0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

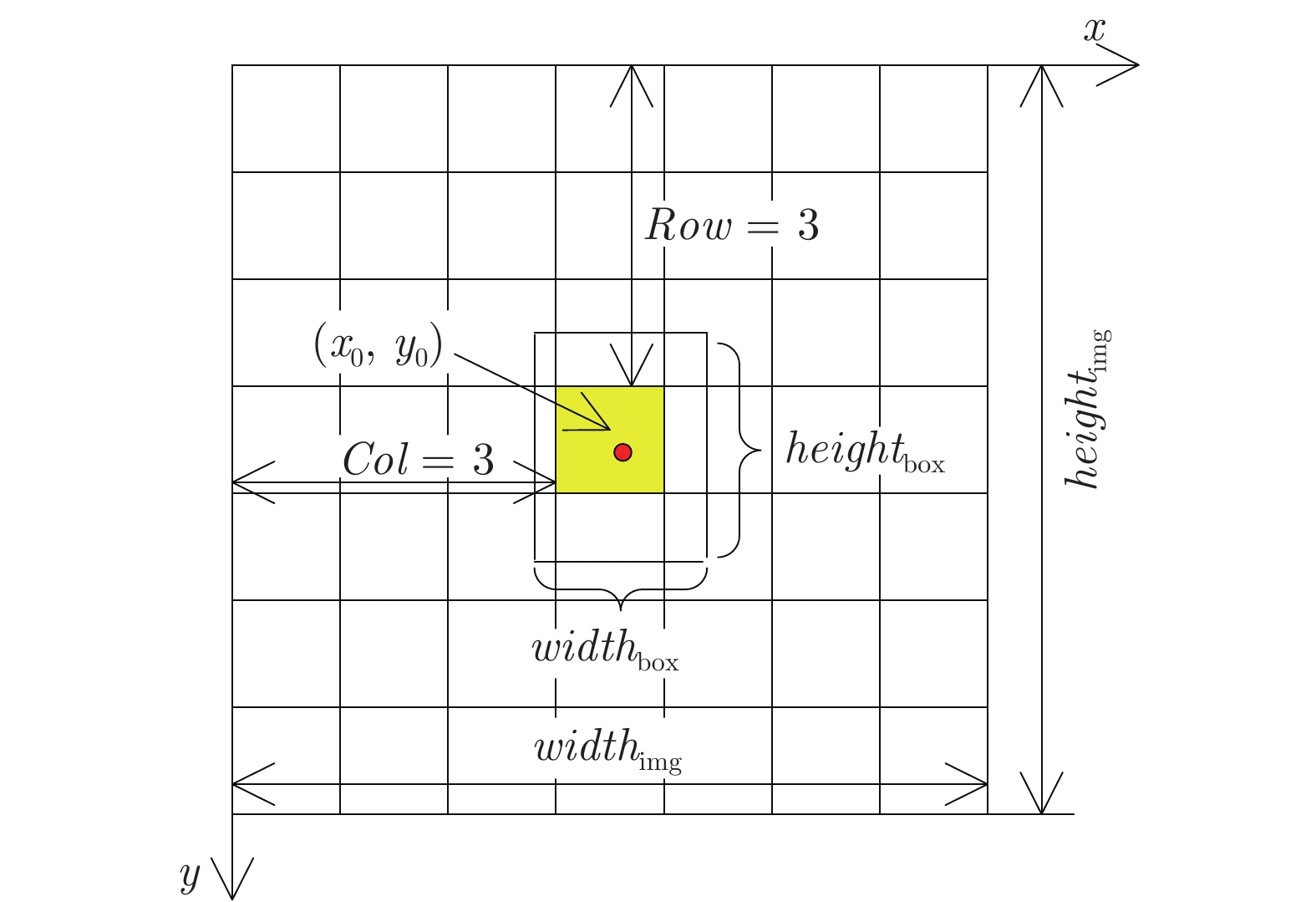
图 1 边界框参数归一化处理
Fig. 1 The normalization of boundary box parameters
车道线检测是智能驾驶领域的关键技术之一, 广泛应用于汽车辅助驾驶系统、车道偏离预警系统以及车辆防碰撞系统中. 随着计算机科学、人工智能和目标检测技术的飞速发展, 研究端到端的智能化车道线检测方法是自动驾驶领域的一条全新途径[1-6]. 因此, 研究基于深度学习的公路车道线检测方法对于提高公路交通安全具有重要意义.
对于车道线检测问题, 国内外学者已开展了相关研究, 取得了一定的研究成果[7-9]. 基于传统方法的车道线检测实质是通过图像特征和车载传感器来感知车辆当前环境并进行建模[10]. 存在检测速度慢、检测精度差、抗环境干扰能力差等问题. 文献[11]在常见的直线模型、多项式曲线模型、双曲线模型和样条曲线模型等二维模型的基础上, 提出了基于车道线特征的检测方法. 文献[12]在霍夫变换的基础上使用道路拟合算法精确标出道路俯视图中的车道线位置, 该方法可有效改善图像中其他车辆位置对检测效果的影响. 文献[13]提出了基于立体视觉的路缘边线检测方法, 该方法在真实路况条件下具有较强的稳定性. 文献[14]提出了基于车道线颜色和方向的几何特征结构化检测方法, 综合颜色和方向两个方面的信息对车道线进行拟合, 实现了车道线的检测. 文献[15]提出了基于视觉更具有鲁棒性的检测方法, 通过并行约束和多路模型拟合的方法提高了车道线检测的准确性.
