0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com


图 1 行人再识别和多目标跨摄像头跟踪关系示意
Fig. 1 The relationship between person re-identification and multi-target cross-camera tracking
近年来, 伴随着视频采集技术的大力发展, 大量的监控摄像头部署在商场、公园、学校等公共场所. 监控摄像的出现给人们带来了极大的便利, 其中最直接的一个好处就是可以帮助公安等执法部门解决盗窃、抢劫等重大刑事案件. 但是正是由于监控摄像头布置的区域十分广阔, 基本在大中小城市中都遍地布满了监控摄像头, 当一个目标人物在一个城市的监控摄像网络中移动时, 往往会导致公安等相关部门人员在一定时间内在整个网络中对监控视频进行查看, 这对公安等相关部门进行区域的管理以及视频的查看带来了较大的不便. 因此, 需要一种方便、快捷的方式来代替人工对监控视频中行人进行搜寻. 为了实现对监控视频中的行人进行搜寻这个目标, 其本质就是要实现多目标跨摄像头追踪, 而行人再识别技术[1-2]是多目标跨摄像头追踪问题的核心与关键. 行人再识别和多目标跨摄像头追踪的关系如图1所示. 实际场景中, 摄像头拍摄到的是包含众多行人与复杂背景的图像, 这个时候可以利用行人检测技术从拍摄到的复杂全景图像中得到行人包围框, 之后对于行人包围框集合利用行人再识别技术进行搜寻.
除此之外, 犯罪分子通常会在夜间行动, 这时仅仅靠RGB相机去采集图像不能很好地解决这种夜间出现的行人匹配问题. 为了对夜晚出现的行人也能进行匹配, 除了RGB相机外, 有些地方可能会布控红外(Infrared, IR)相机, 这样, 在夜间或者是光线较暗处也可以采集到行人的红外图, 弥补了在夜晚传统的RGB相机采集失效的问题. 在这种情况下, RGB图和IR图之间的跨模态匹配(跨模态行人再识别)具有很重要的现实意义. 跨模态匹配的重点是寻找不同模态间的相似性[3-4], 从而跨越模态对行人再识别的限制.
跨模态行人再识别相对于传统的行人再识别, 除了面临行人之间姿态变化、视角变化等问题外, 数据之间还存在跨模态的难点. 图2为跨模态行人再识别数据集中的行人数据. 图中第1行为在白天通过RGB相机在室内采集到的RGB图像; 第2行为在夜晚通过红外相机在室内采集到的IR图像; 第3行为白天在室外采集到的RGB图像; 第4行为夜晚在室外采集到的IR图像. 每一列的4张图片属于同一个人, 不同列的图片属于不同的人. 与传统的RGB-RGB图像之间的匹配不同, 跨模态数据集上所关注的是IR图像和RGB图像之间的匹配, 这种跨模态匹配为行人再识别增加了不少难度, 如图2中第3列和第4列的两个行人, 通过RGB图可以很好地进行区分, 但通过IR图和RGB图匹配, 难度有一定程度的提升.
针对上述这些问题, 本文主要创新点如下:
1)提出一种自注意力模态融合网络以解决跨模态行人再识别中存在的模态变化问题;
2)提出使用CycleGAN对图像进行模态间的转换, 从而解决学习时需要对应的样本对问题;
3)提出使用自注意力机制进行不同模态之间的特征筛选, 从而有效地对原始图像和使用CycleGAN生成的图像进行区分.
近年来, 随着模式识别以及深度学习的发展, 研究人员针对行人再识别方法做了大量的实验与研究工作. 前期针对行人再识别的方法主要集中于利用传统的模式识别方法, 例如设计行人特征来表示行人, 或者利用一些距离度量方法来评估行人之间的相似性. 随着Krizhevsky赢得了ILSVRC12[5]的比赛, 基于深度学习的方法得以流行. 深度学习的方法主要集中于3个方面: 1)通过设计卷积神经网络更好地学习到行人的特征; 2)利用损失函数更好地度量行人相似度; 3) 通过数据增强让网络更加鲁棒, 使网络可以忽略一些和行人类别无关的特征.
Gray等[6]为了考虑到空间信息, 首先将图像按水平方向划分为多个矩形, 之后在每个矩形内, 利用颜色特征中的RGB、HSV、YCbCr, 以及选择21个Gabor、Schmid滤波核来获得纹理特征. 最后将得到的每个水平条特征拼接在一起, 作为最后行人的特征表示.
