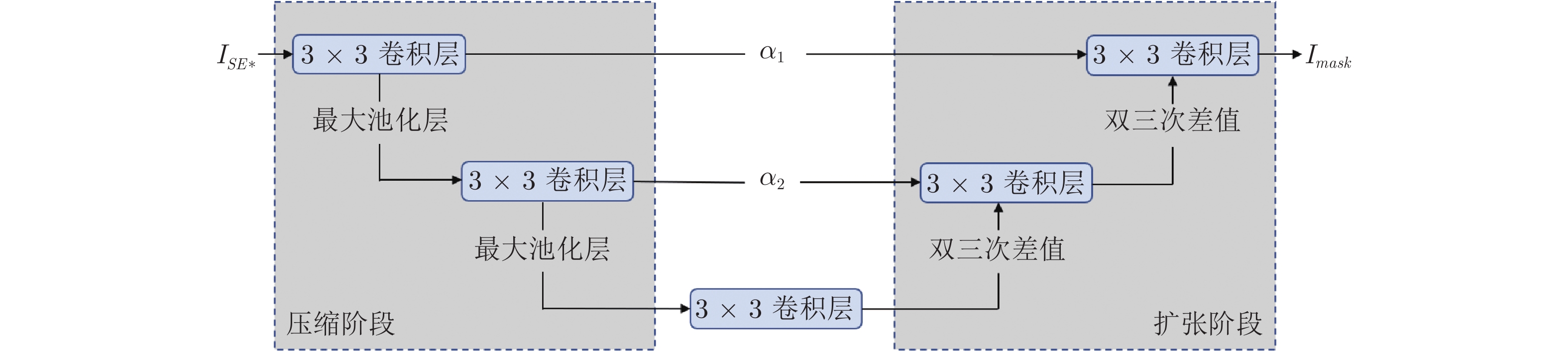
由于通道注意力机制只按通道携带的信息量多少进行选择, 对于高频信息的定位可能不够准确. 受Wang等[11]和Liu等[14]的启发, 提出局部像素级注意(LPA)模块, 进行像素级的高频信息定位. LPA模块如图4所示, 为了减小参数量, 各卷积层的参数都是共享的.
在压缩阶段, 使用了2个连续的3 × 3卷积层−最大池化操作. 最大池化下采样有助于扩大感受野和定位高频特征信息区域. 压缩阶段可表示如下:
| (12) |
