0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

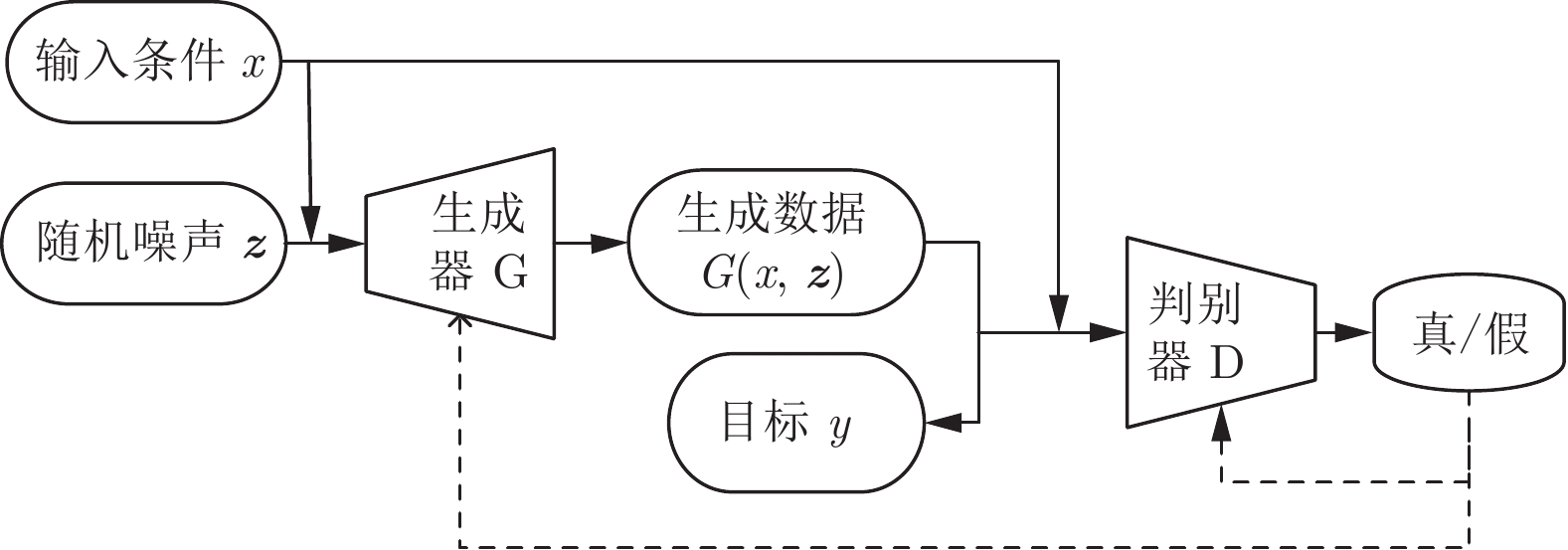
图 1 CGAN基本框架
Fig. 1 Basic framework of CGAN
书法是汉字文化的精髓, 学习书法是一个非常复杂的过程, 人们通过描红、临摹等方法学习名家的书法风格. 学习书法需要先摹后临, 循序渐进, 对于有一定书法基础的人, 当以临帖为主. 临帖有几个阶段: 临贴、背贴、核贴. 临帖在书法练习中是最为重要也是最有挑战性的. 临帖初期要求模仿作品和范本有很高的相似度, 许多书法爱好者在核贴过程中, 并不能及时有效地发现自己的不足, 也没有条件寻求名师一一指点. 因此, 找到一种通用性强的算法, 在核贴环节让练习者更轻松地进行比对笔画和结构, 是一件非常有意义的工作.