近年来, 卷积神经网络(Convolutional neural network, CNN)在图像分类、目标检测、图像语意分割等领域取得了一系列突破性的研究成果. 基于深度学习方法的车道线检测常通过卷积神经网络对图像特征进行学习、分类和检测[16-17]. 文献[18-20]先后提出了区域卷积神经网络、快速区域卷积神经网络和超快区域卷积神经网络, 将网络应用到目标检测问题中, 并在检测速度和准确率方面不断提高. 文献[21]将改进的CNN应用在公路车道线检测方面, 测试效果较霍夫变换和随机抽样一致算法大幅提升. 为了进一步提高目标检测的速度, 文献[22]又提出了一种端到端的目标检测算法YOLO (You only look once), 将目标检测问题转化为回归问题, 进而将目标和背景进行更好的区分. 文献[23]提出的YOLOv2算法在简化网络结构的同时提高了目标检测的准确率. 文献[24]将YOLOv2算法应用在无人机航拍定位领域并得到理想效果, 在一定程度上验证了算法的普适性. 文献[25]提出了一种端到端的可训练网络VPGNet (Vanishing point guide network), 通过对大量图片的训练得到图像中的车道线位置, 为车道线检测问题提供了一种全新的解决思路. 文献[26]提出的YOLOv3算法借鉴了残差神经网络的思想, 成为目标检测算法中集检测速度和准确率于一身的优秀方法, 但其较YOLOv2算法相比, 网络结构更为复杂, 卷积层数目大幅增加, 加大了小目标在深层卷积过程中特征消失的风险.
为提高算法在车道线检测方面的适用性和准确性, 本文在YOLOv3算法的基础上进行改进, 采用随机性更小的K-means++算法替代K-means算法对车道线标签进行聚类分析, 确定最优的聚类数目和相应的宽高值, 并据此修改YOLOv3算法中的Anchor参数. 针对车道线检测实时性和检测目标较小的特点, 改进YOLOv3算法卷积层结构, 在保证检测准确率的同时, 提高算法的检测速度, 从而实现对公路车道线的检测.
YOLOv3算法将原输入图像划分为
| (1) |
式中, conf为边界框的置信度, Pr(obj)为网格中含有某类目标的概率.
每个网格预测的类别置信度为
| (2) |
式中,
通过设定阈值, 将类别置信度低于阈值的边界框剔除, 并对类别置信度高于阈值的边界框进行非极大抑制后得到最终的边界框. 预测得到的边界框包含
1)边界框宽高归一化处理
| (3) |
| (4) |
2)中心点坐标归一化处理
| (5) |
| (6) |
归一化处理后, 由于在每个网格中可得到
损失函数用来表征模型的预测值与真实值间的不一致程度, 是决定网络效果的重要参数之一. YOLOv3算法的损失函数的设计主要从边界框坐标预测误差、边界框的置信度误差、分类预测误差这三个方面进行考虑. 损失值越小说明模型的鲁棒性越好. YOLOv3损失函数计算式为
| (7) |
式中,
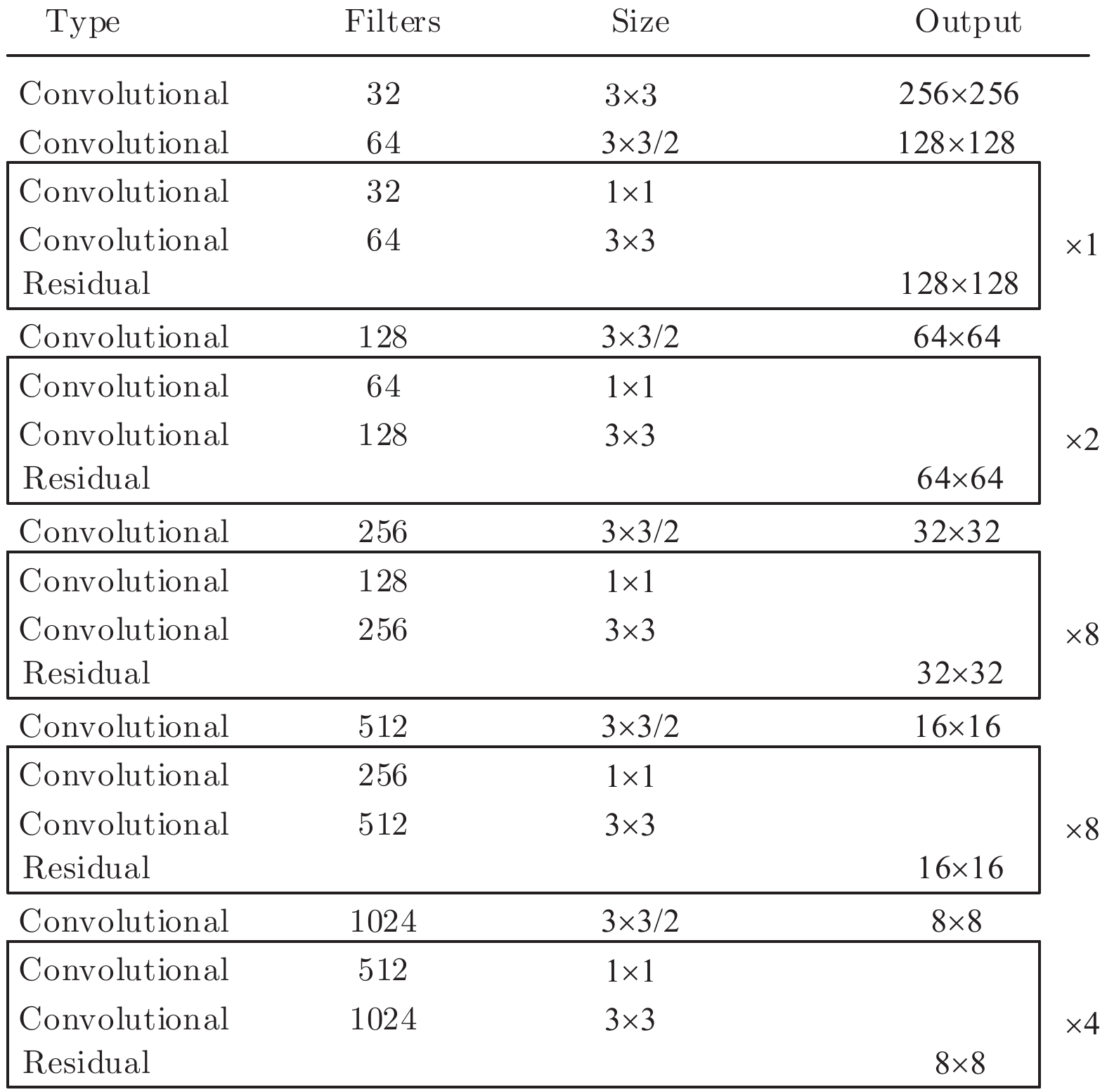
YOLOv3算法在Darknet-19和ResNet网络结构的基础上提出了新的特征提取网络Darknet-53. 该特征提取网络由52个卷积层和1个全连接层组成, 交替使用3
Darknet - 53 网络与 Darknet - 19、ResNet-101、ResNet-152 网络相比, 在Top-1准确率、Top-5准确率和每秒钟浮点运算次数三个方面均具有明显优势[26].
