0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

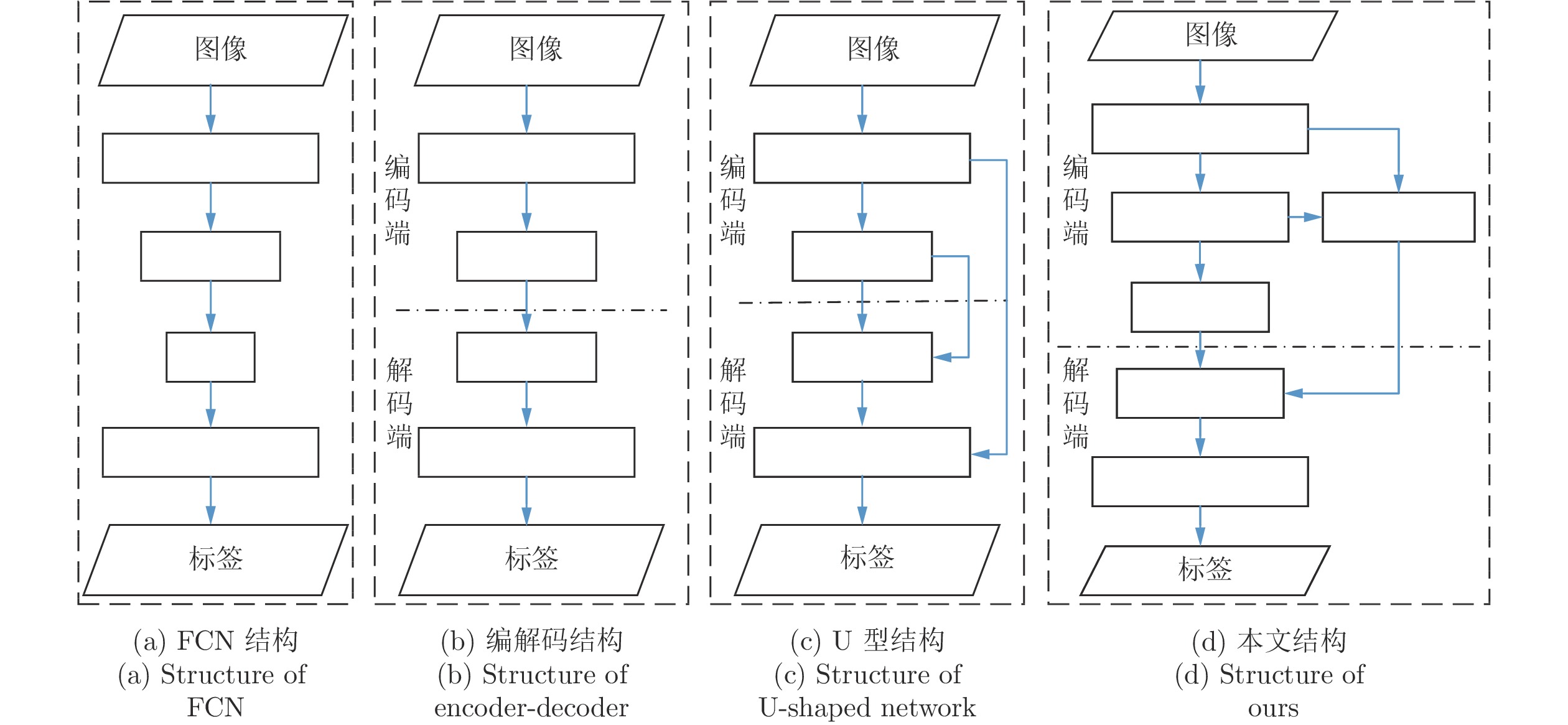
图 1 本文提出的网络结构与其他网络结构
Fig. 1 The network structures of our method and other methods
语义分割是计算机视觉基本任务之一, 其研究目的是为图像中的每一个像素点分配与之相对应的类别标记, 所以可以认为其属于像素级分类. 它主要用在多个具有挑战性的应用领域, 例如: 自动驾驶、医疗图像分割、图像编辑等. 因为语义分割涉及像素级分类和目标定位, 所以如何获取有效的语义上下文信息和如何利用原始图像中的空间细节信息是处理语义分割问题必须考虑的两个因素.
目前, 语义分割最流行的算法是采用类似全卷积网络(Fully convolutional network, FCN)[1]的形式, 如图1(a)所示, 采用这种形式的分割网络模型是将研究的重点放在提取图像的丰富语义上下文信息上. 在深度卷积网络中, 感受野大小决定着网络可以获得多大范围的语义上下文信息, 扩张卷积被用来增加网络感受野从而提升分割性能[2-4]. 为了捕捉到图像中不同尺度的目标, PSPNet (Pyramid scene parsing network)[5]通过空间金字塔方式的全局池化操作来获取多个不同大小的子区域的特征信息, DeepLabV3[6]则采用空间金字塔方式的扩张卷积. 全卷积网络结构虽然能有效获得语义上下文信息, 但它是通过池化操作或带有步长的卷积来获得, 这会导致空间细节信息的丢失, 从而影响语义分割的精度.
