 0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

面向未知环境的理鞋机器人系统设计与实现
随着生活水平的提升,人类对家居环境的品质要求越来越高.家居环境给人们带来的便捷与舒适成为生活中必不可少的要素,但仍有些问题未得到解决,其中之一就是鞋子摆放杂乱.近年来人们不断尝试通过部署机器人来解决日常生活中遇到的问题,服务型机器人逐渐进入大众视野.然而时至今日,关于机器人自主整理鞋子的研究仍不多.为完成自主整理任务,首先需要机器人具有感知能力,这也是计算机视觉和机器人学科的长期目标.随着传感器设备的发展,机器人通过装备的RGB相机和深度相机来捕捉丰富的环境信息,并从这些原始图像中提取高级语义信息实现基于视觉的感知,被抓取的信息通常包括目标对象的位置和方向.机器人整理鞋子的任务是让机器人识别定位鞋子及鞋子朝向,然后找到一个合适的抓取位姿,再执行路径规划,完成相应的物理抓取.本研究基于深度学习方法,利用实例分割网络训练鞋子检测模型得到图片中鞋子的掩码信息.根据设计的鞋子朝向识别算法和深度相机中的点云信息估计机器人的抓取位姿,鞋子的朝向识别保证了鞋子能正向摆放.通过预训练的卷积神经网络(convolutional neural net⁃work,CNN)提取鞋子特征,建立鞋子的特征数据库,并利用余弦相似度设计鞋子的匹配算法完成同一双鞋子的匹配.最后将其部署到真实的机器人上,完成真机的鞋子整理任务.
1 目标检测和位姿估计相关工作
传统的目标检测算法一般分为3部分:①采用滑动窗口方法或图像分割技术生成大量的候选区域;②对候选区域进行图像特征提取(如HOG[1], SIFT[2]和HAAR[3]等),提取结果输入到分类器(如ADABOOST[4]和RANDOM FOREST[5]等)中,输出候选区域的类别;③合并候选区域,实现物体的检测.传统的目标检测算法主要依赖于模板匹配,利用人工设计的描述符[2,6-7]解决单一目标检测问题.但此类算法存在两个缺陷:一是基于滑动窗口的区域选择策略针对性不强,复杂度和冗余都比较高;另一个是手工设计的特征有局限性,不能用于多目标检测,令检测结果与实际需求相差较大.
随着深度学习的不断进步,深度卷积神经网络在计算机视觉领域的使用越来越广泛,也为目标检测提供了新的研究方向.基于深度学习的目标检测算法可分为基于回归的目标检测算法(即单阶段目标检测算法)和基于区域建议的目标检测算法(即两阶段目标检测算法).单阶段目标检测算法不需要区域建议阶段,而是直接提取特征,只通过一个卷积神经网络得到物体的类别概率和位置坐标值,将检测简化成回归问题.基于回归的目标检测算法摒弃了候选区域的思想,不使用区域候选网络(region proposal network,RPN),直接在一个网络中进行回归和分类,如YOLO[9]和SSD[10].此类算法因网络的减少避免了一些重复计算,速度得到了提升.
基于区域建议的目标检测算法实现分为两个阶段:①输入图像做处理生成候选区域;②对候选区域进行分类和位置回归并最终完成检测. GIRSHICK等提出区域卷积神经网络(region CNN, R-CNN)[11]和fast R-CNN[12]目标检测网络模型. REN等[13]提出的faster R-CNN网络模型,将特征提取、预测、包围盒回归和分类整合在一个网络中,极大提升了检测速度.HE等[14]提出的mask R-CNN网络模型,则是在特征提取方面采用faster R-CNN网络模型的架构,再额外添加掩码预测分支,使实例分割在准确率及灵活性上都取得很大进步.
随着机器人自主能力的发展,智能机器人的应用越来越多样化[15].抓取是机器人的基础操作任务之一,抓取位姿检测是指识别给定图像中物体的抓握点或抓握姿态[16],抓取所需基本信息则是抓取器在相机坐标系中的6维(抓取器的3维空间位置和3维旋转角度)抓取位姿.在基于视觉的机器人抓取中,根据抓取方式的不同将抓取位姿分为2维平面抓取和3维空间抓取.
针对抓取问题,SAXENA等[16]提出不需要构建物体三维模型,直接根据图像预测抓取点的三维位置的算法,但算法定义的抓取点只含抓取的位置信息,无角度信息.JIANG等[17]利用图像中的定向矩形表示抓取位置和角度,但算法耗时较长.LENZ等[18]提出具有两个深度网络的两步级联系统,可实现对大量候选抓取位姿快速且可靠的评估,有效减少了不太可能的抓取位姿.REDMON等[19]提出了一种基于深度卷积神经网络的准确、实时的机器人抓取检测方法,通过对可抓取的边界框执行单阶段回归,实现对目标对象的抓取检测.本研究通过结合鞋子方向和鞋口检测,实现快速且高效地检测抓取位姿.
2 鞋类检测和方向识别
本研究使用的鞋类图像数据源自两部分:①网络爬取和从鞋类数据集中抽取;②采用Kinect2深度相机采集的真实环境下的鞋和鞋架图像包括原始图像数据200张,以及通过数据增强制作包含原始图像的1 000张鞋类图像,这1 000张图像中900张为训练集(400张源自网络,500张源自真实环境),100张为测试集(网络图像和真实环境的图像各50张).
采用Labelme软件对图像进行标注,使用不规则多边形标记鞋、鞋口和鞋架的基本轮廓,结果如图1.