在扩张阶段, 设置与压缩阶段对称的2个连续的上采样−3 × 3卷积层, 并使用双三次插值作为上采样方式. 考虑到下采样会造成部分信息丢失, 在扩张阶段和压缩阶段的对应位置处建立了跳跃连接, 并且引入了可学习的自适应参数
| (13) |
式中,
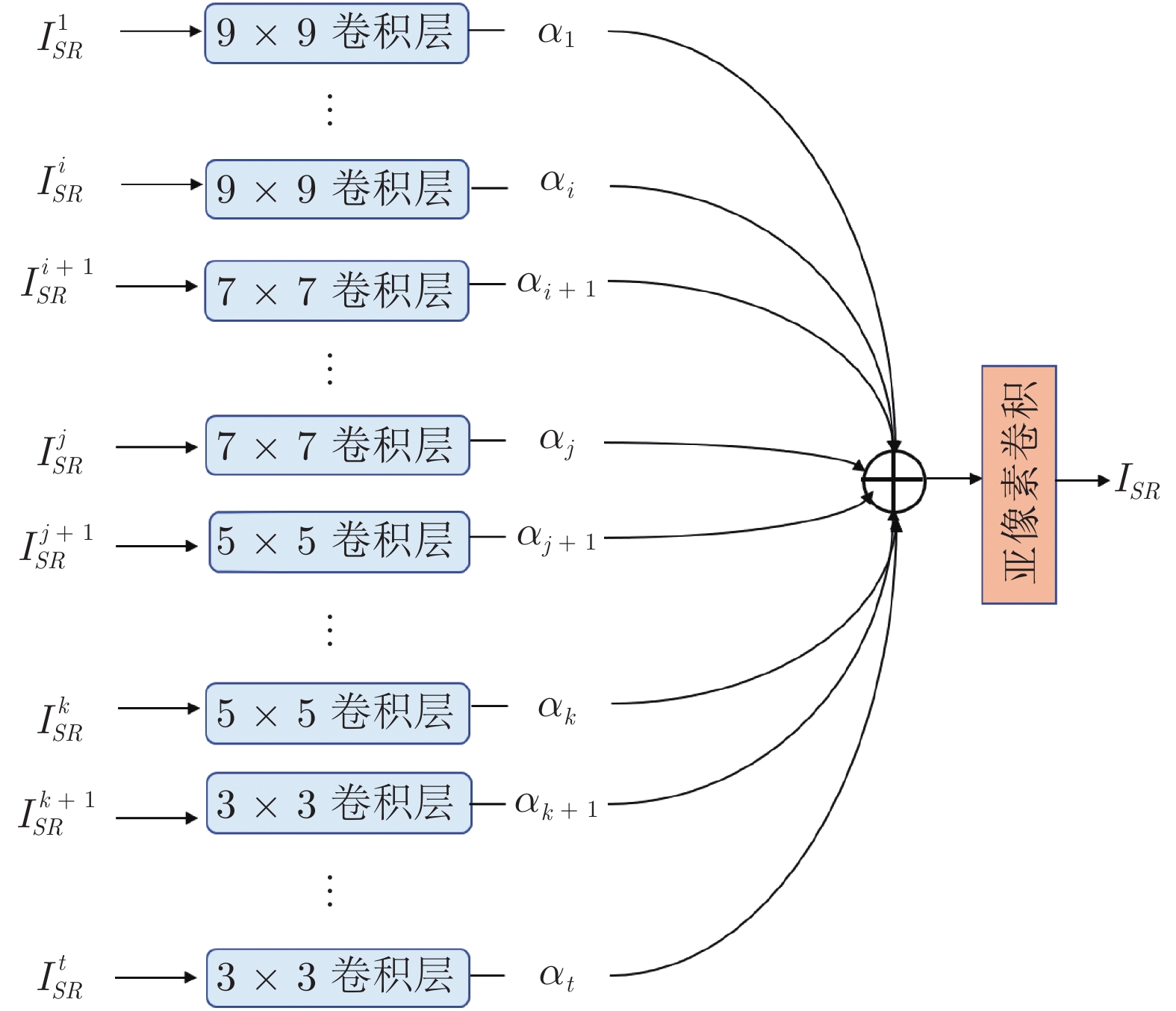
文献[4−9]大多是单尺度的重建, 受MSRN[21]的启发, 提出了多尺度重建的MGAR模块, 可以利用NLMB中提取的层次特征, 进一步改进SISR重建性能. MGAR模块与MSRN中MSRB的区别在于: MGAR模块是一个SISR重建模块, 多尺度利用之前的层次特征, 重建残差图像; MSRB是一个特征提取模块, 仅处理前一个MSRB输出的特征.