为了弥补空间细节信息的丢失, 许多研究工作采用编码器−解码器结构[7-9], 如图1(b)所示. 编码端通常是分类网络, 它采用一系列下采样操作来编码语义上下文信息, 而解码端通过使用上采样处理来恢复空间细节信息. 为了更好地恢复编码过程丢失的空间细节信息, 一些工作[10-12]采用了U型网络结构, 如图1(c)所示, LRN (Label refinement network)[10]和FC-DenseNet[11]在解码端通过横向连接的方式, 使用各编码块的特征信息, 联合高层语义信息恢复出图像的空间细节信息, SegNet[12]则是使用各编码块产生的最大池化索引来辅助解码端上采样特征信息. 这种结构的编码端采用传统的分类网络完成特征提取, 没有显式上下文信息提取模板, 学习到的特征可能缺少语义分割任务所须的属性. 同时, 根据可视化卷积神经网络结构[13], 网络高层特征含有极少空间细节信息, 所以在解码端过度使用编码端高层特征, 不仅不能有效地利用编码端的空间信息, 还会提升网络模型的复杂度以及计算冗余, 不利于分割算法的实时应用.
基于以上分析, 本文提出了一种基于上下文和浅层空间编解码网络的图像语义分割方法, 如图1(d)所示. 整个模型采用编解码框架, 本文的动机是在编码端即能获取高质量的语义上下文信息, 同时又能充分保留原始图像中的空间细节信息. 受BiSeNet[14]启发, 本文在编码端使用二分支策略, 上下文路径用于获取有效的上下文语义信息, 而空间路径则充分保留图像的空间细节信息, 将语义上下文信息的提取与空间细节信息的保留进行分离. 根据可视化深度卷积神经网络[13], 深度卷积网络的浅层携带大量的空间细节信息, 而高层特征基本不包含空间细节信息. 本文将空间路径设计为反U型结构, 这样能将编码网络的浅层和中层特征进行从上到下的融合, 以充分利用编码网络浅中层特征所携带的空间细节信息. 受MobileNetV2[15]启发, 本文设计了链式反置残差模块, 对编码网络浅中层特征所携带的空间细节信息进行处理, 达到保留空间信息的同时提升特征的语义表达能力. 在编码网络的上下文路径, 本文设计了语义上下文模块, 它由混合扩张卷积模块和残差金字塔特征提取模块组成. 使用混合扩张卷积模块是为了进一步提升网络感受野, 而残差金字塔特征提取模块可以获取多尺度特征信息. 在解码端, 首先对编码端的空间信息和语义上下文信息进行融合, 受R2U-Net[16]启发, 本文设计了带有残差的循环卷积网络优化模块对融合的特征进一步优化, 最后采用可学习的反卷积将优化的分割图还原到原始图像大小.
本文主要贡献为:
1)提出了基于上下文和浅层空间信息结合的编解码网络用于图像语义分割, 即能获取高质量的上下文语义信息又能保留有效的空间细节信息.
2)为了获得高效的语义上下文信息, 本文组合混合扩张卷积模块和残差金字塔特征提取模块, 以提升网络感受野以及获取周围特征信息和多尺度特征信息; 对于浅层空间信息的使用, 本文设计了反U型结构的空间路径以利用编码端浅中层特征所携带的大量空间信息. 针对编码端不同层的特征差异, 在空间路径中设计了链式反置残差模块以保留空间细节信息并提升特征的语义表达能力, 这样不仅可以弥补高层语义信息中丢失的位置信息还使得模型轻量化.
3)本文设计了残差循环卷积模块, 对语义特征和空间信息融合后的分割特征进一步优化, 提升分割性能. 本文方法在3个基准数据集CamVid、SUN RGB-D和Cityscapes上取得了有竞争力的结果.
编码器−解码器网络已经在语义分割任务中得到广泛应用, 它由编码器模块和解码器模块组成, 编码器模块逐渐减小特征图来编码高层语义信息, 而解码器模块是逐渐恢复空间细节信息. ENet[7]没有使用任何来自于编码端的信息, 直接在解码端恢复空间信息. 文献[11-12, 17]则是通过跳层连接在解码端使用编码端特征恢复空间信息. G-FRNet[18]通过门控机制对编码端各相邻模块特征进行门控选择, 再用于解码端恢复出空间信息. 为了更有效地利用编码端空间信息, 本文设计了一种反U型结构的空间路径, 以充分利用编码端浅中层特征信息中所携带的空间细节信息, 有效地提升分割性能.
最近的一些研究工作[14, 19-20]采用二分支网络结构, 即将空间信息保留和上下文信息提取放在网络中的不同分支. 网络的深层分支采用可分离卷积等轻量化操作来获取语义上下文信息, 浅层分支采用简单的卷积操作以保留有效的空间细节信息. 这种结构的网络模型更轻量化, 推动了语义分割的实时应用, 但很难提取到有效的语义上下文信息, 再加上两种特征信息差距较大, 进行融合并不能产生很好的效果. 为此, 本文使用参数适中、分类表达能力较好的ResNet-34[21]作为骨干网络, 结合本文的语义上下文模块以获取更强的语义表达能力. 对于空间细节信息, 本文充分利用编码端浅层和中层特征中所携带的空间细节信息, 而不使用高层来恢复空间细节信息, 这样能高效地使用编码端有用的空间细节信息, 并且有利于与语义上下文信息融合, 同时减小了模型复杂度.
空间金字塔模块是一种学习上下文语义信息的有效模块, 利用平行的空间金字塔池化以捕获多尺度的语义信息, 成功用于不同计算机视觉任务中, 如目标检测和语义分割等. PSPNet[5]以空间金字塔方式的池化操作, 来获取特征图中不同子区域的全局信息. 由于池化是一种下采样操作, 会严重丢失特征信息, DeepLabV3[6]以并联的方式利用不同扩张率的扩张卷积来获取多尺度上下文信息, 有效提升了分割性能, 但由于使用的扩张卷积的扩张率非常大, 最大为18, 这使得扩张卷积稀疏化严重, 提取到的特征缺少细节信息. 与他们利用空间金字塔结构的方式不同, 本文设计了混合扩张卷积模块和残差金字塔特征提取模块, 先使用混合扩张卷积模块提升网络感受野, 在获取上下文信息的同时减少扩张卷积稀疏化, 再使用残差金字塔特征提取模块, 以并联较小扩张率的扩张卷积来获取多尺度信息, 避免特征信息的丢失, 即可以增加网络感受野又可以获取高质量的多尺度特征信息.