图1 采用Labelme软件对鞋和鞋架图像进行数据标注(a)原图;(b)标注结果Fig. 1 Use Labelme to annotate shoes and shoes rack images. (a) Original images, (b) annotate images.
为提高模型泛化能力,对原始图像分别采用随机旋转一定角度、水平翻转、添加高斯噪声和颜色抖动的方式进行数据增强,如图2.

图2 数据增强(a)原图;(b)旋转;(c)翻转;(d)颜色抖动;(e)噪声Fig. 2 Data augmentation. (a) Original image, (b) rotating, (c) flip, (d) color dithering, (e) noise.
图像分割目的是将物体识别问题转化为图像分类问题.现阶段的图像分割方法思路有两种:一种是使用不同尺寸的滑动窗口遍历整张图像,全面分析图像内容,缺点是冗余度高且速度慢;另一种是先将原始图像分割成不重合的小块,再通过CNN获得特征图,特征图的每个元素对应原始图像的一个小块,最后利用该元素预测那些中心点在小块内的目标,该方法运算量少但准确率会下降.实例分割网络mask R-CNN[15]是当前工程界首选的检测算法之一,它借鉴特征金字塔网络(feature pyramid networks,FPN)[20]的思想,输出3个不同尺度的特征图,实现了多尺度的目标检测,具有结构清晰、实时性好和准确率高的特点.
本研究将机器人相机视角下在同一张图片中捕捉到的鞋和鞋架信息存储为RGB图像,再采用mask R-CNN网络模型检测图像中需整理的鞋子和拟放置的鞋架.
检测模块包含鞋子检测和鞋架检测两部分.先利用mask R-CNN网络模型在数据增强后的鞋子和鞋架数据集上训练网络识别模型,再将场景图片输入到训练好的实例分割网络模型中进行物体检测,如图3.Mask R-CNN网络模型不但能准确识别出图像中被检测物体的类别,还可用不同颜色的掩码和矩形框标记出被检测物体的区域、轮廓和位置.

