 0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

局部时差约束邻域保持嵌入算法在故障检测中的应用
在现代工业过程中,系统规模越来越大,流程也越来越复杂[1-2],一旦故障发生,不仅会影响生产效率,甚至会造成重大的安全事故。同时,随着传感器技术、实时存储技术和信息管理系统的发展[3],大量在线和离线数据更易被获取和存储[4-5]。因此,为了保证工业过程的生产安全,数据驱动的过程监测和控制技术越来越受关注[6],多元统计过程监控(multivariate statistical process monitoring,MSPM)方法作为数据驱动过程监控方法的典型代表,得到了广泛的研究[7]。目前常用的MSPM方法有主成分分析(principal component analysis,PCA)、偏最小二乘(partial least squares,PLS)、独立主元分析(independent component analysis,ICA)等,这些方法对过程数据进行降维[8-11]并基于提取的特征信息建立模型。然而,这些方法仅考虑样本间的全局特性,并没有关注局部包含的结构关系,这将忽略隐藏在高维空间中的更多信息。
近年来,基于流形学习的方法得到快速发展[12],拉普拉斯特征映射(Laplacian eigenmaps,LE)[13]、局部线性嵌入(locally linear embedding,LLE)[14]和等距映射(isometric feature mapping,ISOMAP)[15]等非线性流形学习算法被提出,这些方法可以从高维采样数据中揭示低维流形结构以实现维数的约简,但运算成本高且得到的投影仅在训练数据上定义。He等[16]提出局部保持投影(locality preserving projections, LPP),它作为一种线性流形学习算法,对LE算法进行线性近似,不仅保留了诸如LE、LLE非线性算法的数据属性,还可以被定义在环绕空间的任何地方,而不仅限于训练数据中。He等[17]进一步提出邻域保持嵌入(neighborhood preserving embedding, NPE),也是通过邻域近似线性表示得到投影矩阵,但目标函数表示为最小化重构误差,目前也成功应用于故障检测领域[18-21]。但无论是关注全局结构信息的典型多元统计方法还是关注局部结构信息的流形学习方法,它们都基于数据样本独立分布的假设建立静态模型,忽略了样本在连续时间采集过程中的相关性[22]。
在实际工业中,变量可能受到噪声等干扰使其在稳态值附近波动,该过程便具有动态行为特征。Ku等[23]提出动态主成分分析算法(dynamic PCA, DPCA),通过加入时间延迟因子的方法来表示模型中的动态行为,利用时间窗将连续时间的样本依次排列,形成增广矩阵作为模型训练的输入。Li等[24]提出动态邻域保持嵌入(dynamic neighborhood preserving embedding,DNPE)算法将原始数据矩阵转换为增广数据,既保留了NPE算法的优势又克服了无法考虑时序相关性的问题,然后利用LSSVM方法实现对数据的多类评价。赵小强等[25]提出GSFA-GNPE算法,通过计算顺序相关矩阵,对过程变量的特性进行评估,划分为动态子空间和过程子空间,根据得到的混合模型指标实现过程监控。但是,这些算法广泛关注的是样本的全局时间特性,并没有充分挖掘局部时间特性。
针对全局结构信息无法准确反映样本间关系和时序相关性未被考虑两个问题,本文在传统NPE算法基础上提出一种新的数据降维和特征提取方法——LTDCNPE算法,它使用一种全新的方式选择近邻样本来对原始样本进行重构。不同于大部分算法单纯使用欧氏距离的大小来选择邻域,很多距离小的样本可能时间尺度上相隔较远,导致邻域中选择了时间上关系很小但距离相隔很近的样本,这在一定程度上会影响特征的提取。LTDCNPE算法同时兼顾时序相关性和局部空间结构信息,任意选取一个样本作为中心点,根据样本时间上的相关性大小选定一个长度固定的时间窗,再利用中心点与时间窗内其他每个采样点之间的时间关系和二者之间的距离,来构造更加合理的邻域选择标准,并将时间关系作为近邻样本的权值,来提高系统的故障检测精度。本文将LTDCNPE算法用于工业过程的故障检测,分别在特征空间中构造