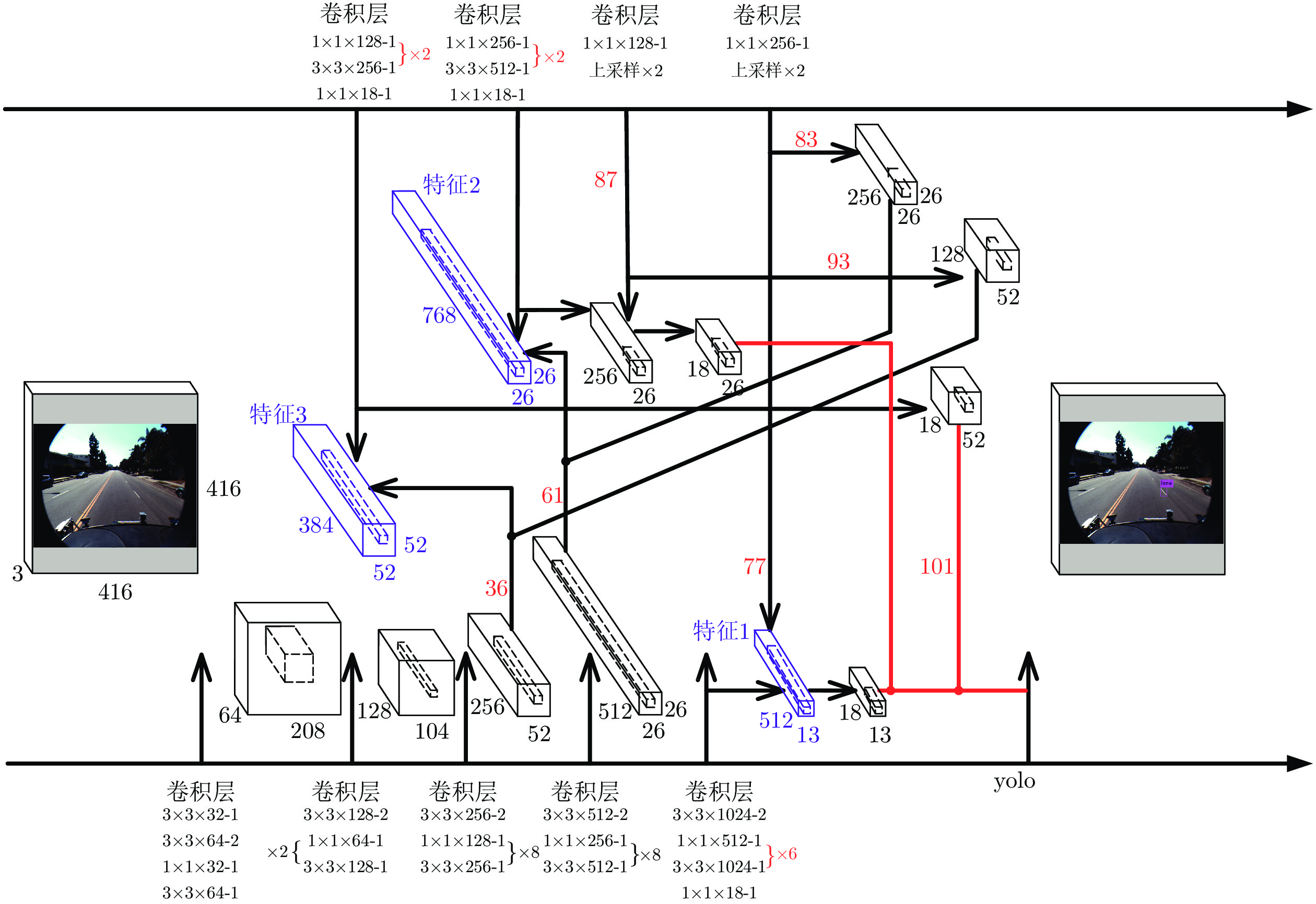
YOLOv3算法采用Darknet-53特征提取网络, 较Darknet-19网络相比, 通过加深网络层数提高了特征提取能力. 然而, 随着网络层数的加深, 在提高目标检测的准确性和召回率的同时也会带来如特征消失等问题, 两者存在着一定的相互制衡关系. 为得到更适合车道线目标的深度学习网络, 降低车道线小目标在复杂背景下的漏检风险, 精简YOLOv3网络结构, 分别去掉三个yolo层前的两组卷积层. 改进后的YOLOv3算法共101层, 由69层卷积层、23层残差层、4层特征层、2层上采样层和3层yolo层构成, 其网络结构如图3所示.