图3 Mask R-CNN检测过程Fig. 3 Mask R-CNN detection process.
考虑到鞋是长条形的,本研究采用最小外接矩形(minimum enclosing rectangle,MER)方法替代直边界矩形框方法,获得更贴合鞋子的形状特点的检测框,同时还可获得鞋子的倾斜角度.图4给出了一个矩形检测框识别结果的示例.其中,白色区域是图像中部分像素点的集合.最小外接矩形是指给出一个凸多边形的顶点,求出外接该多边形且面积最小的矩形.通过计算可获得矩形框中心点像素的坐标( x,y )和相对水平线的旋转角度θ.
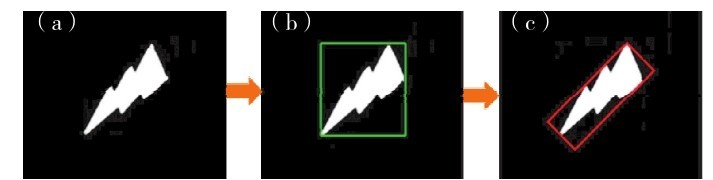
图4 矩形检测框识别结果(a)原图;(b)直边界矩形;(c)最小外接矩形Fig. 4 Rectangular detection frame. (a) Original image, (b) straight bounding rectangle, (c) minimum enclosing rectangle.
图5(b)是采用mask R-CNN进行检测识别后的鞋子图像,不同的颜色区域表示实例分割之后的掩码区域.从实例分割的结果中可提取出鞋子部分像素的掩码点集信息,进而计算出鞋子的最小外接矩形框,如图5(c).其中,shoe和mouth分别表示目标分类为鞋子或鞋口;数值代表对该检测分类的确定程度,其值分布在[ 0,1]内,0代表十分不可信, 1代表十分可信.
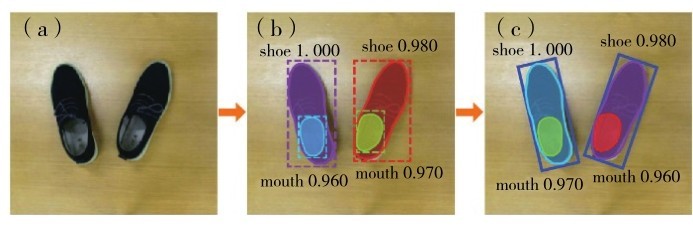
图5 鞋子检测结果(a)原图;(b)直边界矩形;(c)最小外接矩形Fig. 5 Shoes detection. (a) Original image, (b) straight bounding rectangle, (c) minimum enclosing rectangle.
采用MER方法虽然得到了比较贴合鞋子形状特点,且与鞋子方向信息关联的旋转θ角度的矩形框,但仍未解决鞋子朝向识别的问题.为此,本研究在标记鞋子训练数据的同时,对每只鞋子的鞋口进行标记.已训练的网络模型检测出鞋子和鞋口的掩码信息后,利用最小外接矩形框可分别计得鞋子和鞋口的最小外接矩形框的中心点(p1和p2)的坐标和旋转角度,如图6.大多数情况下,p2指向p1的方向即为鞋子朝向.但对于含有多只鞋子的图片,仅采用mask R-CNN进行检测并不能准确判断鞋口和鞋子的对应关系,因此还要利用OpenCV计算p2是否处于某一只鞋子的最小外接矩形区域内,以此来判断鞋口和鞋子的对应关系.

图6 鞋子朝向识别(a)检测结果;(b)朝向识别结果Fig. 6 Shoes orientation recognition. (a) Detection result, (b) orientation recognition result.
3 位姿估计
位姿估计主要分为抓取位姿估计和目标位姿(放置位姿)估计.前者定义抓取鞋子的6维抓取姿态,后者定义抓取后的6维放置姿态.鞋子的3维空间位置使用深度相机的点云信息获取.通过鞋子朝向识别算法识别出鞋子朝向并帮助确定抓取的旋转角度.同样,利用深度相机的点云信息获取鞋架放置点的3维空间位置.通过识别鞋架上木板的旋转角确定抓手的旋转角.
鞋子整理问题可以定义为2维平面内的抓取问题,适用场景通常是将物体水平放置在平面上,抓取器只能从竖直方向上抓取物体.2维平面内的抓取位姿估计需获取物体的位置信息,结合抓手的旋转角度,形成一个可靠的抓取位姿,如图7.
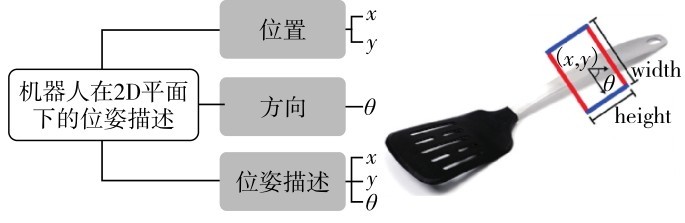
图7 二维场景下的位姿估计Fig. 7 Pose estimation in 2D scene.
定义鞋口的右边缘位置是机器人的抓取位置,如图8所示较短蓝色箭头终点的位置.根据识别的鞋子朝向结果确定抓手的旋转角度,从而得到可靠的抓取位姿.
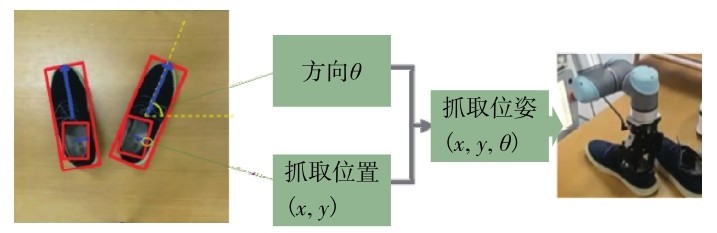
图8 鞋子抓取位姿确定Fig. 8 Grasp pose of the shoes.
摆放鞋子的目标位姿包括鞋架上放置点的3维空间位置和抓手放置时的旋转角度.3维空间位置由模型鞋架检测结果和深度相机Kinect2的点云信息相结合获取.旋转角度则根据鞋架的摆放方向确定抓手的放置旋转角度,如图9.
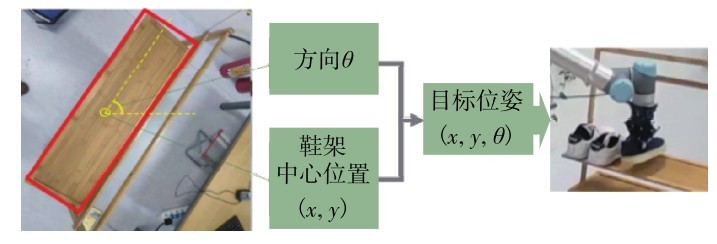
图9 鞋子放置位姿Fig. 9 Place pose on the shoe rack.
同样利用MER方法计算出鞋架的中心位置以及矩形框的宽度和长度,由此确定鞋架板的边缘位置,将其定义为第1个摆放位置.机器人每摆放1只鞋子,其摆放位置是根据上一个摆放位置在鞋架板上沿着蓝色箭头方向,移动一段根据鞋子大致宽度而设的距离,并且移动的总距离不能超过鞋架板的长度,如图 10.