Yang 等[7]提出了一种新的语义特征显著性 Color Name特征, 该特征不同于传统的颜色直方图, 它通过将颜色量化, 保证每一个像素的颜色通道以较大的概率划分到量化的颜色区间, 即对应的Color name 中.
2012年Köstinger等[8]提出经典的基于马氏距离度量的行人再识别算法KISSME (Keep it simple and straightforward metric).
Zheng等[9]利用一个孪生网络[10], 结合分类问题与验证问题, 一次输入一对行人图片, 对于输入的一对行人图片, 网络一方面要预测两幅图片中行人各自的ID, 另一方面要判断输入的两幅图片中的行人是否为属于同一行人. 在分类问题中, 他们使用SoftMax 损失进行行人类别分类. 在验证问题中, 利用一个二维SoftMax 损失进行一个二分类.
Zhang 等[11]提出了一种端到端的方法AlignedReID, 让网络自动地去学习人体对齐. 在AlignedReID中, 深度卷积神经网络不仅提取全局特征, 同时也对各局部提取局部信息, 在提取局部信息时采用动态匹配的方法选取最短路径, 从而进行行人对齐, 在训练时, 最短路径长度被加入到损失函数, 辅助学习行人的整体特征.
Zhao 等[12]提出了一种基于人体关节点对人体进行区域划分的网络(Spindle net), 首先定位人体的14个关节点, 通过区域提取网络来产生7个身体区域, 再通过FEN (Feature extraction net)特征提取网络和FFN (Feature fusion net)特征融合网络以身体区域为基础进行人体特征提取与融合.
Dai 等[13]提出了一种批特征擦除BFE (Batch feature erasing)方法, 对于一个批量的特征图, 随机遮挡住同样的一块区域, 强迫网络在剩余的区域里面去学一些细节的特征. 这样训练得到的网络不会太过于关注那些显而易见的全局特征.
Zhong 等[14]通过引入Camera style adaptation来解决相机差异导致的行人图片变化(光线、角度等)的问题. 作者首先利用CycleGAN[15]实现不同相机风格的转化, 在得到不同相机风格下的图片后, 将这些生成的图片放入网络中进行训练, 其中原始图像利用SoftMax损失进行有监督的训练, 生成图像利用LSR (Label smoothing regularization)损失进行训练. LSR 损失用于解决生成图像产生较多噪音的问题. 通过在训练数据中增加相机风格图片, 一方面增加了训练集数据量, 另一方面通过增加各个相机风格图片, 使得网络能够集中学习与相机无关的特征.
跨模态行人再识别的方法目前集中于深度学习的方法. 包括通过设计卷积神经网络来更好地学习跨模态行人的特征以及利用损失函数来更好地度量不同模态的行人之间的相似度.
2017年, Wu 等[16]提出了一种基于Deep zero-padding的跨模态行人再识别方法, 并且建立了一个大规模跨模态行人再识别数据集SUSU-MM01. 作者对输入的RGB图和IR图在通道上进行了填充. RGB图先转换为第1通道的灰度图, 之后在第2通道填充大小与灰度图一样的全0值. 对IR图, 在第1通道填充大小与IR图一样的全0值. 接着将填充后的RGB图和IR图统一的放入网络中进行训练, 通过SoftMax 损失对行人标签进行有监督的训练.
Ye 等[17]提出BDTR (Bi-directional dual-constrained top-ranking)方法来解决跨模态行人再识别. 作者通过一个孪生网络对RGB图片和IR图片分别进行特征提取, 利用SoftMax损失和提出的双向排序损失(Bi-directional ranking loss)进行有监督的训练. 双向排序损失包括跨模态约束(Cross-modality top-ranking constraint)和模态内约束(Intra-modality top-ranking constraint).
Dai 等[18]提出了cmGAN (Cross-modality generative adversarial network)方法, 该方法同样使用了类似于BDTR中的跨模态约束损失来保证跨模态图像的负样本对距离大于跨模态图像的正样本对距离, 另外, 利用SoftMax损失对行人ID进行有监督的训练. 除此之外, 结合生成对抗网络的对抗训练的思想, 在判别器部分, 用一个二分类来区分图像是RGB图还是IR图.
Lin 等[19]提出了HPILN (Hard pentaplet and identity loss network)方法, 该方法对现有的单个模态的行人再识别模型进行了改进, 使其更适用于跨模态场景, 并提出一个新型损失函数: Hard五元组损失(Hard pentapelt loss), 使得网络可以同时处理模态内和模态间变化, 再结合身份损失函数(Identity loss)来提高改进后的模型的性能.