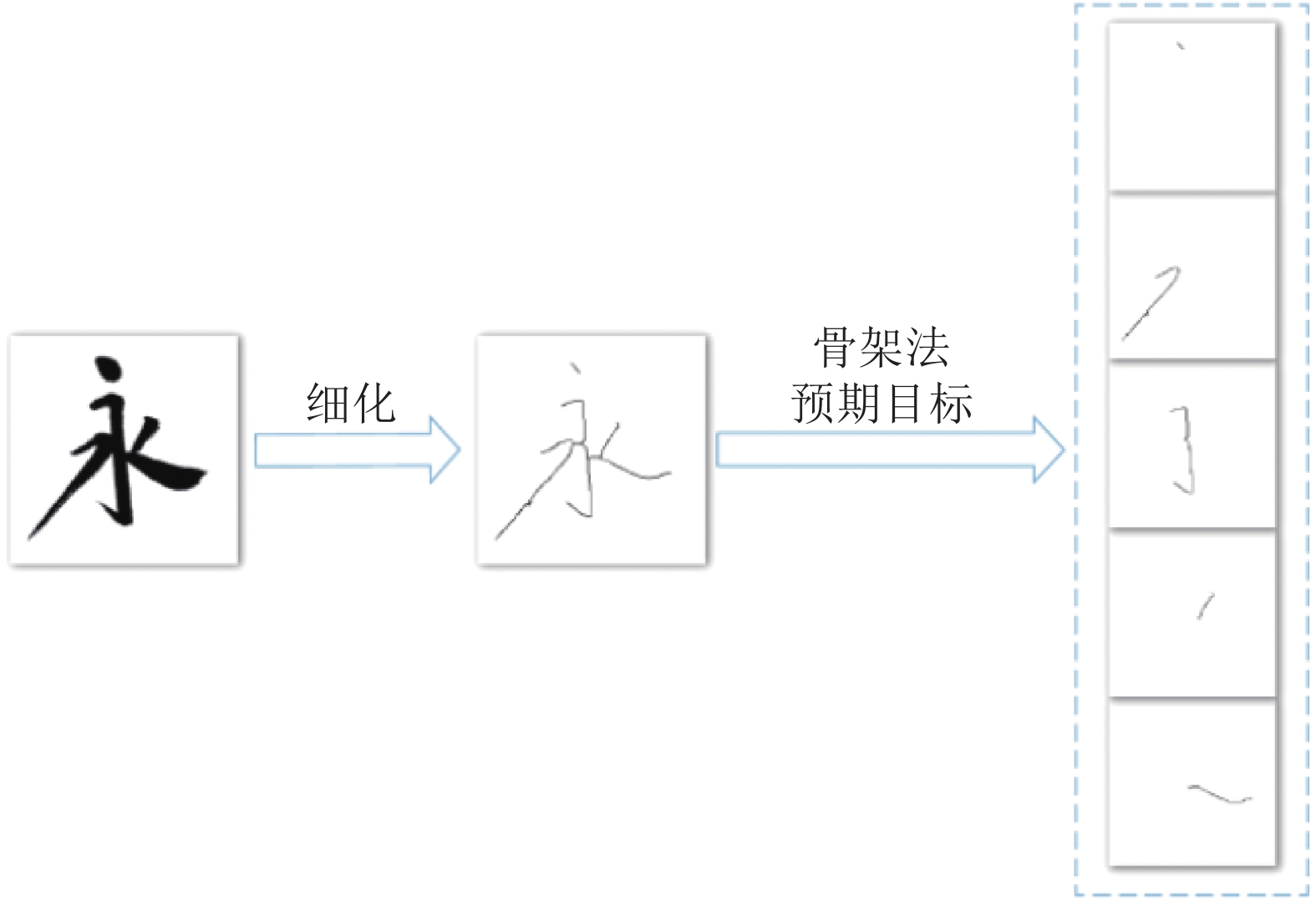
本文通过调查手机和平板的应用商店发现, 大部分书法学习软件只是提供名家字帖, 教学视频, 以及利用触屏的虚拟毛笔描红练习, 欠缺实体笔墨的实践和细致的书法评价, 对书法练习者有一定的借鉴意义, 但实际作用不大. 没有针对写在纸上的书法进行评价的软件, 最主要的原因是笔画提取比较困难, 缺乏将书法笔画拆分开的算法. 传统的汉字笔画提取方法有两种, 一是应用骨架化的方法, 另一种是底层像素特征的方法. 其中, 骨架化就是将字符图像中所有线段图案的宽度减小为一个像素的过程[1], 目前有细化, 中轴变化和形态学方法[2].
计算机识别领域很多应用场景是通过骨架化来识别物体, 提取汉字骨架, 有利于对图像数据进行压缩, 进一步分析汉字的结构. 压缩后的数据虽然提高了对书法图像处理的速度, 但是, 单纯的骨架提取得到的只是底层信息, 并不能反映毛笔笔锋、运笔的力度等高层语义信息, 丢失了书法字体的很多属性, 也失去了毛笔书法的灵魂.