首先, 将图像缩放为3通道长宽均为416的统一形式, 作为整个网络的输入. 其次, 通过Darknet-53网络进行特征提取, 交替使用3
YOLOv3算法中引入了Anchor参数, Anchor是一组宽高值固定的先验框. 在目标检测过程中, 先验框大小直接影响到检测的速度和准确度, 因此在对公路车道线数据进行训练时, 根据车道线标签固有特点设定网络参数就显得尤为重要. 为适应公路车道线标签的固有特点, 达到最优的训练效果, 使用K-means++聚类算法代替K-means聚类算法对车道线标签进行维度聚类分析, 并进行比较. 上述两种算法均为典型的聚类算法, 由于考虑到K-means算法在初始聚类中心的选择上存在较大的随机性, 这种随机性会对聚类结果产生一定的影响. 因此, 使用随机性更小的K-means++算法可以有效降低K-means算法由于随机选择初始聚类中心所带来的聚类结果偏差.
在使用K-means和K-means++两种聚类算法确定Anchor参数的过程中, 为减少由于先验框自身大小所带来的欧氏距离误差, 以车道线标签样本框与先验框间的交并比代替原始算法中的欧氏距离作为目标函数, 目标函数大小表示各个样本与聚类中心间的偏差, 目标函数值越小表示聚类效果越好. 目标函数
| (8) |
式中,
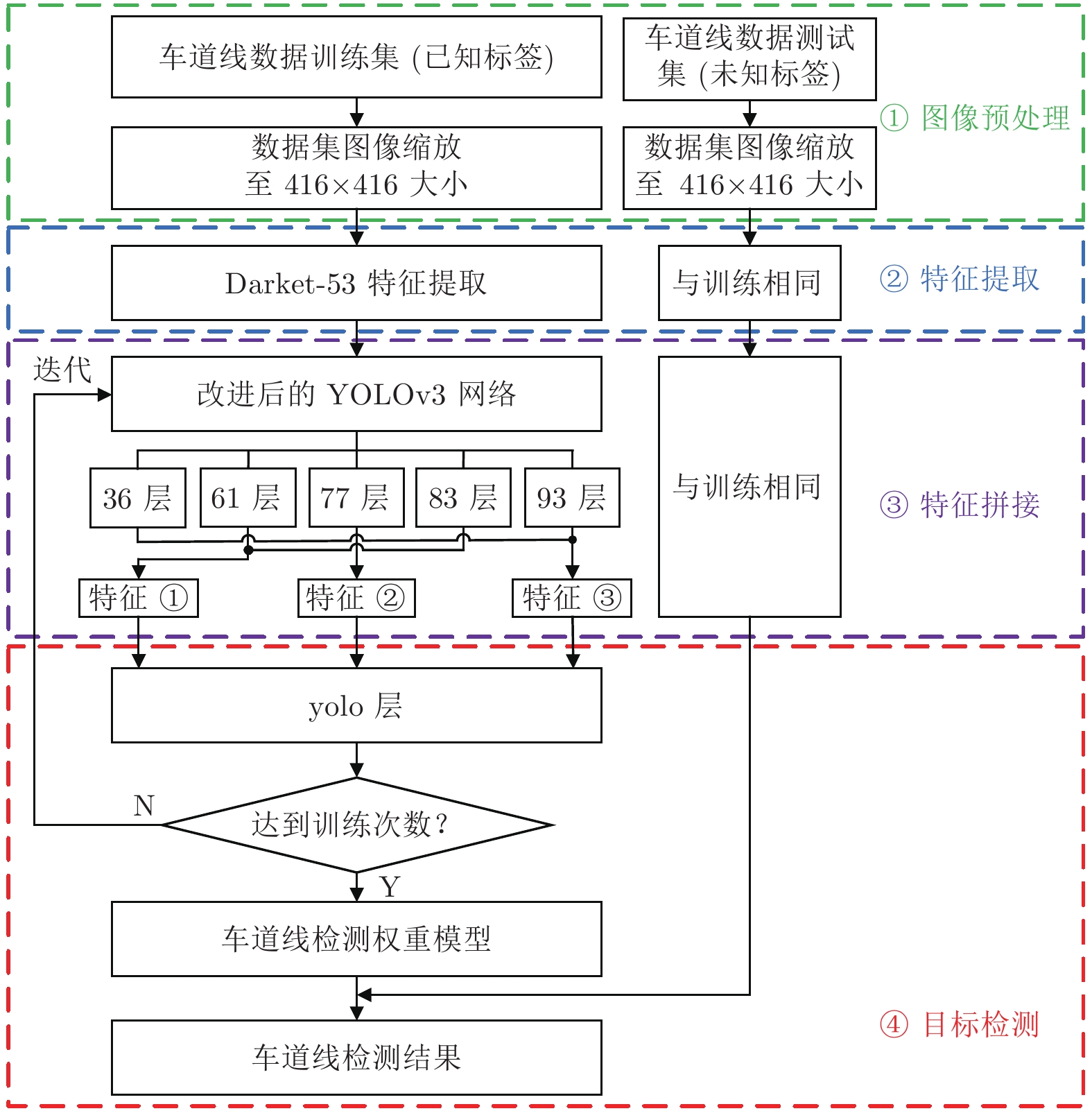
公路车道线检测方法以YOLOv3算法网络结构为基础, 为精简网络结构、减少在小目标检测时由于卷积层深度过深而导致的特征消失问题, 分别去掉三个yolo层前的两组卷积层, 使用改进后的网络结构进行训练和测试, 图4为公路车道线检测框图, 其检测具体流程如下.