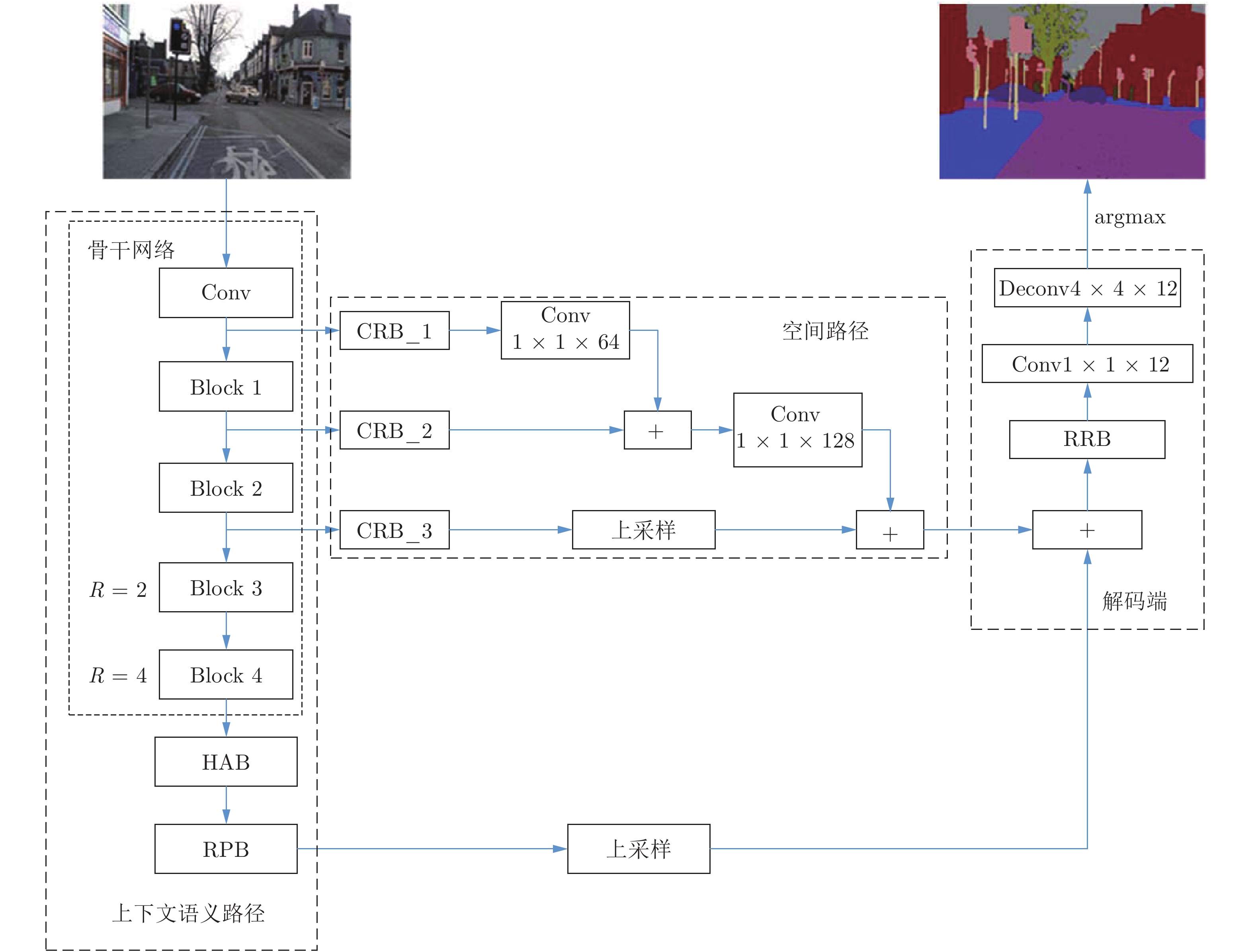
本文提出了一种新的语义分割方法, 称为基于上下文和浅层空间编解码网络的图像语义分割方法, 能够学习丰富的上下文语义信息以及获取更加有效的空间信息. 在解码端采用了优化模块进一步优化语义上下文信息与空间信息的融合特征, 帮助解码端恢复更加精准的像素级预测分割图. 整个网络结构如图2所示. 第2.1节对提出的网络结构进行整体阐述, 第2.2节论述其中的混合扩张卷积模块(Hybrid atrous convolution block, HAB), 第2.3节对残差金字塔特征提取模块(Residual pyramid feature block, RPB)进行论述, 第2.4节阐述了链式反置残差模块(Chain inverted residual block, CRB), 最后, 第2.5节论述了残差循环卷积模块(Residual recurrent convolution block, RRB).
本文网络模型采用编解码网络框架, 在编码端采用两分支方式分别获取有效的高层上下文信息和低层的空间信息. 由于深度卷积网络随着网络层数的不断加深会产生梯度消失或爆炸的现象, 这不利于深度卷积网络的学习和训练, 而ResNet[21]网络通过在每个模块之间添加跳层连接方式, 避免了梯度消失问题同时加速了网络的收敛. 所以在编码端, 本文的骨干网络使用了在ImageNet[22]数据集上预训练的ResNet-34, 去除了最大池化层和全连接层以适应语义分割任务. 为了区分ResNet-34的层级特征, 本文将ResNet-34分为5个模块, 其结构如图3所示, 用Conv、Block 1表示浅层, Block 2表示中层, Block 3和Block 4表示高层和特高层特征提取模块, 浅层和中层特征用于空间信息提取路径, 而高层特征作为语义上下文信息提取模块的输入特征. 为了提升网络的感受野, 本文将ResNet-34网络的后两个模块Block 3和Block 4中的普通卷积替换为扩张卷积, 这里扩张卷积与普通卷积具有相同的参数, 扩张率分别为2和4. 在骨干网络ResNet-34中, 除Block 1外, 其他各模块存在一个步长为2的卷积, 使得骨干网络最终输出的特征图大小为输入图像的1/16.