常见的骨架法步骤是[3-4]先对骨架段进行删除、合并, 再用模板匹配法分析交叉,但在判定是否删除与合并时常有误判. 如何保证良好的连通性,保持物体原有的拓扑结构又能减弱边界噪声的影响[2, 5]也是目前骨架提取研究的难点. 另一种方法是利用底层像素特征, 提取的对象主要有灰度图、二值图和轮廓图. 其中, 从灰度图中提取笔画的时间复杂度最高. 它的主要优点是笔画的灰度大小能够反映书写时的笔画轻重, 对于轻微的笔画多余连接, 能够根据连接处的灰度对比等信息解决. 但是实际操作的效果受光照条件、纸张材料等环境因素较多. 轮廓法提取笔画也是常见的做法, 它利用笔画两侧轮廓的相对位置和大小关系来提取笔画, 较适用于笔画宽度稳定的印刷体汉字[1, 6-8]. 但是鲁棒性不强, 很容易受到伪角点的影响. 轮廓法的关键是: 通过定位角点(拐点)来定位交叉区, 再对交叉区进行分类, 并进行笔画分离. 这种方法用在没有固定书写模板的书法字上会出现角点的误判, 想要判定许多飞白或枯笔产生的角点是伪角点, 则需判别此处并没有交叉笔画, 而用轮廓法判别交叉笔画的方式就是检测角点, 两者互相矛盾[5], 很难在实际情况下应用.
当代的人工智能研究者一直致力于研究让计算机赋有创造力, 本文正是利用机器学习的创造力来解决书法字的笔画分割问题. 深度学习中的无监督模型近年来受到越来越多的关注, 变分自编码器(Variational auto-encoder, VAE), 生成对抗网络(Generative adversarial network, GAN)[9]等无监督模型受到越来越多的关注. GAN由生成器生成观测数据, 判别器估计观测数据是否来源于生成器, 预测结果用来调整生成器的权重. 因为GAN可以进行对抗操作, 高效的自学习, 符合人工智能发展的趋势, 近年来, 基于GAN的研究方法越来越丰富[10], 可以应用于全景分割, 修复图像和超分辨率重建[11-13]. 其中常见的条件生成对抗网络(Conditional generative adversarial network, CGAN)是在GAN的基础上加入了辅助信息, 用来控制数据的生成.
本文通过条件生成对抗网络, 对笔画进行精确分割, 可以得到局部和整体的可视化结果, 用于后续评价, 让练习者可以进一步对比自己练习的书法与字帖的差距.
笔画分割也可以看成是图像分割, 本文选择用图像分割算法解决笔画分割问题. 图像分割常用方法有: 阈值分割[14]、区域分割[15]、边缘检测分割[16]以及能量最小化[17]. 因为汉字笔画灰度特征单一, 笔画交叉的部分缺失边缘信息, 无法应用上述方法. 汉字作为非常复杂的几何图形, 其特征提取十分重要也十分具有挑战性. 本文针对传统骨架算法(下文简称传统算法)容易变形和容易误判等不足, 提出利用条件生成对抗网络进行笔画分割.
条件生成对抗网络(CGAN)是在GAN的基础上加上了某种条件, 利用附加信息调整模型, 指导数据生成过程[18]. 条件生成对抗网络可以很好地解决图像转换问题, 尤其是涉及高度结构化图形输出的任务, 是一种很有前途的方法. 条件生成对抗网络总体上有两个子网络组成: 生成器(G)和判别器(D), 如图1所示. 生成器的作用是输入一个随机噪声, 生成一个近似真实的样本来欺骗判别器, 使判别器无法分辨输入的数据来自真实世界还是生成器. 判别器的作用是判断输入的数据样本是来自真实世界还是生成器. 通过相互竞争, 生成器和判别器一起优化权值, 共同提升自身能力.
生成对抗网络生成一个学会从随机噪声向量z到输出图像y的映射的模型. 条件生成对抗网络学习的是观测图像x和随机噪声向量z到y的映射的模型. 训练生成器(G)产生出判别器(D)难辨真伪的输出, 其中判别器(D)被训练成尽可能检测出生成器(G)造出来的“假”图片.