MGAR模块如图5所示. 由于NLMB中低层HFEB的感受野较小, 故在MGAR模块中使用较大的卷积核与之对应, 然后, 逐渐减少卷积核的大小. 考虑到参数量的约束, 选取最大的卷积核尺寸为9, 最小的卷积核尺寸为3. 假定NLMB中有
| (14) |
当
MGAR模块的每一个输入, 与对应卷积核卷积后, 再与一个可学习的自适应参数相乘, 作为当前支路的输出. 各个分支的和, 经过亚像素卷积[19]上采样之后, 作为MGAR模块的最终输出. 对输入的LR图像进行双三次上采样后, 与MGAR模块的输出求和, 得到重构的HR图像, 用公式表示如下:
| (15) |
式中,
本文实验保持与之前的研究文献设置相同. 训练图像: DIV2k数据集[23]中800张高质量图像; 测试图像: 共同使用的Set5[24], Set14[25]、Urban100[26]、B100[27]和Manga109[28]测试集; 验证图像: DIV2k数据集中第801 ~ 810张高质量图像; 训练图像增扩: 进行90、180、270度旋转、水平翻转和随机裁剪. 训练阶段: 在RGB颜色空间上进行训练, 并且使用梯度裁剪策略稳定训练过程. 测试阶段: 所有彩色图像均转换到YCrCb颜色空间, 在亮度通道Y上进行测试. 每一个最小批训练输入: 16个48 × 48的图像. 使用Adam优化器[29]训练网络, 其中设置
在NLMB中, 每个HFEB的第1个卷积层, 输出通道数为128, 其余卷积层的输出通道数均为64. ACR连接中, 所有自适应参数的初始值为0.2. 在MGAR模块中, 所有的自适应参数初始化为
在MGAR模块中, 选择卷积核尺寸为9、7、5、3的排列顺序, 具体参见第2.3节. 下面分析不同排列顺序对重建结果的影响, MGAR模块结构见图5. MGAR模块的输入来自NLMB的HFEB, 浅层HFEB的感受野较小, 使用较大的卷积核, 以提取更加全局的背景信息; 深层HFEB的感受野较大, 使用较小的卷积核, 防止提取不相关的背景信. 在MGAR模块中, 每个卷积层的输出特征如图6所示. 浅层HFEB输出的特征包含更多连续的高频信息, 深层HFEB输出的特征包含更多分散的高频信息. 不同层次特征信息互补, 可以增强HR图像的重建效果.
下面设置4组对比实验, 进一步量化卷积核的排列顺序对重建结果的影响. 4组实验使用的卷积核尺寸分别是: 第1组为9、7、5、3; 第2组为3、5、7、9; 第3组均为3; 第4组均为9. 实验结果如表1所示, 由于第1组实验合理设置了卷积核的尺寸, 因此获得最好的重建效果.
为分析NLMB中不同层次特征对重建结果的影响, 依次移除MGAR模块中不同大小的卷积层, 计算重建HR图像的峰值信噪比(Peak signal-to-noise ratio, PSNR). 计算结果如表2所示, 与越小卷积核对应的HFEB产生的层次特征对重建结果影响更大, 即更深层的HFEB产生的层次特征, 对重建结果的影响更大.
下面分析MGAR模块相比于普通单尺度重建模块的优势. 由于使用了类似深度反向投影网络 (Deep back-projection networks, DBPN)[22]方法的采样方式, 所以在DBPN上进行实验, 并且用MGAR模块替换原有的单尺度重建模块. 在DBPN中设置
LPA模块中未包含Sigmoid门函数. 为了解Sigmoid门函数的作用, 进行了LPA模块末尾包含和不包含Sigmoid门函数2种情形实验. 实验结果如表4所示, 带有Sigmoid门函数的LPA模块性能要低一些.
LPA模块另一个考虑的因素是: 压缩阶段和扩张阶段对应位置的跳跃连接方式, 具体参见第2.2.3节. 本文设计了3个对比实验: 实验1是直接使用残差连接; 实验2是去掉残差连接; 实验3是带有自适应参数的残差连接. 实验结果如表5所示, 实验2比实验1效果好一些, 实验3 效果最好. 说明直接引入压缩阶段的特征确实会影响LPA模块对高频信息的定位, 并且加入自适应参数能够很好地缓解这个问题.
为验证LPA模块对重建效果的影响, 进行以下两种情形的对比试验: 在HFEB的EM模块中, 包含和不包含LPA模块. 实验结果如表6所示, 可以看出有LPA模块效果更好. 说明LPA模块确实对重建效果有帮助.
ACR连接参见图1(a). 为了观察ACR连接的有效性, 分别在NLMB中使用ACR连接、残差连接和级联连接进行对比实验, 实验结果如表7所示.
从表7可以看出, 残差连接优于级联连接, ACR连接效果最好. 由此可见, 使用自适应的级联残差能更有利地进行特征重用, 改进了SISR的重建性能.