为了获取高质量的语义上下文信息, 本文设计了语义上下文信息模块, 它由混合扩张卷积模块和残差金字塔特征提取模块组成. 在利用空间信息方面, 与U型结构不同的是, 本文没有利用编码端不含有细粒度空间信息的高层特征来恢复空间信息, 这样不仅高效利用了编码端空间细节信息还节省了模型内存开销, 也不需要像ContextNet[19]一样去另外设计空间信息获取路径, 而是共享编码端浅、中层特征, 使得获取的空间信息最有效. 本文将空间信息路径设计为反U型结构, 结合本文设计的链式反置残差模块, 在保留浅层空间信息的同时提升特征的语义信息. 在解码端, 将编码端的高级语义上下文信息进行双线性上采样与空间细节信息以逐像素点求和方式进行融合, 再对融合的特征进一步优化, 设计了残差循环卷积网络优化模块, 最后对得到的分割图使用转置卷积恢复出原始图像大小.
为了使网络有效地收敛, 与PSPNet[5]和BiSeNet[14]类似, 本文在上下文语义路径的末端加入监督信息, 即引入额外的辅助损失函数对上下文语义路径产生的初始分割结果进行监督学习. 辅助损失函数和最终分割结果的主损失函数均是使用多元交叉熵损失函数, 如式(1), 其中softmax为
| (1) |
| (2) |
网络训练时, 总的损失函数如式(3)所示,
| (3) |
扩张卷积根据扩张率在卷积核中相邻两个权值之间插入相应的零, 因此通过增加扩张率可以增大卷积核对特征图的局部计算区域, 从而可以识别更大范围的图像特征信息. 扩张卷积在二维信号中的定义如式(4), 其中输入特征图
| (4) |
本文提出的混合扩张卷积模块的设计动机是获取像素点周围特征信息的同时可以提升网络感受野, 并且减少特征信息的丢失. 根据CGNet[23], 通过融合小感受野和大感受野特征能够获取同一像素点的周围特征信息. 受Inception-v4[24]启发, 本文提出了混合扩张卷积模块, 通过混合叠加的方式来获取周围特征信息以及增加网络感受野. 如图5所示, 整个模块分为两个分支, 首先特征图通过一个
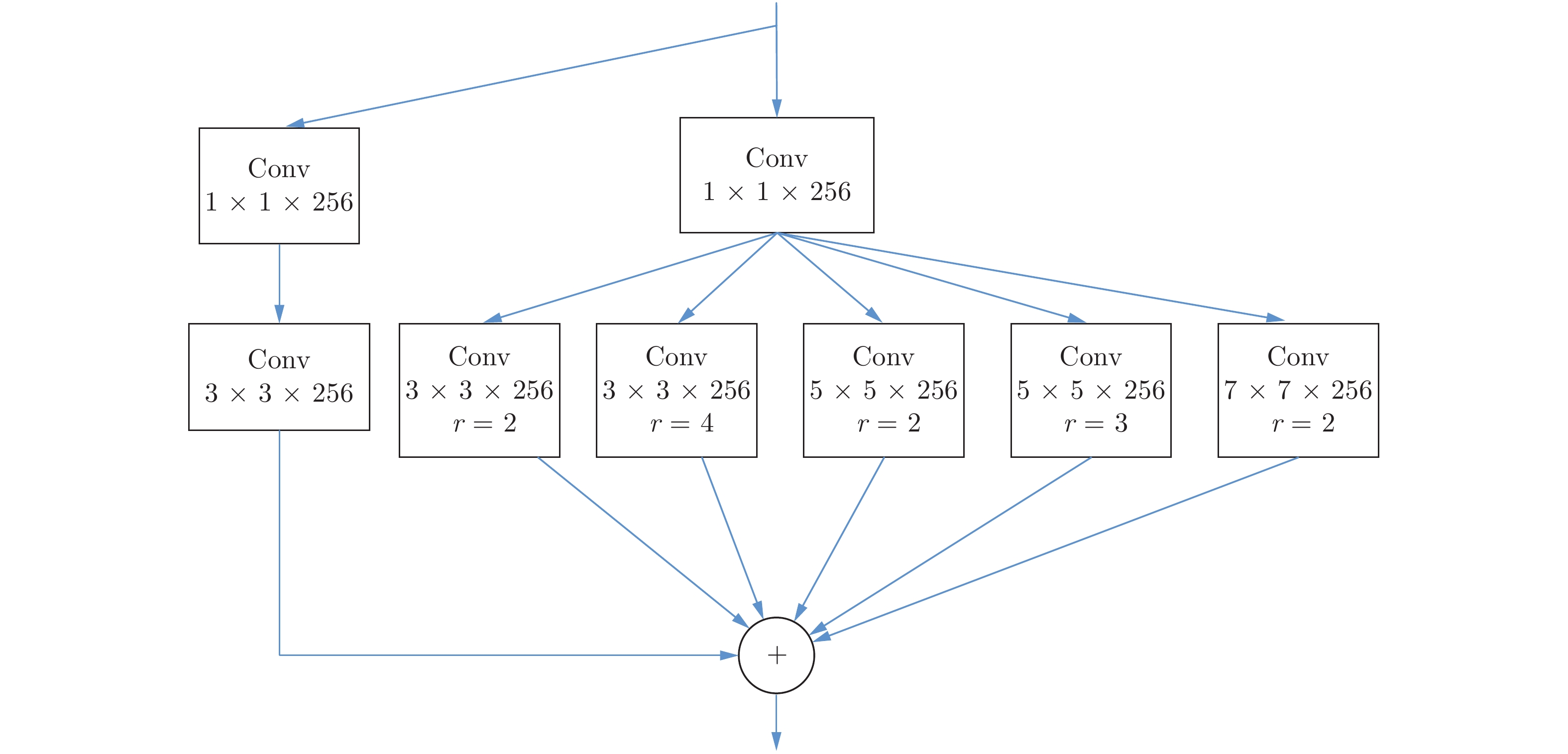
在语义分割场景中, 物体大小存在多样性, 如果使用单一尺寸的图像特征, 可能丢失图像中小物体或不显著物体的特征信息. 为了分割不同尺度的物体, 本文提出残差金字塔特征提取模块来获得具有判别力的多尺度特征, 通过使用多个不同感受野大小的扩张卷积来提取不同尺度的图像特征信息, 从而识别不同大小的物体. 本文采用了4个不同扩张率的扩张卷积, 它们的扩张率分别为: 2, 3, 5, 7. 同时, 为了利用全局场景上下文信息, 本文将全局池化操作扩展到扩张卷积空间金字塔池化中.