条件生成对抗网络比生成对抗网络多了图片标签, 通过生成器输出的图片和人工标注图片之间的误差调整生成器的权重. 条件生成对抗网络的目标函数可表示为
| (1) |
其中, x为输入的书法字图像, y为人工分割的笔画, 函数D(x, y)表示输入的图像来自于人工分割的概率, 函数D(x, G(x, z))表示输入图像来自生成器的概率. 整个优化目标需要最大化判别网络判别器(D)判别正确的概率 同时需要最小化生成器(G)生成的样本被判别出来的概率.
| (2) |
由于L1比L2更不容易造成模糊, 所以L1范数更加常用.
| (3) |
新的目标函数结合了L1距离函数, 如式(4)所示.
| (4) |
引入超参数
条件生成对抗网络的条件可以是图片, 也可以是文本; 生成器和判别器可以是函数或者神经网络.
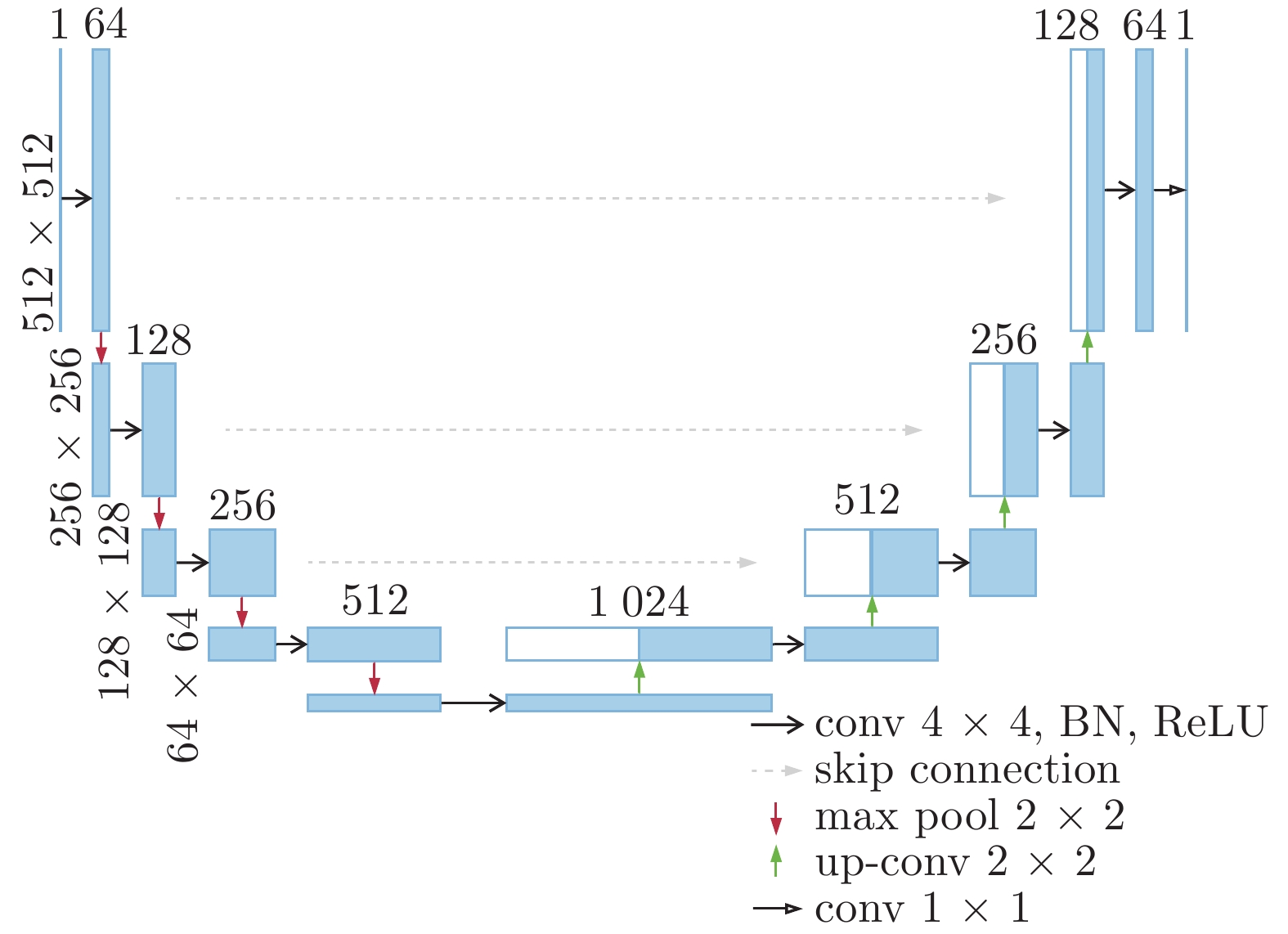
pix2pix网络属于条件生成对抗网络, 其条件为图片, 生成器为U-Net[20], 结构见图2. 在标签合成照片、从边缘重建物体、给图像着色等任务中有着广泛应用. 杜雪莹[21]提出的书法字风格迁移也用到了此网络.