1)对训练集中的车道线数据进行图像预处理, 将处理后统一形式的图像作为整个训练网络的输入;
2)将处理后的图像送入Darknet-53网络进行车道线特征提取;
3)提取第77层输出量作为第1个特征, 并对该特征进行一层卷积和一次上采样;
4)将第83层输出量与第61层输出量进行特征拼接得到第2个特征, 并对该特征进行一层卷积和一次上采样;
5)将第93层输出量与第36层输出量进行特征拼接得到第3个特征;
6)分别将3个特征送入yolo层进行训练, 达到训练次数后停止迭代, 并生成最终的权重模型;
7)将测试集图像输入同一网络, 调用训练得到的权重模型对测试集中图像进行车道线检测, 并输出检测结果.
在目标检测问题中, 训练数据集的选择和原始图像的标签制作是两个至关重要的步骤, 原始图像标签的准确性直接影响训练效果和测试的准确性. 实验中使用美国加利福尼亚理工大学车道线检测数据库作为数据集, 库内共包含1225幅公路图片, 分别在科尔多瓦和华盛顿两个地区对两组不同场景进行拍摄采集. 首先将数据库中的图像按照VOC2007数据集格式进行整理, 按比例将数据集中的图像随机分为训练集和测试集两类. 其次使用labelImg工具对训练集中的图像进行逐一标记, 并生成与之对应的xml格式的目标框位置信息文件. 最后编写python程序将xml格式的目标框位置信息进行归一化处理并转化为txt格式, 作为公路车道线数据集标签.