本文提出的残差金字塔特征提取模块结构如图6所示, 输入特征首先进入扩张卷积金字塔模块, 它由4个不同扩张率的扩张卷积和全局平局池化以并联的方式组成, 其中4个扩张卷积输出特征通道数都相同. 对全局平均池化的结果进行
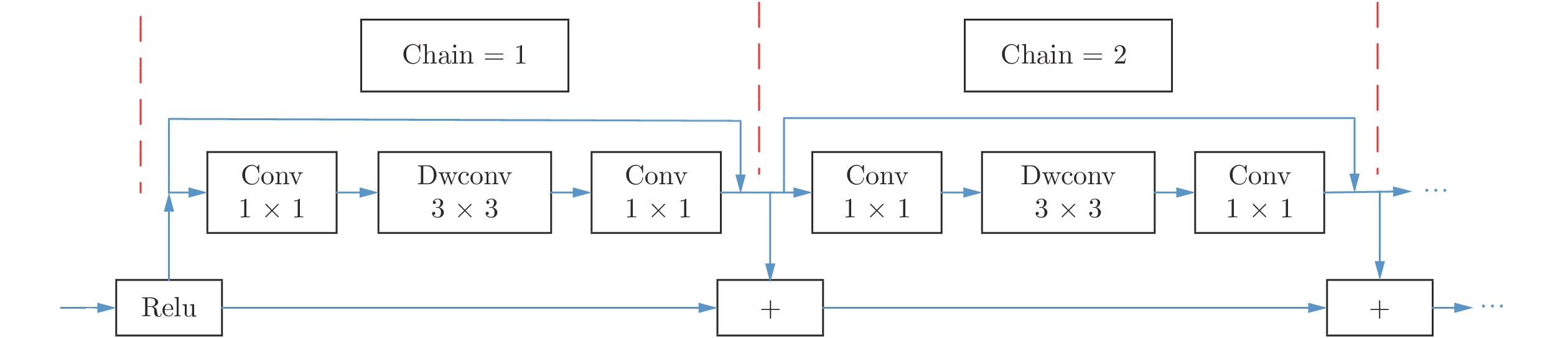
本文提出链式反置残差模块构造从编码端到解码端的空间路径, 实现原始图像的空间信息与高层语义上下文信息融合. 考虑到高层特征已经不包含细粒度的空间信息, 本文将空间路径设计为反U型结构, 只将含有丰富空间信息的低中层特征与语义信息进行融合. 受MobileNetv2[15]启发, 本文提出的链式反置残差模块的结构如图7所示. 每个链式反置残差模块将多个反置残差结构以链式结构相结合, 目的是保留空间信息的同时提升特征图的语义表达能力. 反置残差结构由两个
| (5) |
其中,
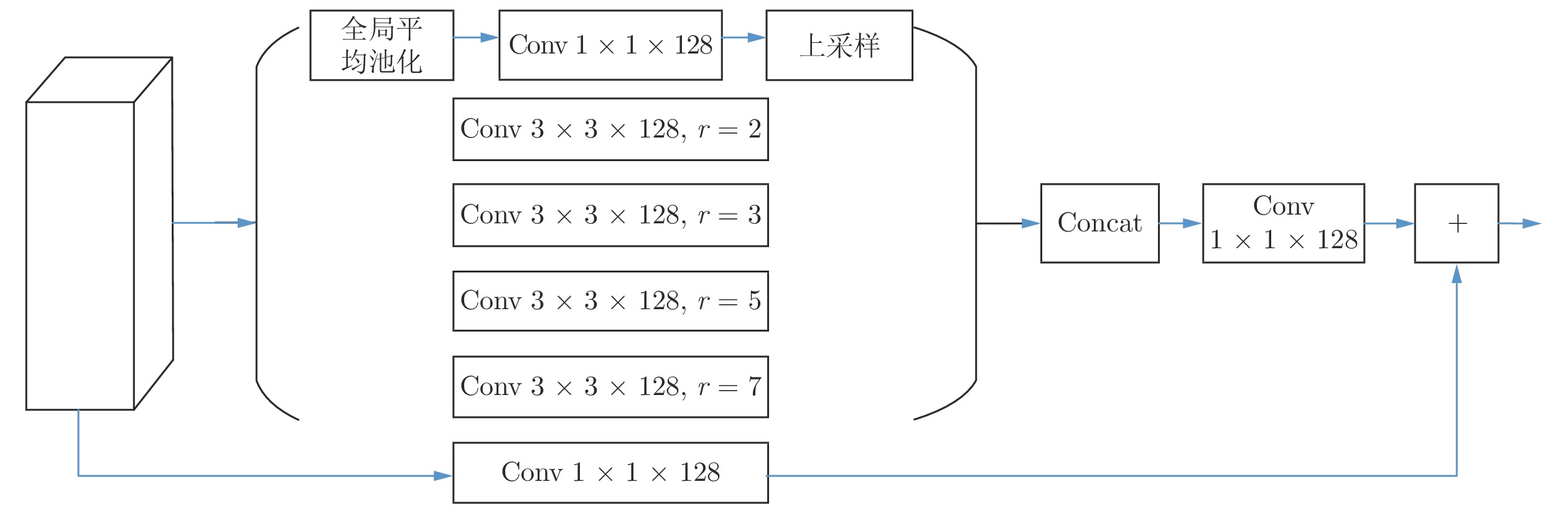
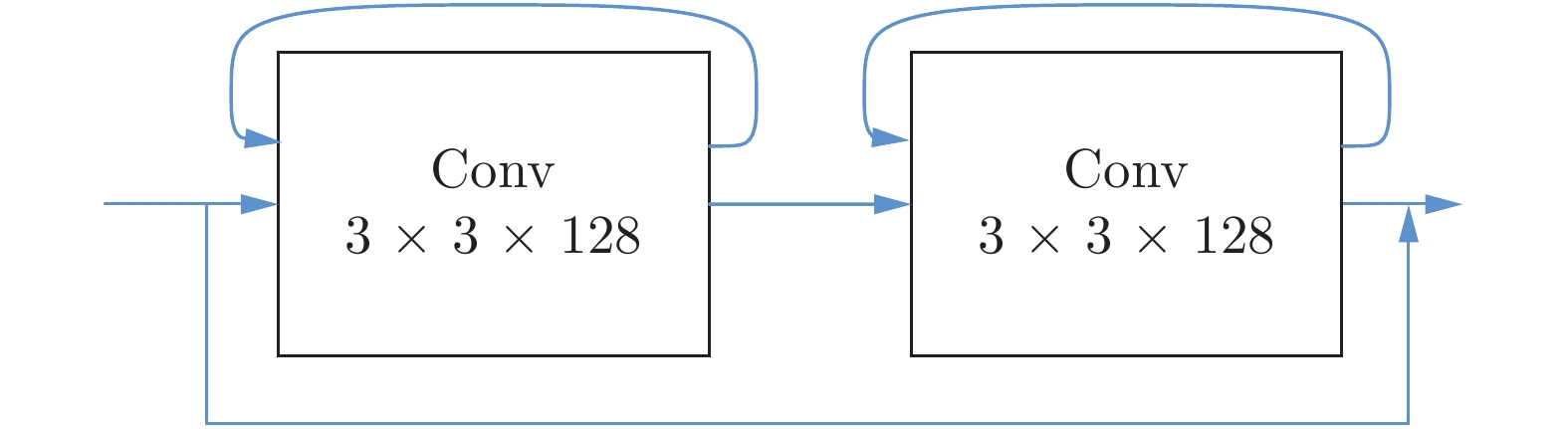
在解码端, 需要将编码端产生的高级语义信息与空间细节信息进行融合, 本文以简单的求和方式进行融合. 为了对融合后的特征进一步优化, 本文设计了优化模块. 如图8所示, 优化模块由两个
| (6) |