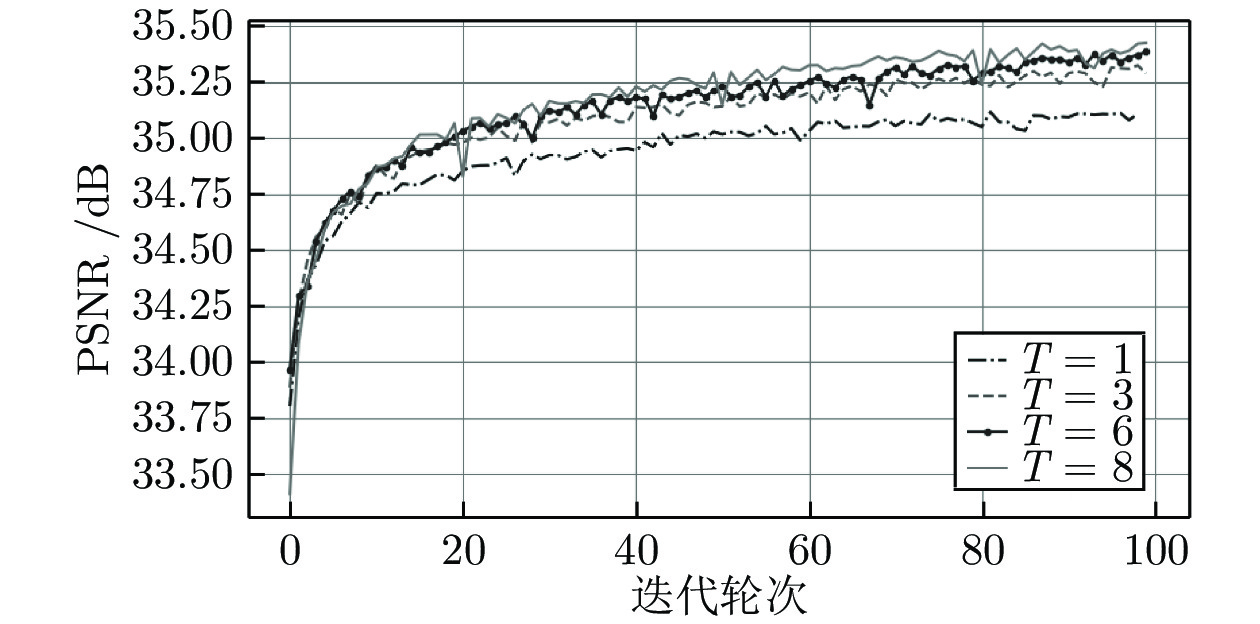
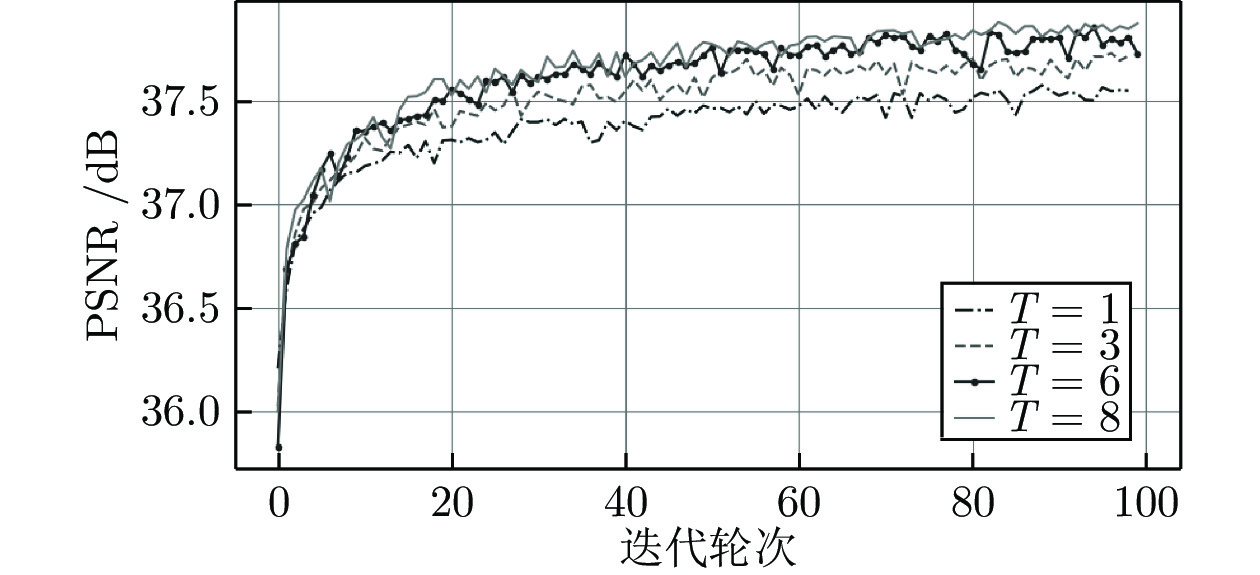
为了探索NLMB中HFEB的个数(表示为
为了进一步精确
本文ACAN方法与高分辨率图像 (High resolution, HR)、双三次插值 (Bicubic interpolation, Bicubic)、SRCNN、LapSRN、SRFBN-S、CARN、FSRCNN、VDSR和SRMDNF 9个方法进行主观效果比较.