为了使生成器(G)能够突破解码过程中信息冗余的瓶颈, 本文使用了跳跃连接(Skip connection), 具体操作是将网络的第
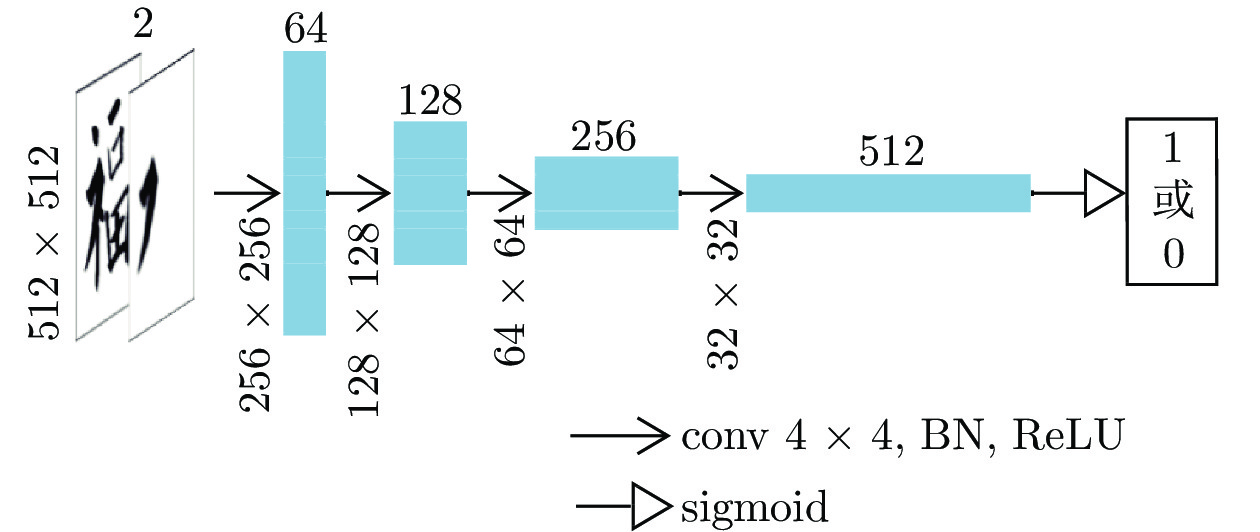
在判别器中含4×4的卷积层、批量归一化层(BN)和ReLU 激活函数, 在判别器的512通道那一层后直接用Sigmoid函数激活, 输出在0 ~ 1之间, 结构见图3.