本文提出的方法在3个基准数据集上进行评估: CamVid[26]、SUN RGB-D[27]和Cityscapes[28]. 实验环境配置: 操作系统为64位的Windows10、CPU为Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60 GHz, 内存为512 GB, 显卡是16 GB的NVIDIA Tesla P100-PCIE. 本文实验系统实现是基于深度学习开源框架Pytorch.
除预训练的ResNet-34外, 网络的语义上下文模块参数初始化是基于Kaiming[29]初始化方法. 对于训练过程, 本文使用Adam[30]优化器来优化网络模型参数, 按照之前的工作PSPNet[5]和DeepLabV3[6], 采用Poly学习率策略动态改变网络学习率大小. Poly学习策略的定义是
本文使用当前最有效且普遍使用的平均交并比(Mean of class-wise intersection over union, MIoU)作为语义分割评估指标[1], 它用于计算预测分割图与真实标记图之间的相似度, 也就是通过计算预测分割图与真实标记图之间的交集除于它们的并集, 计算式为
| (7) |
其中, nc表示图像中包含的类别总数, nij表示实际类别为i而被预测为类别j的像素点数目, ti表示实际类别为i的像素点数目. MIoU的取值范围为[0, 1], 当MIoU的值越大, 说明预测分割图与真值标记图的重叠部分越大, 也即预测的分割图越准确.