1)客观定量结果. 本文ACAN方法与SRCNN[4]、快速超分辨率卷积神经网络(Fast super-resolution convolutional neural networks, FSRCNN)[18]、极深卷积神经网络(Very deep convolutional networks, VDSR)[16]、DRCN[6]、拉普拉斯金字塔超分辨率网络(Laplacian pyramid super-resolution network, LapSRN)[30]、DRRN[7]、MemNet[8]、用于多重无噪衰减的超分辨率网络(Super-resolution network for multiple noise-free degradations, SRMDNF)[31]、CARN[9]和SRFBN-S[5]10个当前类似的先进方法进行比较, 同时采用自组方法[32], 进一步提高ACAN的性能(称为ACAN+). 采用共同的客观度量标准: 平均峰值信噪比(PSNR) 和结构相似性(Structural similarity index, SSIM)[33], 计算结果如表9所示. 最好结果与次好结果分别用加粗和下划线标出. ACAN+的平均PSNR和SSIM度量显著优于其他方法, 包括之前最好的方法CARN, 而在 × 2情况下参数量大约只有其一半. 即使未使用自组方法, 本文ACAN方法也优于其他所有的方法. 本文方法性能提升的原因主要有: ACR连接、LPA模块和MGAR模块发挥了作用. LPA模块能够更加精准地选择高频特征信息, MGAR模块能够充分利用多尺度的特征信息, ACR连接更有效地进行特征重用, 这些因素导致了本文ACAN方法性能的显著提高.
2)主观效果比较: 如图9所示: 第1组图是Urban 100数据集中的image 024在 ×4下的比较结果; 第2组图是Urban 100数据集中的image 061在 ×4下的比较结果; 第3组图是Urban 100数据集中的img 092在 ×4下的比较结果. ACAN方法显著优于其他方法. 以Urban 100中的img 061图像为例, 在放大因子为4的情况下, 对于图中玻璃上难以恢复的网格细节, SRFBN-S、CARN和SRMDNF方法都遭遇了严重的失真, SRCNN方法的重建图像遭遇到严重模糊. 而ACANCAN几乎完美地恢复了原HR图像中纹理和网格信息. 在放大因子为4的情况下, 另外两个图像的结果也与img 061图像的结果类似. 本文方法之所以能够更好地重建纹理和网格信息, 主要得益于ACR连接、LPA模块和MGAR模块. ACR连接能够有效地重用特征; LPA模块能够准确定位特征中的高频信息; MGAR模块能够利用多尺度层次特征. 因此, 能够更好地恢复规则的形状和结构[34]. 由于Urban 100数据集中, 包含较多建筑物的规则结构[22], 本文方法性能提升显著. 如何进一步提升不规则的形状和结构重建效果, 仍是有待研究和解决的问题.
本文提出了一个新的轻量级单图像超分辨率方法, 使用自适应级联的注意力网络(ACAN) 能够高质量重建超分辨率图像. 本文的局部像素级注意力(LPA)模块, 通过对输入特征进行像素级的高频信息定位, 加强了特征流动过程中对高频特征信息的选择能力; 本文的多尺度全局自适应重建(MGAR)模块, 使用不同尺寸的卷积核, 能够自适应地选择和组合多尺度的特征信息; 本文的自适应级联残差(ACR)连接, 能够自适应地组合不同层次特征. 充分的实验结果也验证了ACAN方法的良好性能.