由于VOC数据集中并不含有与公路车道线相关的数据, 使用YOLOv3原始参数进行训练会对训练时间和训练准确度造成一定影响. 因此需要对公路车道线标签重新进行聚类分析, 从而得到针对车道线检测更具有代表性的Anchor参数.
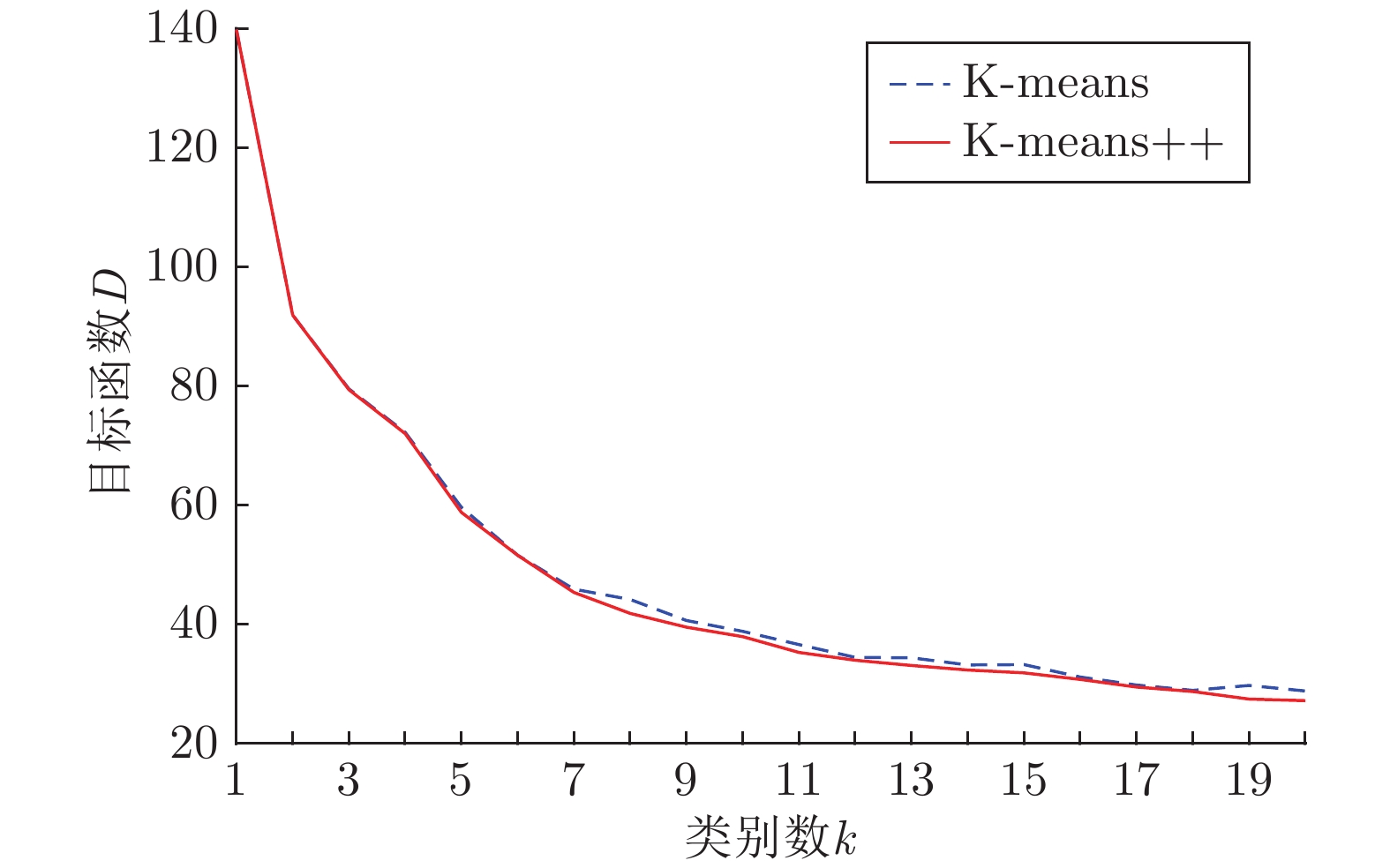
分别使用K-means算法和K-means++算法对车道线标签进行维度聚类分析, 随着
由图5可以看出, 随着
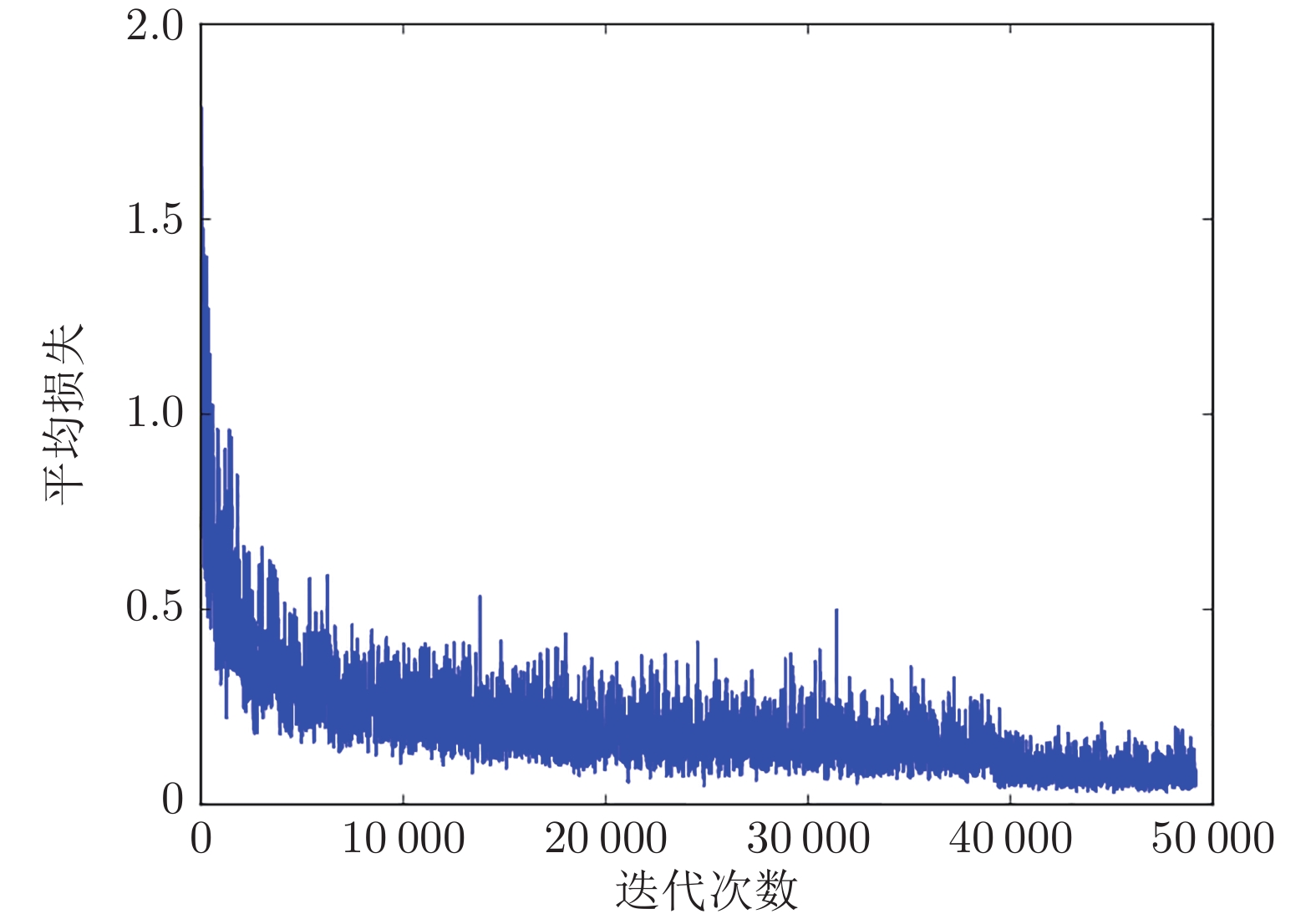
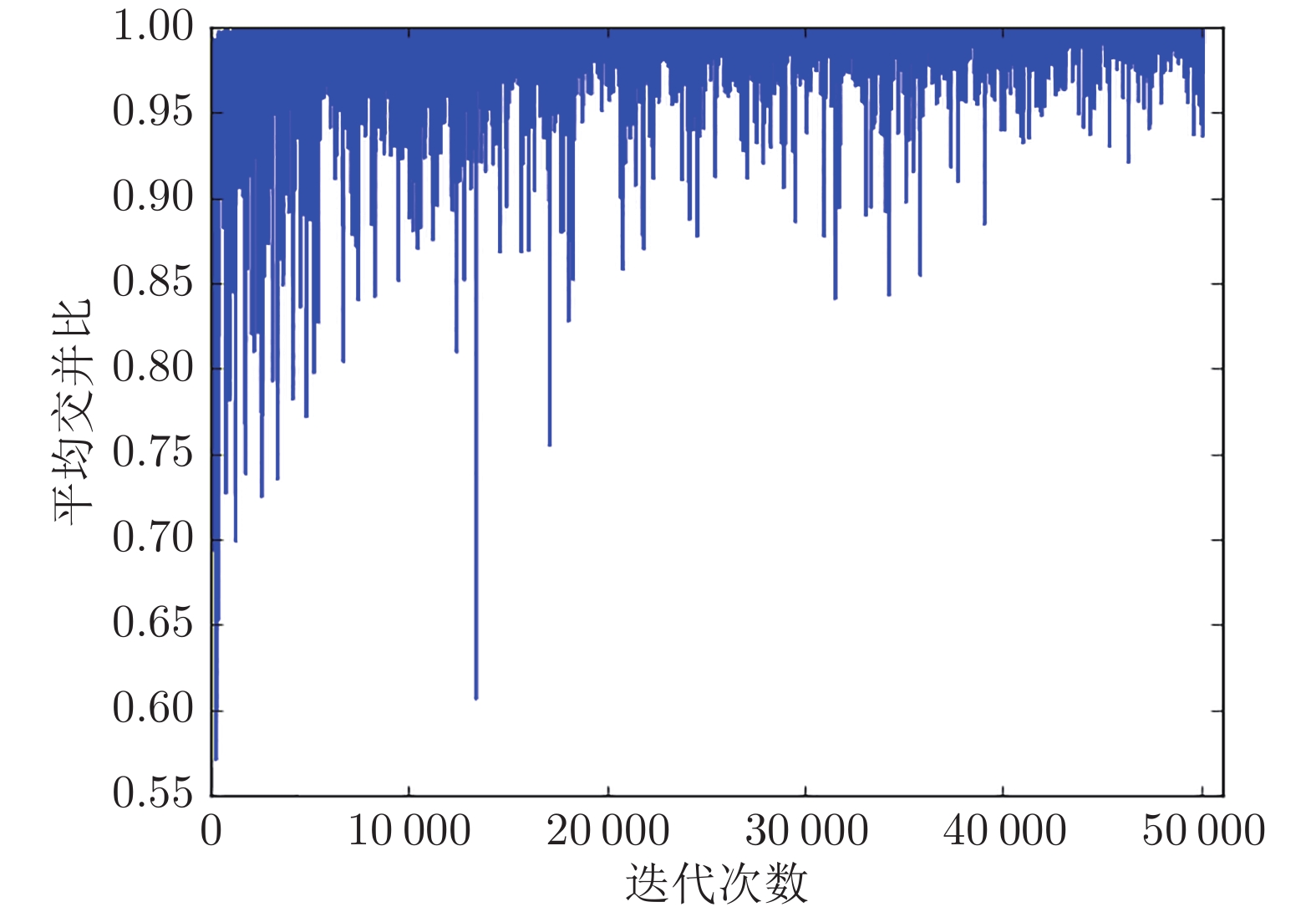
使用Intel(R)-CPU-E5-2620-V4处理器, 在Ubuntu 16.04操作系统下进行实验. 为了提高计算速度、减少训练时间, 使用Nvidia GeForce GTX 1080 Ti显卡、CUDA8.0和cuDNN6.0调用GPU进行加速. 训练过程中, 对算法的各项指标进行动态记录, 随着迭代次数的不断增加, 平均损失函数的变化趋势如图6所示, 平均交并比变化趋势如图7所示.
由图6可以看出, 训练开始时的损失函数值约为1.7, 随着训练迭代次数的增加, 损失值逐渐减小, 趋势逐渐平稳. 迭代至50000次时的损失值在0.1上下浮动, 即达到理想效果.