图 10 精确的放置位置(a)鞋架中心;(b)首个放置点;(c)其余放置点Fig. 10 Precise placement. (a) Rack center, (b) first placement, (c) other placement.
4 鞋子匹配算法
根据鞋子整理任务中把同一双鞋子整理到一起的需求,本研究设计了鞋子匹配算法.利用目标检测结果对场景图片中的鞋子做裁剪旋转并保存成统一的格式,再使用预训练的VGG16卷积神经网络对鞋子进行特征提取并建立鞋子的特征数据库,最后通过计算鞋子特征向量之间的余弦相似度辨别两只鞋子的匹配度,完成鞋子的匹配.
在鞋子匹配前,需获取同一图像中每只鞋子的图像.在多鞋子图像中识别单只鞋子的方法主要有两种.方法1保留鞋子的原始位置,根据掩码检测结果只保留单只鞋子的像素部分,其余部分用黑色背景填充,如图 11(a).利用此种方法获取的单只鞋子图像进行匹配,鞋子的摆放位置和朝向会对匹配结果产生较大影响.方法2先获取鞋子朝向的角度,将鞋子统一旋转成竖直向上方向,再根据矩形框对鞋子图像进行裁剪.最终图像中所有鞋子朝向一致,且单只鞋子的图像只保留了鞋子部分的像素,减少了干扰匹配相似度计算的无用信息,提高了匹配的准确率.本研究使用mask R-CNN分割网络和鞋子朝向识别算法识别出鞋子的朝向和比较贴合鞋子形状特点的矩形框,同时根据鞋子的朝向获得相应的旋转角度,将原图中的鞋子进行裁剪和旋转,全部处理成竖直向上形式,如图 11(b).