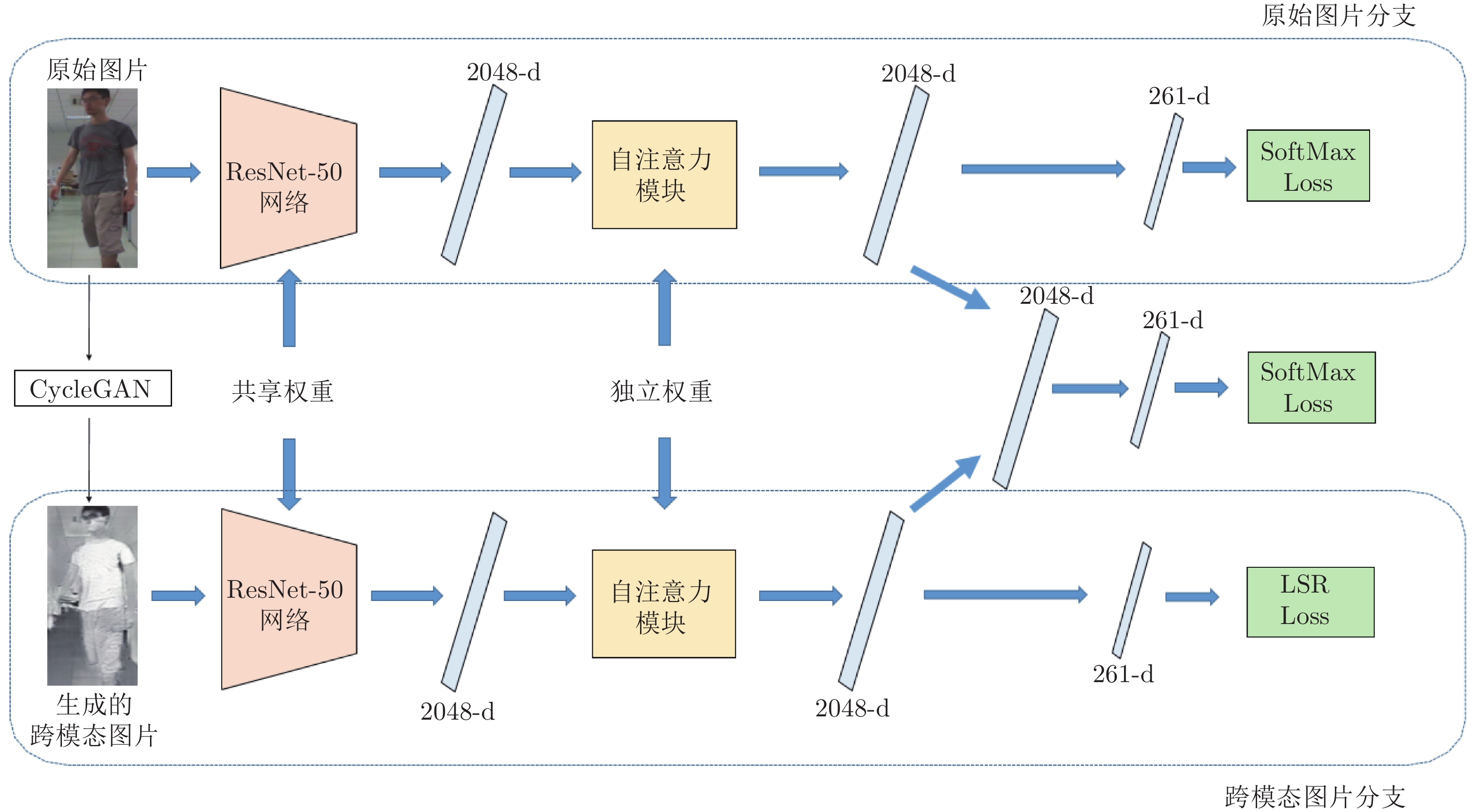
跨模态行人再识别和传统的行人再识别相比, 增加了相同行人不同模态的变化. 为了减轻跨模态行人再识别中由于跨模态数据导致的问题, 本文首先利用CycleGAN[15] 对于每一幅图片生成其对应跨模态下的图片. 如果原始图片是RGB图, 则CycleGAN生成IR图; 如果原始图片是IR图, 则CycleGAN生成RGB图. 之后利用跨模态学习网络将原始数据和生成的跨模态数据加入到基本的分类网络中进行训练, 这样跨模态学习网络即可同时利用原始数据以及经过CycleGAN生成的跨模态数据. 对于每一幅图片, 为了将原始图片与CycleGAN生成的跨模态数据进行区分以及特征选择, 本文针对每一种数据, 分别设计了一个自注意力模块进行行人特征的筛选. 接着将经过自注意力模块后的原始特征和跨模态图片特征经过Max层进行融合, 最后原始图片特征以及融合后的特征利用SoftMax 损失进行有监督的训练, CycleGAN生成的跨模态图片特征利用LSR损失[20]进行训练. 自注意力模态融合网络的结构图如图3所示.