1 NPE算法介绍
NPE算法通过求解特征映射
首先,利用k-NN方法为原始训练数据
式中,
然后,通过特征映射矩阵
根据低维空间可以利用与在原始高维空间中相同的权值进行重构这一特点,利用
式中,
最后,利用拉格朗日乘子法进行转换,将
获得的前
2 基于LTDCNPE的故障检测
NPE算法根据样本之间的欧氏距离选择邻域来对中心样本进行重构,但是在化工过程中,一段时间内的连续样本之间具有时序相关性[26]。传统的NPE方法仅考虑样本间的空间关系,忽略了样本间的时序关系,使得检测效果变差。因此,本文将提出的LTDCNPE算法用于化工过程故障检测,希望在一个时间窗内通过同时考虑时间和空间上的局部性来进行邻域挑选,并利用时差为近邻样本赋权,进而提取更为合理的特征。
2.1 LTDCNPE算法
2.1.1 挑选邻域
在选择邻域前,LTDCNPE算法先对选择的范围进行了预缩减,根据连续过程样本间的时序相关性寻找一个长度为
但通过时间窗得到的缩减邻域所包含的样本并非全部适合重构
式中,
LTDCNPE算法和NPE算法对空间结构上的特征提取均是利用
图1

图1 仅考虑空间距离的样本分布
Fig.1 Sample distribution considering only spatial distance
LTDCNPE算法中的局部时差由
式中,
具体地,在
对照以上分析,将图1中的中心样本及其邻域投影到时间轴上,此时的示意图如图2(a)所示。当考虑了邻域样本的局部时序关系后,该算法将图2(a)中距离中心样本近而时间相隔较远的样本剔除,并选择在时间和空间两种约束下更为紧密的近邻样本,如图2(b)所示,可以看出
图2
图2 时间投影上的样本分布
Fig.2 The sample distribution on the time projection
2.1.2 邻域加权
当在时间窗中根据
然后,用于训练的样本变量经过
式中,
2.1.3 计算权值系数矩阵和映射矩阵
利用时间关系为近邻样本加权后,按
利用
2.2 使用LTDCNPE进行故障检测
为了提高故障检测模型在化工过程中的监控效果,本文使用提出的LTDCNPE算法获得投影矩阵
其中,
因为核密度估计(kernel density estimation, KDE)方法[28-29]使用方便且具有更普遍的意义,本文使用该方法估计统计量的控制限,假设
在已知
式中,
基于LTDCNPE算法进行离线建模和在线监控的具体实施步骤如下。
离线建模阶段:
(1) 以正常数据
(2) 利用
(3)
(4) 利用
(5) 根据最小化公式
(6) 根据
在线监控阶段:
(1) 获取新样本
(2) 利用离线建模步骤(5)获得的特征映射矩阵
(3) 计算新样本的
3 仿真实验
为了说明LTDCNPE算法的有效性,本文使用数值例子和TE仿真实验进行故障检测,并将所提出算法的性能与经典算法PCA、NPE及其时间相关的衍生算法DNPE[24,30-31]进行了比较。
3.1 数值例子仿真
本文采用Ku等[23]提出的多元动态过程来验证所提方法的有效性:
式中,
式中,
表1 过程故障描述
Table 1
| 故障 | 描述 |
|---|---|
| 1 | 对 |
| 2 | 系数矩阵 |
新窗口打开| 下载CSV
测试集中各算法的漏报率(miss alarm rate, MAR)总结在表2中,用粗体数值表示检测结果的最优值。由表2可以看出当故障1发生时,PCA算法和NPE算法的
表2 数值例子的漏报率
Table 2
| Fault | MAR/% | |||||||
|---|---|---|---|---|---|---|---|---|
| PCA | NPE | DNPE | LTDCNPE | |||||
| SPE | SPE | SPE | SPE | |||||
| 1 | 58.67 | 1.33 | 62.00 | 2.00 | 1.00 | 1.32 | 0.33 | 2.00 |
| 2 | 1.67 | 1.67 | 1.67 | 1.67 | 1.66 | 1.66 | 1.39 | 1.67 |