图 11 多鞋子图像中单只鞋子的分离识别结果(a)保留单只鞋子原始位置分离方式;(b)统一单只鞋子方向的分离方式Fig. 11 The separation recognition result of single shoe in multi-shoes image. (a) Keep the original position of single shoe method, (b) unify the orientation of single shoe method.
首先利用在 ImageNet 数据集上预训练的VGG16网络模型提取图像中每只鞋子的特征,建立包含所有鞋子特征的数据库,然后利用网络提取的特征计算单只鞋子图像之间的余弦相似度,最终实现鞋子匹配.一双鞋子的匹配流程如图 12.
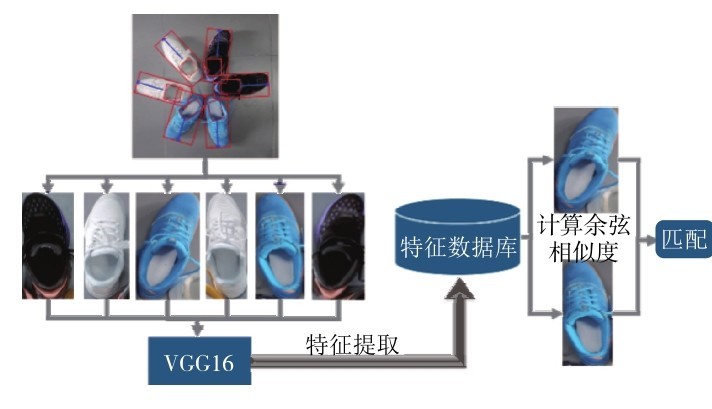
图 12 鞋子的匹配流程Fig. 12 Shoes matching process.
余弦相似度是通过计算两个向量之间的夹角的余弦值来评估他们的相似程度,夹角越小,余弦值越接近1,两向量的方向越一致,表明向量之间越相似.给定两个n维属性的向量A和B,θ为两向量之间的夹角,则它们的余弦相似度为其中, Ai和Bi分别为A和B的第i个分量.cos θ=-1表示两向量方向相反;cos θ=1表示两向量方向相同;cos θ=0表示两向量互相独立.cos θ越接近1,表明两只鞋子提取出的特征越相似,是一对的可能性越高.
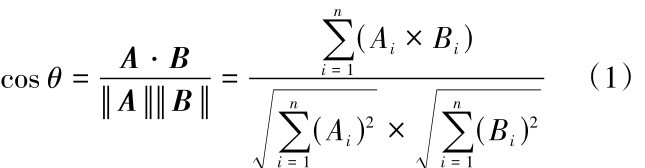
5 真机实验和结果分析
本研究中的模型训练使用2张8 GByte的Quadro M5000显卡,图形处理器(graphics processing unit, GPU)每次处理2张图片,学习率为0. 001,迭代次数为300 epochs.使用1 000张标注图像作为训练集,其中100张作为测试集.训练模型的损失函数、边界框的损失函数和掩码的损失函数皆随着迭代次数的增加逐渐收敛.
为量化实验结果,采用平均精度(mean average precision,mAP)来评定训练模型对多标签图像中所有类别进行检测的效果.表1给出了迭代次数τ为分别为50、150和300 epochs时,采用Mask R-CNN模型对100张测试图片进行分类检测后的mAP值、对12张总共包含78只鞋子的图片进行朝向识别的准确率Ao和模型训练耗时t.表1表明,随着迭代次数的增加,mask R-CNN模型对鞋子的识别效果和鞋子朝向识别的准确率随之提升,但相对地训练耗时会增加.
表1 Mask R-CNN模型训练迭代次数对识别性能的影响Table 1 Comparison of model detection and orientation recognition performance

图 13对比了训练模型τ分别为50、150和300 epochs时进行目标检测的结果.从图 13可见,随着迭代次数的增加,模型识别效果越来越准确,掩码边缘识别效果随之提升.
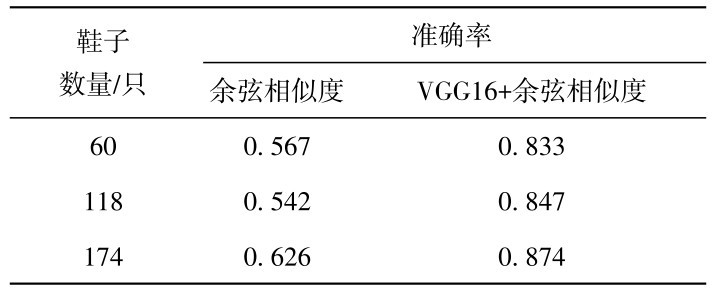
采用统一单只鞋子方向的图像处理方式,对比只采用余弦相似度和加入VGG16特征提取两种方法的匹配准确率,结果如表2.由表2可见,加入VGG16提取特征后进行相似度计算,可明显提升算法匹配准确率.