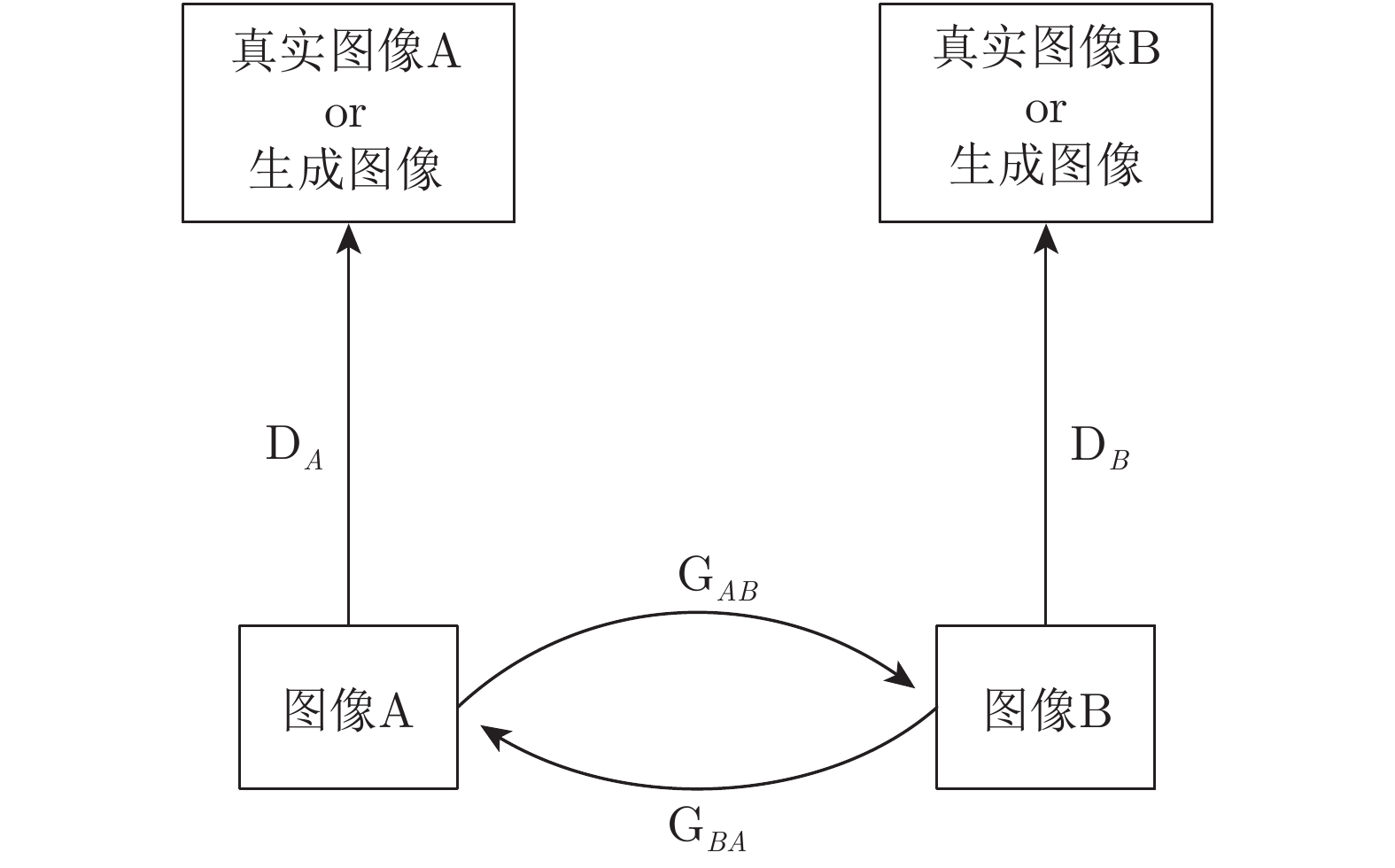
生成对抗网络 (Generative adversarial network, GAN)[21-22]自2014年由 Goodfellow等提出后, 越来越受到学术界和工业界的重视. 其中, GAN在图像生成上取得了巨大的成功, 这取决于GAN在博弈下不断提高建模能力, 最终实现以假乱真的图像生成. 图像到图像的转换可分为有监督(如cGAN[23], pix2pix[24])和无监督(如CycleGAN[15], DualGAN[25])两大类.