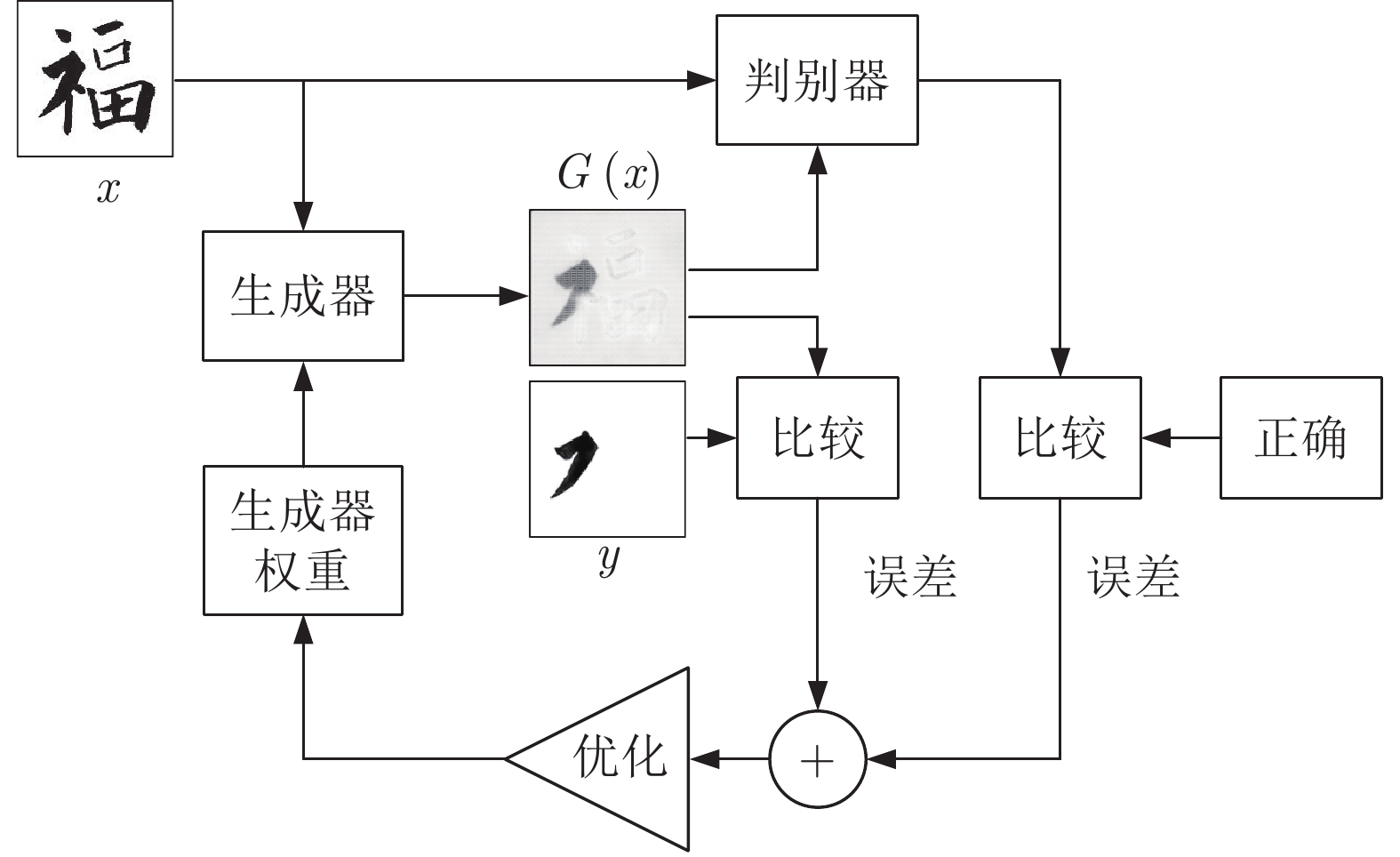
生成器的训练过程如图4所示, 通过两个途径: 1)输入一幅书法图像到生成器, 噪声采用的是dropout的形式, 比传统CGAN在输入端提供的高斯噪声更加有效. 生成器输出一幅分割后的笔画图像, 比较生成器输出的分割图像和人工标注的标准分割图像之间的差值, 通过误差调整生成器的权重; 2)将书法图像与生成器生成的分割图像输入到判别器中, 由于生成器是生成一幅无限接近于目标的分割图像, 期望判别器误认为生成器输出的分割图像是人工标注的图像. 比较判别器输出的结果(在0 ~ 1之间)与正确标准值1的差值, 从而优化生成器的权重, 使其生成的分割图像更加接近目标分割图像.