图 13 不同训练次数对鞋子实例分割的结果(a)原图;(b)检测结果;(c)Ground truth;(d)掩码结果(上排为τ=50 epochs,中排为τ=150 epochs,下排为τ=300 epochs) Fig. 13 Comparison of shoes instance segmentation results. (a) Original images, (b) detection images, (c) Ground truth images, (d) mask images. (The images from top to bottom are τ=50,150,300 epochs respectively.)
表2 只采用余弦相似度和加入VGG16特征提取两种方法匹配准确率对比Table 2 Comparison of shoe matching methods of using cosine similarity and VGG16+cosine similarity, respectively.
实例分割网络的作用是检测图像中的可抓取物体,因此,本研究利用机器人操作系统(robot oper⁃ating system,ROS)中的机械臂路径规划算法,探寻机械臂抓取鞋子目标的实际控制途径.路径规划算法需要提供一个在机器人基座坐标系下的3维抓取位置,而本研究的检测网络只能识别2维图像上的抓取位置,因此要进行相机标定,将2维图像的抓取位置转换到相机坐标系空间,再进行机械臂的手眼标定将相机坐标系转换到机器人基座坐标系空间,最终得到待抓取物体在机器人基座坐标系中的空间位置.图 14是机器人在鞋子整理过程中的部分视频帧.每一行帧图片显示的是完成1只鞋子的整理任务,第1列帧图片是机器人根据抓取位姿实现抓取鞋口的右边缘,第2列帧图片是根据识别的鞋子朝向将鞋子摆正,第3列帧图片是机器人根据放置位姿将鞋子摆放到鞋架上.机器人每完成一只鞋子的整理任务后,根据鞋子匹配算法对未整理鞋子进行匹配和整理,从而完成一双鞋子的整理任务.如此反复,最终实现对所有鞋子的整理.

图 14 机器人整理鞋子真机实验的部分的视频帧(左下角为同步的点云) Fig. 14 Part of video frames of real robot experiment of shoes arrangement. (The bottom left corner is the synchronized point cloud.)
结 语
设计了一套基于3维视觉的机器人自主理鞋系统.采用mask R-CNN网络模型在自制数据集上训练检测模型,实现鞋子和鞋架检测和像素级别的实例分割.利用实例分割得到的掩码点集合和最小外接矩形框方法设计鞋子朝向识别算法,并由此估计出鞋子的抓取位姿和放置位姿.利用目标检测结果对场景图片中的鞋子做裁剪,旋转后保存成统一的格式,再使用预训练的卷积神经网络VGG16对鞋子特征进行提取并建立鞋子的特征数据库,通过计算两只鞋子特征之间的余弦相似度实现鞋子匹配.建立了机器人的视觉系统,将深度相机Kinect2作为机器人的视觉感知器,采用相机标定获取相机内外参数,通过手眼标定完成相机坐标系和机器人基坐标系的统一,从而获得相机在机器人基坐标系下的位姿.基于ROS完成真实机械臂的控制程序设计工作,利用深度相机的点云信息完成目标定位的功能,实现真机测试.
未来将继续构建更大的鞋类数据集,提高目标检测的准确率和鲁棒性,为匹配和定位提供更加稳定强健的基础保障.在鞋子检测和匹配中,由于鞋子左右的特征区分度较低,本研究未能实现鞋子左右的区分,所以未来如何提高鞋子左右特征的区分度,准确实现鞋子左右的检测是一个可持续探索的研究方向.

- 刚刚!2026年中科院分区,公布!本次看点:中科院分区变更为新锐分区;不再单独发布预警期刊;37种期刊“under review”~
- 这些重要报纸理论版都支持邮箱投稿!回复极快!
- GB/T 7714-2025与GB/T 7714-2015相比,变更了哪些,对期刊参考文献格式有什么影响?
- 别被这个老掉牙的报纸理论版投稿邮箱误导了!最新核实91个报纸理论版投稿邮箱通道,一次集齐
- 喜报!《中国博物馆》入选CSSCI扩展版来源期刊(最新CSSCI南大核心期刊目录2025-2026版)!新入选!
- 2025年中科院分区表已公布!Scientific Reports降至三区
- 国内核心期刊分级情况概览及说明!本篇适用人群:需要发南核、北核、CSCD、科核、AMI、SCD、RCCSE期刊的学者
- CSSCI官方早就公布了最新南核目录,有心的人已经拿到并且投入使用!附南核目录新增期刊!
- 北大核心期刊目录换届,我们应该熟知的10个知识点。
- 注意,最新期刊论文格式标准已发布,论文写作规则发生重大变化!文字版GB/T 7713.2—2022 学术论文编写规则