针对本文的跨模态应用场景, 我们没有成对的样本数据作为输入图像, 所以无监督的生成对抗网络更适用; 其次, 尽管CycleGAN 和DualGAN具有相同的模型结构, 但它们对生成器使用不同的实现方法. CycleGAN使用卷积架构的生成器结构, 而DualGAN遵循U-Net结构; CycleGAN重在解决非配对图像转换问题, 而DualGAN重在解决如何避免模型崩溃问题. 经过以上综合分析, CycleGAN适合完成风格迁移任务且是无监督的, 因此更适用于我们的网络.
为了学习到跨模态的信息, 本文首先利用CycleGAN生成跨模态的数据. CycleGAN可以将两个域的图像进行相互转换, 并且CycleGAN的输入是任意的两幅图片, 不需要它们成对出现. 因此, 可以直接利用CycleGAN实现跨模态行人再识别中的数据模态转换. CycleGAN的网络结构如图4所示.
假设有来自两个属于不同数据域的集合, 记为
本文将所有的RGB相机采集到的图像作为域
跨模态学习网络的设计参照Zhong 等[14] 设计的网络. 该网络由一对共享权重的ResNet-50组成. 在得到了两种模态图像后, 本节将原始的数据和生成的跨模态数据都加入到ResNet-50[26] 网络中进行训练. 跨模态学习网络的输入和一般的分类网络不同, 它的输入为一对图像, 包括原始图像和CycleGAN生成的跨模态图, 跨模态学习网络每次输入的生成图像是由原始图像生成的跨模态图. 由于生成图像是由原始图像变换过来, 所以该生成图像的标签理想情况下应该和原始图像标签一致, 因此在训练跨模态生成图时可以和原始图像一样, 可以利用SoftMax 损失进行有监督的训练. SoftMax 损失的计算如式(1)所示.
| (1) |
式中,
但是, 在观察生成的跨模态图时, 发现生成的跨模态图大多具有很大的噪声, 尤其是当IR图像到RGB图像的转换时. 如图6所示, 其中第1行为原始的RGB图; 第2行为利用CycleGAN生成的对应的跨模态IR图; 第3行为原始的IR图; 第4行为利用CycleGAN生成的对应的跨模态RGB图. 同一列为相同的行人, 不同列对应不同行人. 从中可以看出, 生成的图像一般很难和原始图像用一个标签来区分.
本文针对跨模态行人再识别中数据集的模态变化问题, 提出了一种自注意力模态融合网络. 采用CycleGAN进行跨模态图像的生成, 并在ResNet50网络的基础上加入了自注意力模块和模态融合模块. 通过对网络中的不同模块进行组合对比实验, 证明了本节提出的每一个模块的有效性. 另外通过在SYSU-MM01数据集上的实验, 也证明了本文提出的方法与其他跨模态方法相比有一定程度的提升. 与其他跨模态行人再识别方法相比, 本文不仅在网络结构上进行了改进, 同时在数据层面进行了创新. 我们首次将CycleGAN用于跨模态行人再识别图像生成从而实现数据的跨模态变化. 但目前本文方法跨模态生成的图像质量较差, 有一定的噪声. 为了克服以上缺陷, 在今后的工作中将重点解决此问题, 从而更好地解决跨模态行人再识别问题.
针对上述问题, 对于CycleGAN生成的跨模态图, 本文利用LSR损失来进行训练. 一般的分类损失函数, 如SoftMax 损失, 对图像的标签会编辑成One hot形式, 如式(2)所示. LSR损失考虑到数据的过拟合, 在给定图像标签时, LSR给定Ground-truth类一个比较大的值, 剩余的类标签给定一个比较小的值, 如式(3)所示, 将LSR的数据标签代入SoftMax 损失(式(1))中, 即得到LSR的计算式, 如式(4)所示.
| (2) |
式中,
| (3) |
式中,
| (4) |
式中,
跨模态学习网络同时学习了原始图像以及相对应的跨模态图像的特征. 同时, 由于对同一幅图网络得到了两种模态信息, 数据量上有一定的提升, 可以看成是进行了数据增广. 除此之外, 网络对同一幅图同时考虑到了两种模态信息, 因此, 跨模态学习网络同时增强了对于模态无关特征的学习.