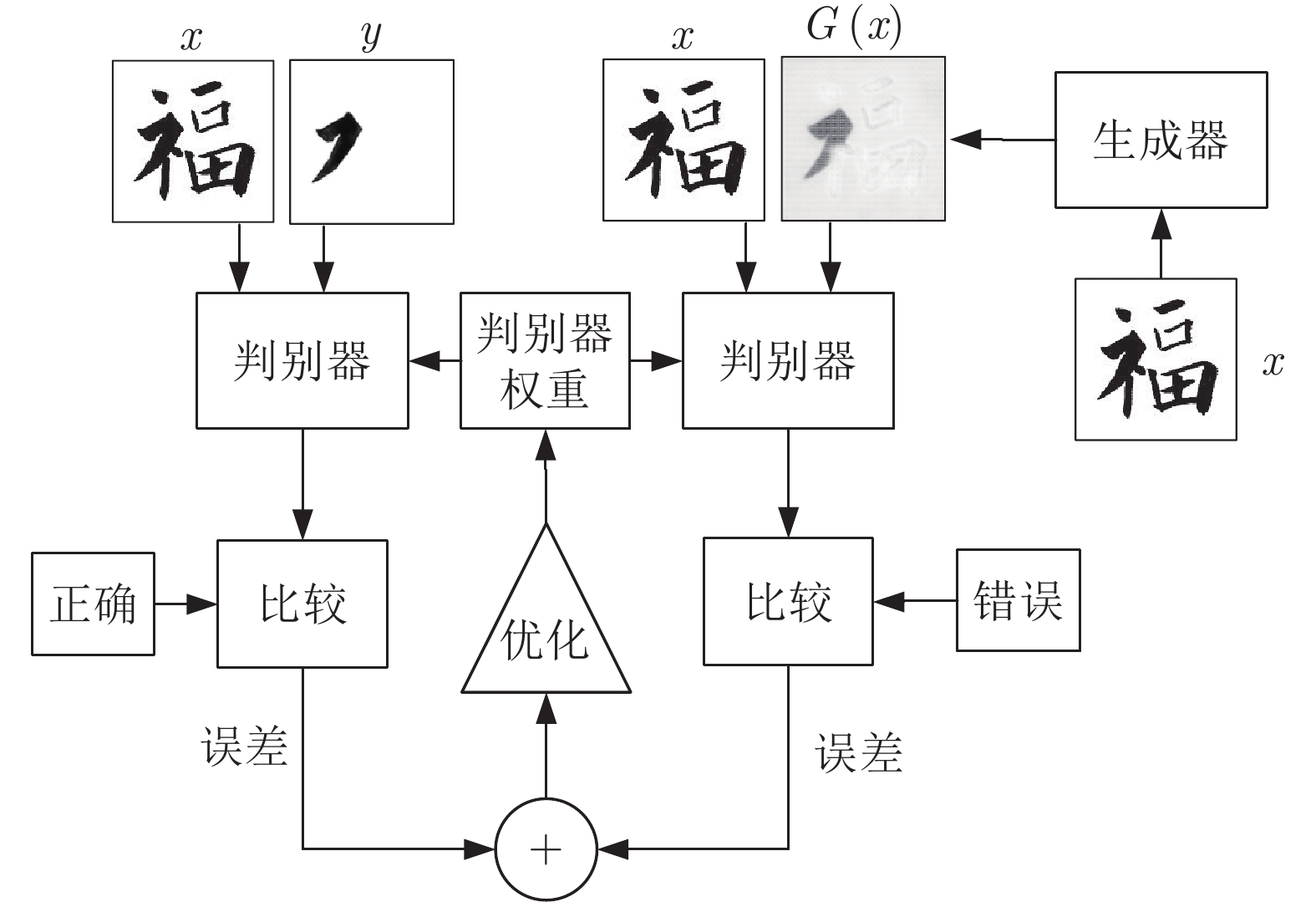
判别器的训练过程如图5所示, 也是通过两种途径调整权重: 1)输入书法图像和人工分割的笔画图像, 通过比较判别器输出的值D(x, y)与正确标准值1的差值调整权重, 使判别器的输出更接近1; 2)输入书法图像和生成器生成的笔画图像G(x), 比较判别器输出的结果
实验所用的书法图像来自书法教学机构的老师和学生, 字体均为楷体, 以“福” 字等为实验对象.
本实验训练集有120张图片, 测试集有60张图片. 训练集挑选了最具代表性的书法, 这样可以保证笔画粘连的所有情况都可以得到训练. 本文通过对图像进行旋转和水平翻转的方式对训练样本进行扩充.
基于条件生成对抗网络在图像转换上取得非常大的成功. 将此网络应用在书法分割上, 需要分成K (K为笔画数量)个问题解决. 本文将一个字的笔画分割问题细分成K个图像转换问题来开展实验.
步骤 1. 人工处理阶段, 人工分开每个字的笔画;
步骤 2. 训练阶段, 每次训练一个笔画的分割模型, 重复K次完成;
步骤 3. 测试阶段: 调用训练好的K个预训练模型, 得到分割的K个笔画;
步骤 4. 将K个笔画分别细化得到骨架, 再进行后续评价.