新窗口打开| 下载CSV
图3是四种方法针对故障1数据的二维投影结果。可以看出,图3(a)~(c)的故障样本投影后有接近一半超过椭圆控制限,使正常样本和故障样本在二维投影平面上大量重叠,无法进行区分。而LTDCNPE算法可以通过椭圆形的控制限将测试数据中的正常数据和故障数据很好地分开,两部分数据几乎没有重叠,表明数据中的时间序列在低维空间中得到了较好的保留和利用,从而提高了映射空间的质量。图4是四种方法针对故障1数据的控制图。其中,图4(a)、(b)的
图3

图3 数值例子故障1的
* 正常样本;〇 故障样本;— 控制限
Fig.3
图4
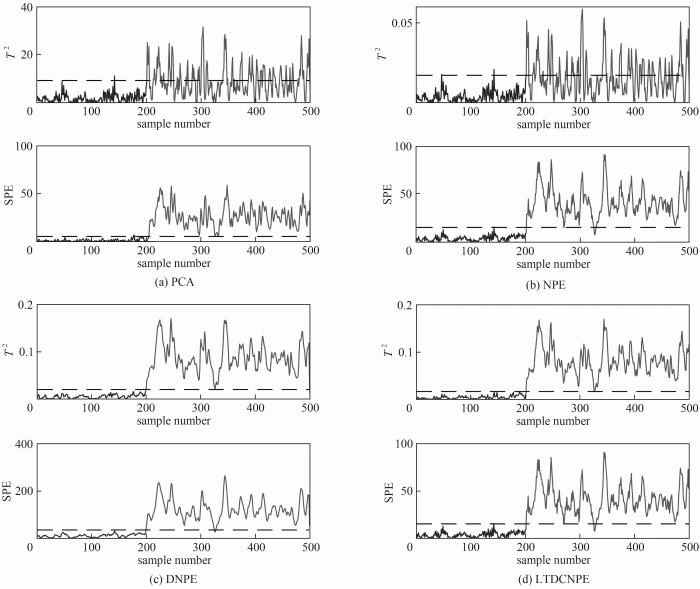
图4 数值例子故障1的控制图
Fig.4 Control diagram of fault 1 in case study
3.2 TE过程仿真
TE过程是对实际工业过程的模拟,该平台广泛应用于控制技术和监测方法的开发、研究和评价[1,10,32-33]。该工艺过程包括反应器、冷凝器、压缩机、分离器和汽提塔5个主要生产单元[34],8种成分,22个连续过程变量,19个成分变量,12个控制变量,21种故障。由于实际过程中的搅拌速率和成分变量很难实时采集,因此选用剩余的33个变量作为监控的连续过程变量。故障4为反应器冷却水入口温度的一个阶跃变化,但在实际中相当于过程中的干扰而非故障;故障3、9、15的数据在均值方差和高阶矩上均没有可以被观测到的变化[35],难以检测且对监测过程影响较小,因此本文选取剩余的17种故障进行在线检测。在此基础上,采集正常工作模式下的960个样本作为训练数据,各种故障均在第161个样本引入并收集960个样本作为训练样本。
在设置实验参数时将所有算法统计量的置信度设置为
为了更加全面地对比LTDCNPE算法和其他算法在实际中的有效性和可行性,本节不仅使用漏报率来对TE过程的17种故障数据进行故障部分的检测,还利用误报率(fault alarm rate,FAR)来检验不同算法对正常数据的效果。在表3中,误报率均写在括号内。根据表中数据可以看出,LTDCNPE算法总体上提供了较低的漏报率。对于容易检测的故障,四种算法的结果均能得到令人满意的结果;对于初始阶段难于检测的故障10、16、19、20,三种对比方法的漏报率均很高,在实际应用中无法提供可靠的报警,而LTDCNPE算法的漏报率仍能保持较低数值。从误报率角度来看,PCA的误报率相对其他三种方法偏高一点,其他三种方法的误报率相差不大,整体上数值都比较低,说明对正常数据有较好的检测效果。
表3 TE过程17种故障的漏报率和误报率
Table 3
| Fault | MAR(FAR)/% | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PCA | NPE | DNPE | LTDCNPE | ||||||||
| SPE | SPE | SPE | SPE | ||||||||
| 1 | 0.88(0) | 0.13(0.63) | 0.88(0) | 0.75(0) | 0.13(0) | 0.50(0) | 0.25(1.25) | 0.75(0) | |||
| 2 | 1.63(1.25) | 4(1.25) | 1.63(1.25) | 1.75(0) | 1.25(0) | 1.75(0) | 1.50(0) | 1.75(0) | |||
| 5 | 75.88(0.63) | 75.88(3.13) | 76.25(0.63) | 75.38(0.63) | 0(1.25) | 76.32(0.63) | 0(0) | 77.25(0.63) | |||
| 6 | 0.88(0) | 0(1.88) | 0.75(0.63) | 0(0) | 0(1.88) | 0(0.63) | 0(0) | 0(0) | |||
| 7 | 0(0) | 0(2.50) | 0(0) | 0(0) | 0(1.25) | 0(1.25) | 0(0.63) | 0(0) | |||
| 8 | 3.13(0) | 13.88(0.63) | 3.25(0) | 2.50(0) | 2.26(0) | 2.51(0) | 2.25(0) | 2.50(0) | |||