在第2.2节中的跨模态学习网络, 虽然同时输入了两种模态图像, 但是除了在最后损失函数的时候进行区分外, 网络本身对于原始图像和跨模态图像的处理完全一致. 这样通过数据增广的方式在一定程度上虽然可以学习到一些模态无关的特征, 但是不同模态之间缺少交互, 在训练过程中两种模态之间单独地进行监督训练. 卷积神经网络通过在局部感受野上进行卷积操作来融合空间和通道信息, 而自注意力模块本质上引入了对输入的动态适应性, 这有助于增强特征区分能力, 提高行人再识别的性能. 因此, 针对上述问题, 本文在跨模态学习网络的基础上构建了一个自注意力模块, 该模块通过自注意力机制将原始图像和CycleGAN生成的图像进行区分, 自动地对第2.2节中产生的不同模态的特征在通道层面进行筛选. 该模块增加在跨模态学习网络的2 048维特征层和最后一层261维(与训练数据集中行人数一致)全连接层之间. 它的输入是经过跨模态学习网络产生的两个2 048维特征, 经过自注意力模块后, 输出依然为两个2 048维特征, 该特征维度和跨模态学习网络的输出维度一致, 但是对不同模态的特征进行了筛选.
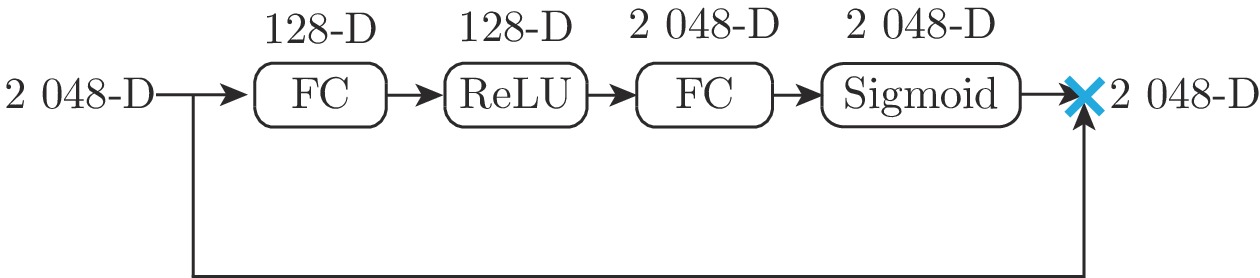
自注意力模块的设计参照SENet[27] 中SE (Squeeze-and-excitation)模块. 由于自注意力模块是直接在ResNet-50 全局平局池化后的特征通道上进行特征选择, 因此和SE模块不同, 自注意力模块不需要额外使用全局平均池化做一个 Squeeze 操作. 剩余Excitation操作和SE模块保持一致. 自注意力模块包括两个全连接层、一个ReLU[28]激活函数和一个Sigmoid[29] 激活函数. 自注意力模块使用两个全连接层去构造特征通道间的相关性. 首先, 第1个全连接层将特征维度降低到输入的
在利用第2.2节中的跨模态学习网络进行行人再识别测评时, 仅仅输入原始图像, 测试集的生成图像并没有得到充分利用. 针对该问题, 本节提出利用模态融合模块将两种筛选后的特征进行融合, 融合后的结果再送入到全连接层, 最后用SoftMax损失进行有监督的训练.
模态融合模块的目的是将原始图像和CycleGAN生成的图像进行融合. 由于CycleGAN生成的图像相对于原始图像是跨模态的, 即原始图像如果是RGB图, CycleGAN生成的图是IR图, 反之如果原始图像是IR图, CycleGAN生成的图是RGB图. 这两种图像应该具有互补性. 在一定的条件下, 通过RGB图可以获得丰富的颜色特征, 通过IR图可以获得丰富的纹理特征. 因此, 在本节利用模态融合网络可以将原始图像以及跨模态图像中对于分类比较有用的特征进行保留. 模态融合模块通过一个Max层完成. 将经过自注意力模块的原始图像特征和CycleGAN生成图像的特征经过Max层进行融合. 融合后的特征再连接到共享的全连接层上, 最后进行有监督的训练.
为了评价自注意力模态融合网络在跨模态行人再识别中的效果, 本节在一个常用的跨模态行人再识别数据集SYSU-MM01[16] 上进行实验. 评价指标选择了行人再识别中常用的CMC曲线(Cumulative matching curve)和mAP (mean average precision).