CamVid数据集是自动驾驶领域中的道路场景数据集, 这个数据集包含376幅训练图片、101幅验证图片、233幅测试图片, 图片分辨率为
| (8) |
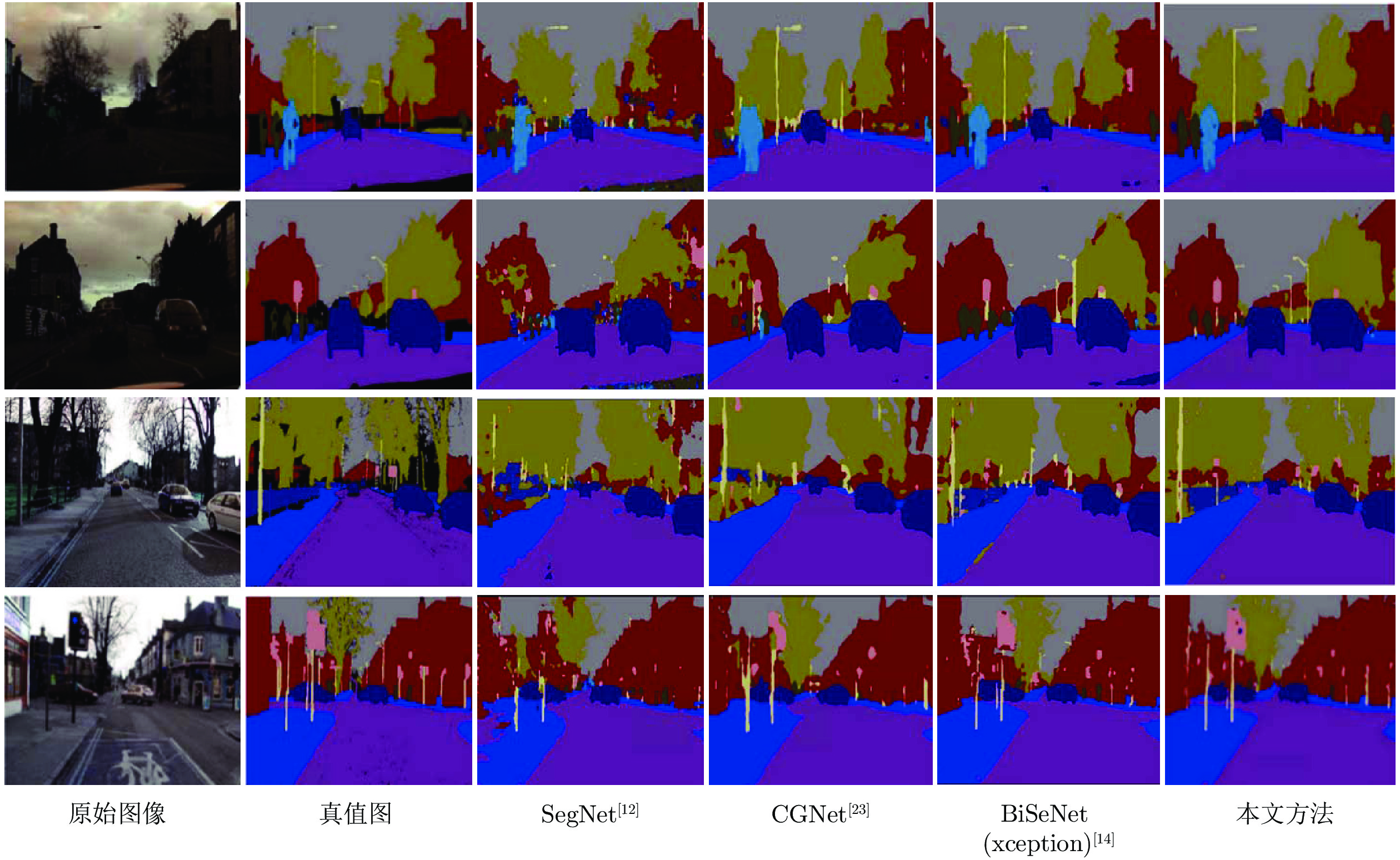
本文方法在CamVid测试集上的结果与当前分割方法的比较如表1所示, 本文方法在测试时没有采用后置处理以及一些测试技巧, 像多尺度. 从实验结果可以看出, 本文方法比使用U型结构和二分支结构的语义分割方法的性能要好, 说明本文方法能够获取高质量的上下文语义特征和有效使用浅层的空间细节信息. 从图9中的实验效果图可以看出, 本文方法基本能够准确识别图像中物体位置并且分割出物体, 而SegNet在第1行第3列的分割图中未能识别出路灯; CGNet在第2行第4列的分割图中将建筑物错误识别为树木以及BiSeNet (xception)在第2行第5列的分割图中将道路错误识别为汽车类型以及对远距离小物体路灯未能识别出来.
为了比较本文方法的效率, 在表2中比较了本文模型与其他方法的参数量, 以及在NVIDIA Tesla P100显卡上测试的处理速度. 如表2中结果所示, 相比SegNet, 本文方法在分割精度上有很大的提升. 对比BiSeNet (xception), 本文方法在分割精度上取得了明显的提升. 相比BiSeNet (ResNet18), 本文方法参数量更少.
SUN RGB-D是一个非常大的室内场景数据集, 它包含5 285幅训练图片和5 050幅测试图片, 并且有37个室内物体类别, 如墙壁、地板、桌子、椅子、沙发、床等. 由于图片中的物体有多个不同的形状、大小以及摆放的位置, 这些因素对语义分割来说是一个很大的挑战. 本文只使用了RGB数据而没有用深度信息. 在实验过程中, 本文从训练集中抽出1 000幅图片作为验证数据集, 用于检测模型性能并选择泛化能力最好的训练模型.
本文方法在SUN RGB-D测试集上的实验结果与当前分割方法的比较如表3所示. 可以看出, 本文方法在SUN RGB-D数据集上有比较大的性能提升, 从而验证了本文方法的有效性. 可视化分割结果如图10所示, 可以发现本文方法可以有效地分割图像中的物体.