| 10 | 70.38(0) | 70.88(1.25) | 70.63(0) | 60.63(0) | 46.49(0.63) | 61.40(0) | 12(1.25) | 61.13(0) | |||
| 11 | 59.38(0.63) | 23.88(3.13) | 59.25(0.63) | 45.50(0.63) | 57.39(0.63) | 42.61(0) | 38.13(0.63) | 45.50(0.63) | |||
| 12 | 1.63(0) | 9.25(3.13) | 1.63(0.63) | 1.63(0) | 0.38(0) | 1.00(0) | 0.13(1.88) | 1.63(0) | |||
| 13 | 6.38(0.63) | 4.75(1.25) | 6.25(0) | 5.75(0) | 5.51(0) | 5.64(0) | 4.75(0.63) | 5.75(0) | |||
| 14 | 0.75(0) | 0(1.25) | 1.25(0.63) | 0.13(0) | 0(0.63) | 0(0.63) | 0(0.63) | 0.13(0) | |||
| 16 | 86.50(3.75) | 67.75(2.50) | 84.88(3.13) | 78.75(5.63) | 55.26(1.88) | 81.20(1.88) | 8.88(7.50) | 79.25(5.63) | |||
| 17 | 23.75(1.25) | 4.13(2.50) | 24.50(1.88) | 14.13(0) | 14.29(0) | 14.29(0) | 9.13(0) | 14.13(0) | |||
| 18 | 10.75(0) | 9.75(2.50) | 10.63(0) | 10.75(0) | 10.78(0.63) | 10.65(0) | 9.63(0.63) | 10.75(0) | |||
| 19 | 89.00(0) | 82.25(0.63) | 88.38(0) | 98.13(0) | 71.43(0) | 100(0) | 22.00(0.63) | 98.13(0) | |||
| 20 | 68.25(0) | 48.38(4.38) | 65.13(0) | 57.88(0) | 50.50(0) | 58.90(0) | 11.00(0) | 58.38(0) | |||
| 21 | 60.75(0) | 51.13(5.00) | 60.50(0) | 61.75(0) | 51.13(0.63) | 62.91(0) | 42.00(3.13) | 61.75(0) | |||
新窗口打开| 下载CSV
因此,综合测试数据的漏报率和误报率可以看出,LTDCNPE法在故障检测过程中具有更佳的效果。与仅考虑空间结构关系的传统算法PCA和原始NPE算法相比,LTDCNPE算法明显降低检测的漏报率,与处理全局时序过程的DNPE算法进行对比,LTDCNPE算法的效果也更为显著,保留了更多的数据特征。
为了更直观地表明LTDCNPE算法的优势,图5和图6展示了故障5、故障10两种典型故障的检测结果。故障5是冷凝器冷却水的入口温度产生的阶跃变化。该故障的显著影响是引起冷凝器冷却水流量的阶跃变化。当故障发生时,从冷凝器出口到汽/液分离器的流速增加,导致汽/液分离器的温度升高,并使分离器冷却水出口温度也升高[37]。但是控制回路能够补偿这个变化,并使分离器中的温度返回到设置点。由图5可以看出PCA算法和NPE算法虽然在故障初始阶段能及时地反映出故障,但随着过程的推进,统计量又逐渐降低到控制限以下,而此时过程中的故障仍然存在,所以无法持续进行故障的监测。这表明一旦忽略了实际过程中的时序特性,无论使用全局数据还是利用局部信息建立模型,都无法实时反映过程的真实状态。而四种方法的SPE统计量都是先超限持续一段时间后又回到正常,这与33个变量特征提取和变换时被赋予的权重大小有关。对于故障5中先发生异常后恢复至原始状态的变量,其对应的权重较大,而保持稳定的变量以及一直保持故障状态的变量所对应的权重在大多情况下数值较小,保留的信息较少,使得这部分变量的信息被掩盖在了可恢复正常变量的信息中。所以最终SPE统计量的变化也符合这个变化趋势,使SPE数值最终回到正常范围内,无法很好区分正常和故障时候的数据。