本文对“福”字所有13个笔画用pix2pix网络分别训练, 以第2个笔画为例进行展示. 图6为测试图像, 图7为不同代数的模型的训练效果, 图8是训练200代的损失函数. 结合图7和图8可以发现, 在第20代的时候, 提取目标已经大致确定, 在50代的时候损失函数基本上稳定.
在引入对抗机制的pix2pix网络中, 小样本的训练量已经可以让损失函数迅速下降, 笔画提取的效果非常好. 说明本算法对数据的需求并不高. 由损失函数的变化和可视化结果可知, 本算法对训练代数的要求较小, 在较短时间内即可完成训练. 除了文中展示的笔画外, 其他笔画也都基本可以还原成完整的笔画, 如图9所示.
本文的性能通过准确率(Accuracy, AC)和 F1分数进行评估. F1综合考虑精度(Precison)和召回率(Recall)两个性能指标, F1分数能够客观说明模型效果, 其值越接近1越好.
| (5) |
| (6) |
| (7) |
| (8) |
表1是60张“福” 字每个笔画的平均分割准确率, 所有笔画平均的性能由表1算出
为了方便比较本文算法与传统算法, 将二者在骨架上进行对比. 传统算法是直接细化得到, 然后再设法分开笔画, 如图10所示. 本文算法是先将所有笔画得出后, 再细化, 然后合并每个笔画得到整个字的骨架. 由图10和图11对比可见, “永” 字的传统算法最理想情况下得到的骨架仍有许多多余的分支和扭曲失真, 而本文算法几乎接近真实的骨架.
骨架法[3]在篆书中的分割准确率低于90%, 章夏芬的实验结果[5]表明隶书笔画提取的正确率还要低于篆书, 楷书更低, 而且越复杂的字分割准确率越低. 如果做书法评价的话, 准确率不高是致命的问题, 尤其是后续如何匹配每个对应的笔画. 在本文的模型中, 由于流程不同于传统算法, 避免了这些问题. 本文认为, 利用pix2pix分割笔画正确率为100%, 只是需要用F1等精度指标分析性能高低.
骨架法常常需要在细化之后合并交叉点族(如图12(b)), 才可以确定一条连通的笔画, 但这种方法误判率很高[5]. 如图12(b) (上) 所示的两对交叉点族间距离差异不大, 但位置2是需要合并的交叉点族, 位置1是需要从中间断开. 骨架法根据距离判定是否合并会误判. 用本文算法提取骨架是先分割再细化, 与传统算法步骤相反. 也因此解决了传统算法难以准确分离笔画的缺点. 而且, 传统算法并不能将细化的笔画恢复成原来的形态, 只能做单一的结构评价. 本文提出的算法保留了完整的笔画形态. 实验表明, 本文算法应用在提取笔画上几乎没有误判和失真的问题, 能提取书法的高层语义特征. 不足之处是轮廓上比原图略微模糊.
由于本文算法在拆分笔画的过程中能保证原书法字不被破坏, 高层语义信息, 如粗细、笔锋都可以保留. Hu不变矩由7个几何不变矩构成, 这些矩组对于平移、尺度变化、镜像和旋转的操作是不变的. Hu不变矩方法适用于描述图像的形状特性, 可以通过欧氏距离计算两幅图Hu不变矩的差异, 如式(9)所示.
| (9) |
图13和图14通过计算不同粗细的两个笔画的Hu不变矩[22]的欧氏距离来说明高层语义的重要性. 两幅图差异越大, 欧氏距离也越大, 图13中, 在保留笔画粗细、笔锋走势等信息的两幅图上可以看出明显差异, 所以它们间的欧氏距离也较大, 为55.01; 图14中相同两幅图像经过细化处理, 欧氏距离非常小, 为0.52, 可以认为两个笔画形状非常接近. 该实验说明了高层语义特征是书法的重要组成部分.
书法笔画的正确分割对书法练习、汉字美化、风格鉴定[23-25]等领域具有重大意义. 本文通过使用条件生成对抗网络pix2pix对书法字笔画进行分割, 解决了传统算法分割误判率高, 无法提取高层语义信息的问题. 本文方法在前期训练比较耗时, 但实际使用的时候只需要调用模型, 能做到及时响应. 同时可以保留书法的笔锋、粗细等属性, 骨架的信息也更加精确. 从应用可行性的角度来说, 本文的方法相比传统方法更具有优势.