由图7可以看出, 训练开始时的平均交并比为0.58, 随着训练迭代次数的增加, 平均交并比逐渐增大, 说明模型的检测准确率在不断提高, 迭代至10000次后, 平均交并比可保持在90%以上. 调用训练生成的权重文件对测试集图片进行测试, 测试后可自动对测试图片中的同向白色实线车道进行标记, 并给出相应标签和置信度, 测试效果如图8所示.
对数据集中250幅城市路面图像进行分组, 剔除部分不包含车道线目标的图像后, 学习样本和测试样本共计225幅, 采用5倍交叉验证法, 即学习样本180幅, 测试样本45幅, 进行实验. 在确定训练权重模型的过程中, 为加快网络的训练速度, 有效防止过拟合, 根据经验设定网络中的权值衰减系数为0.005, 初始学习率为0.001, 阈值为0.25, 迭代次数为50200, 类别数为1, Anchor参数为表1中使用K-means++算法聚类分析后得到的宽高结果.
对相同车道线训练集分别使用K-means聚类算法优化Anchor参数的YOLOv3网络(YOLOv3-107)、K-means聚类算法优化Anchor参数并改进网络层数(YOLOv3-101)、K-means++聚类算法优化Anchor参数(YOLOv3-K-107)、K-means++聚类算法优化Anchor参数并改进网络结构(YOLOv3-K-101)等四种网络进行4轮实验.