图5
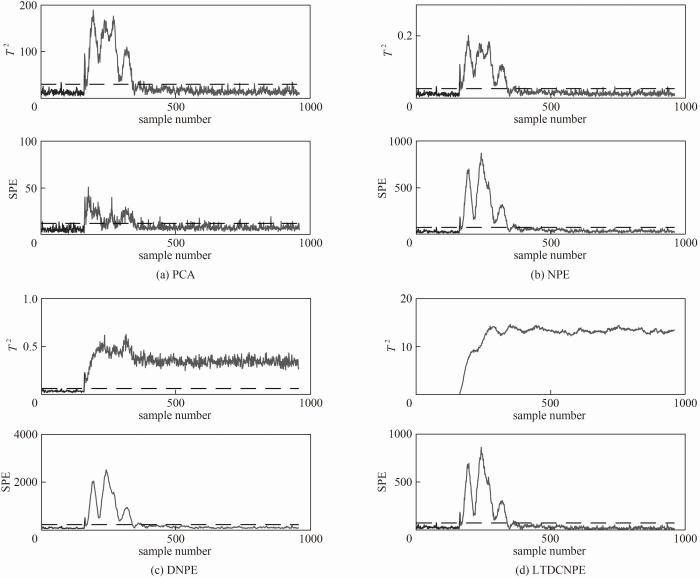
图5 故障5的TE过程检测结果
Fig.5 Monitoring results of the Tennessee Eastman process for fault 5
图6

图6 故障10的TE过程检测结果
Fig.6 Monitoring results of the Tennessee Eastman process for fault 10
故障10为一种随机故障,过程中的某些变量在不同时刻随机进行变化,检测结果如图6所示。在故障发生的初期,图6(d)中的
由数值例子实验结果可以看出,LTDCNPE算法可以有效识别阶跃故障和随机故障,并且相比于其他方法,具有更高的准确率。由TE平台的实验结果可以看出,PCA算法使用全局数据建立的模型无法实时地反映过程的真实状态;NPE算法作为一种较为原始的利用局部信息进行建模的方法,忽略了实际过程拥有的时序特性;DNPE算法构建增广向量,通过消除输入变量的相关性来考虑样本的自相关性,但它仍未很好地捕捉到数据间的时变。LTDCNPE算法克服了以上算法的缺点,可以同时提取数据中的局部结构和时序信息,对各类故障均能够做出反应,快速捕捉过程的变化,结果符合实际生产需求。
4 结论
本文提出一种基于LTDCNPE算法的工业过程故障检测方法,通过关注局部时差和局部几何结构,克服了传统PCA算法和NPE算法仅考虑不同样本空间距离的缺点,改进了DNPE算法提取时间特征的方式。LTDCNPE算法使用一种新的邻域选择方法,从时间和空间角度进行考虑,挑选出更加合适的近邻样本对原始样本进行重构,并利用它们的时序差异为近邻样本进行加权,尽可能保留原始数据的结构关系,降低信息的丢失程度。通过对比PCA、NPE、DNPE、LTDCNPE算法在数值例子和TE仿真实验中的结果,可以看出LTDCNPE算法挑选的时序特征更加合理,并且其在降维和检测效果上的表现也得到了验证。
符号说明
| 特征映射矩阵, | |
| 局部时间空间差异矩阵, | |
| 空间约束矩阵, | |
| 输入变量数 | |
| 降维后的维数 | |
| 最小化重构误差 | |
| 带宽 | |
| 单位矩阵, | |
| 核函数 | |
| 构造邻域连接图所需的近邻样本数 | |
| 样本具有时序相关性的时间窗长度 | |
| 邻域尺度 | |
| 选取的特征值数量 | |
| 输入样本数 | |
| 归一化的时间约束矩阵, | |
| 密度函数 | |
| 时间约束矩阵, | |
| 邻域中近邻样本与中心样本之间的采样时差 | |
| 样本对应的采样时间 | |
| 最优权值系数矩阵, | |
| 输入矩阵, | |
| 新样本, | |
| 特征矩阵, | |
| 新样本对应的特征向量, | |
| 近邻样本加权后的矩阵, | |
| 上角标 | |
| 邻域中样本的近邻样本序号 | |
| 下角标 | |
| 输入样本序号 | |
| 构造邻域连接图的样本序号 | |
| 重新选取的构造邻域连接图的样本序号 |

- 我用了一个很复杂的图,帮你们解释下“23版最新北大核心目录有效期问题”。
- 重磅!CSSCI来源期刊(2023-2024版)最新期刊目录看点分析!全网首发!
- CSSCI官方早就公布了最新南核目录,有心的人已经拿到并且投入使用!附南核目录新增期刊!
- 北大核心期刊目录换届,我们应该熟知的10个知识点。
- 注意,最新期刊论文格式标准已发布,论文写作规则发生重大变化!文字版GB/T 7713.2—2022 学术论文编写规则
- 盘点那些评职称超管用的资源,1,3和5已经“绝种”了
- 职称话题| 为什么党校更认可省市级党报?是否有什么说据?还有哪些机构认可党报?
- 《农业经济》论文投稿解析,难度指数四颗星,附好发选题!
- 期刊知识:学位论文完成后是否可以拆分成期刊论文发表?
- 号外!出书的人注意啦:近期专著书号有空缺!!