Cityscapes数据集是一个高分辨率城市道路场景分析数据集, 每幅图像的分辨率为2 048×1 024像素, 具有19个语义类别, 包含5 000幅高质量标记图和2万幅粗略标记图, 本文只使用具有5 000幅精准标记图的图像用于实验. 按照官方标准, 这个数据集分成3个子集, 2 975幅训练集、500幅验证集、1 525幅测试集. 在训练时, 本文将图像裁剪为512×768像素大小, 然后在验证集上评估性能, 并将测试集上得到的结果提交到官方评估系统中.
本文方法在Cityscapes测试集上的实验结果与当前分割方法的比较如表4所示, 可以看出本文取得了有竞争的分割结果, 本文没有采用任何测试技巧, 像PSPNet中多尺度. 虽然PSPNet取得了最好的分割效果, 但其使用ResNet101作为骨干网络, 这导致它的网络复杂度最高, 达到了65 MB参数量, 在一般设备中基本无法运行. 本文采用参数量适中的ResNet34作为骨干网络并取得较好的性能, 虽然BiSeNet (ResNet18)的骨干网络只采用了ResNet18, 但它使用了多尺度训练的前置处理, 还使用了通道注意力机制模块来优化语义特征, 所以也取得了比本文更好一些的性能. 而且由于本文提出的模型使用了分组卷积和点级卷积等轻量型模块, 参数量比BiSeNet (ResNet18)更少. 图11是在验证集上的可视化分割图效果, 可以看出本文方法基本可以准确地分割图像中的物体.
为了验证所提出模块的有效性, 本小节对所提出的方法在CamVid数据集上进行了消融实验.
本文采用4种方案来评估混合扩张模块和残差金字塔特征提取模块性能: 1)在编码端的上下文路径只使用混合扩张卷积模块; 2)在编码端的上下文路径只使用残差金字塔特征提取模块; 3)在编码端上下文路径没有混合扩张卷积和残差金字塔特征提取模块; 4)在编码端上下文路径使用混合扩张卷积模块和残差金字塔特征提取模块. 实验结果如表5所示, 从表中可以看出, 同时使用混合扩张卷积模块和残差金字塔特征提取模块时获得的分割性能最好, 说明这两个模块能获取有效的周围特征信息以及多尺度特征, 从而提升网络分割性能.
本文采用4种方案来评估混合扩张卷积的有效性: 1)只使用所有分支扩张率为1的混合扩张卷积模块; 2)只使用分支扩张率分别为2, 3, 4的混合扩张卷积模块; 3)所有分支扩张率为1的混合扩张卷积模块加残差金字塔特征提取模块; 4)本文方法, 即分支扩张率分别为2, 3, 4的混合扩张卷积模块加残差金字塔特征提取模块. 实验结果如表6所示, 只使用所有分支扩张率为1的混合扩张卷积模块虽然比只使用分支扩张率分别为2, 3, 4的混合扩张卷积模块分割性能好, 但加入残差金字塔特征提取模块后, 本文设计的分支扩张率分别为2, 3, 4的混合扩张卷积模块加残差金字塔特征提取模块的模型获得了最好的效果.
本文采用4种方案来验证上下文模块顺序: 1)混合扩张卷积模块加混合扩张卷积模块; 2)残差金字塔特征提取模块加残差金字塔特征提取模块; 3)残差金字塔特征提取模块加混合扩张卷积模块; 4)本文方法, 即混合扩张卷积模块加残差金字塔特征提取模块. 实验结果如表7所示, 在语义上下文特征提取模块中同时使用混合扩张卷积模块和残差金字塔特征提取模块能够获得最佳的性能, 由于残差金字塔特征提取模块的拼接操作会影响处理速度, 从处理速度和性能上, 混合扩张卷积模块加残差金字塔特征提取模块的组合更加有效.
本文采用了5种方案来评估编码端空间路径的有效性: 1)没有空间路径; 2)使用编码端骨干网络浅层特征作为空间路径; 3)使用编码端骨干网络的高层特征作为空间路径; 4)反U型结构的空间路径但其中每个路径没有链式反置残差模块; 5)本文方法, 即反U型结构的空间路径, 其中每个路径使用链式反置残差模块. 实验结果如表8所示, 使用空间路径可以将性能从63.55%提升到66.79%, 说明使用反U型结构能够非常有效地利用编码端浅、中层特征, 这也说明编码端的浅、中层特征包含了解码时所需的空间细节信息. 使用链式反置残差块能使性能从66.79%提升到68.26%, 说明链式反置残差模块可以保留空间细节信息的同时提升其语义表达能力, 从而提升语义分割性能.
在空间路径中, 本文采用长度递减的链长分别处理深度模型的浅、中及高层特征信息, 目的是减少融合时各层的语义差异性. 表9中展现了在CamVid数据集上不同链长设置对本文提出框架分割性能的影响. 从表9中的结果可以看出, 本文针对浅、中及高层特征信息分别使用递减链长的反置残差模块更加有效.
为了表明所提出优化模块的有效性, 本文将使用优化模块和不使用优化模块进行对比. 如表10所示, 使用优化模块能使分割性能提升0.76 %, 说明优化模块可以改善融合后的语义特征, 从而增强了分割性能.
本文深入研究了采用编解码结构和二分支结构的语义分割方法, 提出了一种新的端到端的深度学习框架用于语义分割. 在编码端采用二分支结构以获取高质量的上下文语义特征, 同时有效利用编码端浅中层的空间细节信息. 本文方法在3个语义分割基准数据集上取得了有竞争力的结果, 一系列消融实验也验证了本文提出的各功能模块的有效性. 通过可视化预测结果, 发现本文方法在小物体上的分割还不够精准, 进一步的工作拟研究产生这种现象的原因, 并进一步改进分割模型.