SYSU-MM01是中山大学采集的一个跨模态行人再识别数据集. 它包括4个RGB相机和两个IR相机. 其中cam1与cam2为拍摄到的Indoor场景下的RGB图像, cam3为Indoor场景下的IR图像, 且与cam2是同一个场景; cam4与cam5为Outdoor场景下的RGB图像, cam6为Outdoor场景下的IR图像. SYSU-MM01总共有491个不同行人, 总共包括287 628 幅RGB图像, 15 792幅IR图像.
在测试的时候, 该数据集中测试集的所有IR图像作为Probe, 所有的RGB图像作为Gallery. 有两种评价模式, 一种是All-search模式, 另一种是Indoor-search模式. 除此之外, 在每种模式下, 分别采用Single-shot测评和Multi-shot测评. 在Single-shot测评时, 在测试集中的每一个行人, Gallery集合中随机选取一个与该行人类别相同的RGB图片构成Gallery集, 所有的Probe图像构成Probe集. 在Multi-shot测评时, 对于测试集中的每一个行人, Gallery集合中随机选取10个与该行人类别相同的RGB图片构成Gallery集, 所有的Probe图像构成Probe集.
在该数据集上测评时, 使用CMC曲线和mAP来进行测评. 在测评时, 利用上述的方法构造Probe和Gallery. 计算CMC曲线和mAP的方法和传统的行人再识别方法一致. 但是, 考虑到该数据集下cam2和cam3是在同一个地方采集, 而行人再识别的研究重点是跨摄像头, 因此, 在评价算法时, 在匹配cam2的Probe时, 会忽略cam3中的Gallery. 对于上述的每一种测评, 包括All-search下的Single-shot测评和Multi-shot测评以及Indoor-search下的Single-shot测评和Multi-shot测评, 本文都重复了10次实验并计算10次的平局值.
我们使用Pytorch[30] 来实现本文中的自注意力模态融合网络. 在训练过程中, 跨模态学习网络首先加载了在ImageNet上预训练的ResNet-50网络的参数. 我们使用AMSGrad[31] 来训练网络. 给定权重衰减(Weight decay)为
训练过程分为两个阶段. 第1阶段是训练第2.2节中的跨模态学习网络. 在这一阶段中, 训练Batch size设定为32, 总共训练60轮, 初始学习率为
为了测试自注意力模块融合网络中每一个模块的有效性. 本节总共构建了5个网络. 第1个是一般的分类网络, 用作跨模态行人再识别的Baseline网络, 该网络由一个ResNet-50组成, 这里将其命名为“Baseline”; 第2个是第2.2节中构建的跨模态学习网络; 第3个是在跨模态学习网络的基础上加入自注意力模块, 命名为“跨模态 + 自注意力”; 第4个是在跨模态学习网络的基础上加入融合模块, 命名为“跨模态 + 模态融合”; 第5个是在跨模态学习网络的基础上加入融合模块以及自注意力模块, 即本文中的自注意力融合网络. 这5组网络在SYSU-MM01的实验结果如表1和表2所示, 表中汇集了CMC曲线中的Rank 1、Rank 10、Rank 20以及mAP的实验结果.
从表1和表2可以看出, 与Baseline相比, 在引入了CycleGAN生成的图像并利用跨模态学习网络同时训练原始图像和跨模态图像时, 在SYSU-MM01数据集上的成绩有显著的提升. 在All-search模式下, Single-shot和Mulit-shot的Rank 1分别提升了3.47%和4.77%. 在Indoor-search模式下, Single-shot和Mulit-shot的Rank 1分别提升了5.04%和5.03%. 这组对比实验说明了在第2.2节中提出的跨模态学习网络的有效性. 跨模态学习网络和Baseline相比, 同时利用了原始图像和生成的跨模态图像.
对比自注意力模态融合网络和第2.2节中的跨模态学习网络, 发现自注意力模态融合网络成绩有更近一步的提升. 在All-search模式下, Single-shot和Mulit-shot的Rank 1分别提升了2.48%和2.46%. 在Indoor-search模式下, Single-shot和Mulit-shot的Rank 1分别提升了0.88%和1.82%. 这组对比实验说明了本文提出的自注意力模态融合网络的有效性. 最后, 单独比较自注意力模态融合网络和“跨模态+自注意力”以及“跨模态+模态融合”, 发现由于生成图像存在很大的噪声, 对自注意力模块造成了一定程度的影响. 从而导致在Indoor-search和Multi-shot模式下, “自注意力模态融合”的mAP比起“跨模态 + 模态融合”下降了0.12%, 如何对生成的图像降噪是今后要解决的问题之一. 不过, 从总体来看, 两个模块共同使用比单独使用它们中的任一个模块都要有效.