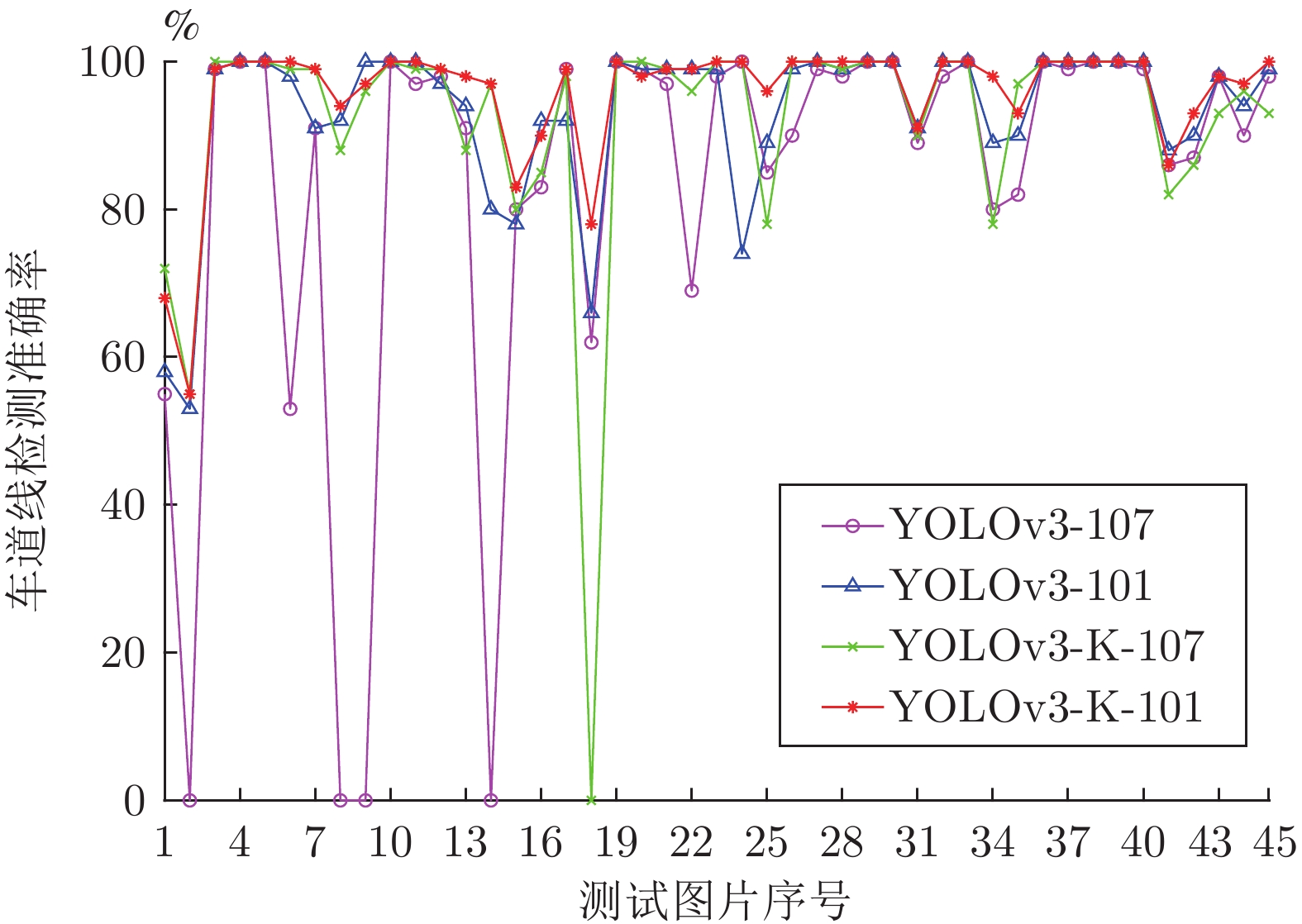
分别使用每轮训练最终生成的权重文件对测试集中45幅公路图像的车道线进行检测, 平均测试时间、平均漏检率和平均准确率 (Mean average precision, mAP)统计结果如表2所示. 对单幅图像在4组不同网络中得到的测试准确率对比结果如图9所示.
由表2和图9可见, 改进网络结构的YOLOv3-101网络相比未改进的YOLOv3-107网络, 检测的平均测试时间缩短了2 ms, mAP提高了5.4%, 且有效避免了车道线漏检情况; 使用K-means++算法进行聚类的YOLOv3-K-107网络, 相比使用K-means算法进行聚类的YOLOv3-107网络, 平均漏检概率降低了6.7%且mAP值提高了7%; 使用K-means++算法进行聚类且精简网络结构的YOLOv3-K-101网络效果最优, 其mAP值为95.3%, 测试速度达50帧/s且有效避免了漏检.
本文提出了一种改进YOLOv3算法的公路车道线检测方法. 首先使用K-means++算法对Anchor参数进行优化, 其次利用Darknet-53网络进行特征提取, 最后通过改进的YOLOv3-K-101网络实现特征拼接进而实现公路车道线检测, 得到以下结论:
1)提出了基于深度学习YOLOv3算法的公路车道线检测方法, 将深度学习方法与车道线检测问题相结合, 实现了对公路车道线的端到端检测.
2)根据公路车道线目标自身特点, 使用随机性更小的K-means++聚类算法替代K-means算法, 对YOLOv3算法中的Anchor参数进行优化. 实验表明, 优化后的YOLOv3-K-107网络比未优化的网络mAP值提高了7%, 在一定程度上提高了车道线检测的准确性.
3)针对公路车道线检测中漏检率高的问题, 精简YOLOv3网络结构, 改进后的YOLOv3-101网络较未改进前, 有效避免了车道线漏检情况, 同时mAP值提高了5.4%, 平均测试时间缩短2 ms.
4)结合2)和3), 优化网络参数且改进网络结构的YOLOv3-K-101网络, mAP值达95%, 较改进前提高了11%, 检测速度达50帧/s, 同时也有效避免了车道线漏检现象.
由于所提方法在对倾斜的车道线检测方面存在局限性, 下一步将采用对竖直目标框进行图像变换的方法或结合语义分割的思路进一步深入研究.