我们参照SENet[27]中对网络时间复杂度的分析方法, 计算了在测试时加入各个模块后网络的GFLOPs (Giga floating-point operatiuns per second)和参数量, 如表3所示. 其中, 前三个方法的输入是一幅大小为256×128像素的图像, “跨模态 + 模态融合”网络和“自注意力模态融合”网络的输入是一幅大小为256×128像素的图像和一幅生成的相同大小的跨模态图像. 由表3可知, 跨模态学习网络与Baseline相比, GFLOPs和参数量都相同; 加入自注意力模块后, GFLOPs增加了0.001048576, 参数量增加了4.12%; 由于输入是两幅图, “跨模态 + 模态融合”网络GFLOPs是Baseline的两倍, 由于Max操作没有新增参数, 所以参数量没有发生变化. “自注意力模态融合”网络与Baseline相比, GFLOPs增加了2.706867200, 参数量增加了6.18%. 可见自注意力模块对GFLOPs的影响微乎其微, GFLOPs的增加主要来源于输入的增加.
我们在SYSU-MM01数据集上和跨模态行人再识别State-of-the-arts进行了对比. 其中“HOG +Euclidean”是在RGB-RGB匹配的行人再识别问题中利用模式识别方法解决, 手工特征选择HOG[32] 特征, 距离度量利用欧氏距离度量; “LOMO + KISSME”同样也是利用传统的模式识别方法, 手工特征选择LOMO[33] 特征, 距离度量算法利用KISSME[8]; “Zero-padding”[16]方法属于深度学习方法中的基于深度特征学习法, 该方法将三通道的RGB图转换为一通道的灰度图, 之后在第2通道进行零值填充, 将IR图直接在第1通道进行零值填充, 之后将填充后的RGB图和IR图统一放入网络中, 利用SoftMax损失进行训练; BDTR[17] 属于深度学习方法中的基于距离度量学习法, 该方法通过一个孪生网络对RGB图片和IR图片分别进行特征提取, 利用SoftMax损失和双向排序损失进行有监督的训练; cmGAN[18] 属于深度学习方法中的基于距离度量学习法, 该方法使用三元组损失来约束跨模态样本距离, 保证跨模态图像的负样本对距离大于跨模态图像的正样本对距离, 同时利用SoftMax 损失对行人ID进行有监督的训练. 另外结合GAN网络对抗训练的思想, 在判别器部分用一个二分类来区分图像是 RGB图还是IR图. 与上述4个方法对比的实验结果如表4和表5所示.
从表4和表5可以看出, 基于深度学习的跨模态行人再识别方法要远远好于传统的模式识别方法. 另外, 由于跨模态行人再识别目前的研究工作较少, 早期的Zero-padding利用的基网络为ResNet-6, BDTR利用的基网络为AlexNet[5]. 本文中利用的基网络和cmGAN方法中的基网络一致, 为ResNet-50. ResNet-50也是RGB-RGB行人再识别中最常用的基网络. 从实验结果看, 本文中提出的自注意力模态融合网络相较于上述方法成绩有一个比较大的提升. 在All-search模式下, Single-shot的Rank 1相比于Zero-padding、BDTR和cmGAN分别提升18.51%、16.3%和6.04%. Multi-shot的Rank 1相比于Zero-padding和cmGAN分别提升20.4%和8.22%. 在Indoor-search模式下, Single-shot的Rank 1相比于Zero-padding和cmGAN分别提升17.51%和6.46%. Multi-shot的Rank 1相比于Zero-padding和cmGAN分别提升21.37%和8.8%. 可以看出, 本文提出的自注意力模态融合网络在SYSU-MM01数据集上已经超过了现有的跨模态行人再识别方法.
跨模态行人再识别与传统的行人再识别相比, 增加了相同行人不同模态的变化. 为了解决跨模态问题, 本文提出了一种自注意力模态融合网络. 首先利用CycleGAN生成原始图像的跨模态图像, 之后利用跨模态学习网络将两个模态的图片都加入网络进行训练. 接着利用自注意力模块对原始图像和CycleGAN生成的图像分别进行特征筛选, 最后利用模态融合模块将两种模态的图片特征融合作为最后的行人再识别中行人的特征表示. 在SYSU-MM01数据集上的实验结果证明了本文提出的方法和其他跨模态方法相比有一定程度的提升. 本文首次将 CycleGAN 用于跨模态行人再识别图像生成, 实现数据的跨模态变化. 不仅在网络结构上进行了改进, 同时在数据层面进行了创新. 在今后的工作中将致力于提升跨模态生成的图像质量从而更好地解决跨模态行人再识别问题.