 0373-5939925
0373-5939925 2851259250@qq.com
2851259250@qq.com

基于热扩散核密度确定密度峰值法的历史工况识别
引 言
近年来,随着物联网、大数据和人工智能等技术的兴起,数据驱动的方法在工业智能化的进程中扮演着重要角色。在实际生产过程中,原料性质、生产方案或操作条件等因素的变动将导致生产过程的多模态化[1],如发酵过程[2]、冶金过程和锅炉燃烧过程等,对其过程进行数字化时往往存在着非线性、多模态和变量间的强相关性等问题[3-4]。因此,深入研究多模态过程的特点对实际生产有着重要作用。通过获取历史工况特征,不仅可以为当前装置选择合适的工况模型及参数进行优化,也能为生产决策提供重要的数据参考,如污水处理装置的智能优化、管道泄漏的自动化检测和生产运行状况的有效评估[5-6]等。
在对多模态过程的研究中,由于不同工况间存在着较大的差异,研究者通常假设每种工况下的过程数据近似服从一种高斯分布,运用主成分分析(PCA)、偏最小二乘(PLS)、独立成分分析(ICA)和支持向量数据描述(SVDD)模型等方法提取工况数据的特征,然后建立模型应用于过程故障检测、过程控制和过程优化等[7-10]。由于每种工况下的数据具有相似性,有学者将数据聚类的方法用于多模态过程的特征提取[11]。常用的聚类方法包括模糊C均值法[12]、K-均值法[13]、高斯混合模型(GMM)[14-15]和隐马尔可夫模型(HMM)[16]等,这些方法在获取数据特征时具有一定的有效性,但仍存在一些无法避免的缺陷。如K-均值法需要事先确定聚类数量,对数据中的噪声点敏感;模糊C均值法存在聚类数量和参数选取的问题;HMM模型需要事先知道各种模态的概率且固定不变;GMM模型在使用期望最大法求解时,存在计算量较大、对模型参数的初值敏感和容易陷入局部极值等问题,这些缺点都将导致无法准确地识别工况[17-18]。有学者对GMM模型进行深入研究,提出了给定模型参数初值[19]和基于信息准则确定聚类数量[20]的方法,其中F-J的方法较为著名[21-22],它通过在迭代计算中不断剔除冗余的高斯分量得出聚类结果,但是该方法需要一个较大的聚类数量导致计算量大且收敛困难,其结果的准确性也不能保证。
快速搜索发现密度峰[23](CFSFDP)是基于局部密度的一种聚类技术,它根据聚类中心点密度较大且与其他中心点距离较远的特点,引入高斯核密度估计函数(KDE)计算数据点的密度,再通过欧氏距离计算数据点间的距离,从而完成数据聚类。但是该方法的聚类效果取决于截距参数,为避免这一点,有学者对其进行改进并提出了无须事先确定截距参数的热扩散核密度确定密度峰的技术[24](CFSFDP-HD)。本文提出将CFSFDP-HD技术与GMM模型结合的方法,首先通过CFSFDP-HD方法对多模态过程数据进行聚类,然后将聚类结果作为GMM模型的初值,从而对多模态过程的工况进行较准确的估计。
1 工况识别方法
1.1 高斯混合模型
过程数据 X n×d 是d维的n个样本数据,且
其中,k为高斯模型的数量,τi 和
第i个高斯模型对应的高斯密度函数为:
模型的参数θi 常用EM法[25]求解,通过不断地更新后验概率和模型参数,直到模型参数几乎不变。针对数据
E步骤:
M步骤:
其中,
基于最短信息长度准则的F-J方法只需对
其中,
1.2 热扩散核密度确定密度峰技术
基于热扩散的高斯核函数为:
估算任意样本点i的概率密度函数为:
最佳带宽的选择使用了改进的Sheather–Jones(ISJ)方法[26],其计算步骤如下:
其中,当l ≥ 5时,l的取值对
带宽t的详细求解步骤如下:
(1)设置一个较小的容差ε = 10-9,令yq=ε,q = 0;
(2)计算
(3)如果
计算每一样本点i到最近的高密度点j的距离:
1.3 提出方法的计算步骤
本文提出的方法对近似服从高斯分布的未知多模态稳态工况进行识别时,首先利用CFSFDP-HD技术对多模态过程数据进行聚类,确定聚类中心点及其个数(即工况个数),然后将每一类数据的平均值和协方差作为GMM模型的初值,迭代求出不同工况的特征参数。其计算过程如下:
(1)将数据标准化处理,求取参数αk;
(2)由参数αk 和式(11)~
(3)由
(4)将每一类的特征参数作为GMM模型初值,求出最终工况参数。
通过以上步骤即可完成对历史工况的准确识别,下面通过第2节中的两个例子对该方法进行验证。
图1
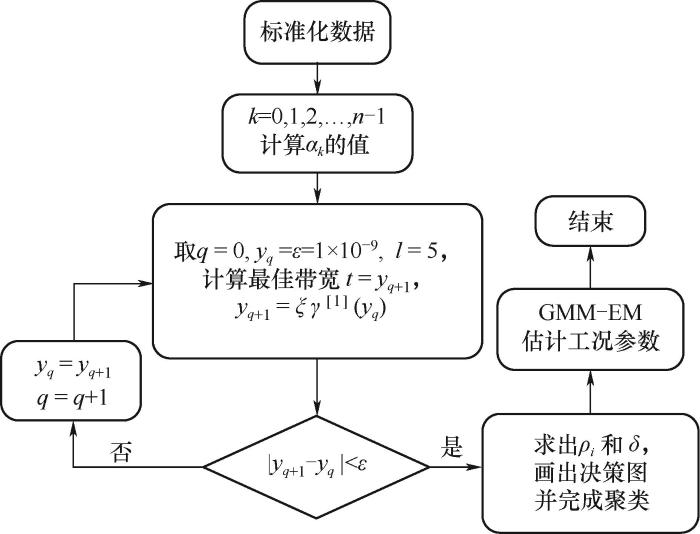
图1 基于热扩散核密度的工况识别方法流程图
Fig.1 Flow chart of recognizing operating modes based on kernel density estimation of heat diffusion
2 方法验证与结果分析
2.1 仿真数据
根据文献[27]中的多模态仿真模型生成过程数据,然后分别用本文提出的方法、K-均值法和GMM(F-J)的方法进行工况识别,数据生成模型如
其中,e1~e3是服从[0,0.01]的高斯白噪声分布,通过调整s1和s2的参数,生成含3个变量(x1、x2和x3)的多模态过程数据。其中模态1是变量s1和s2分别服从高斯分布为[20,0.8]、[1,1.3]得到的300个数据;模态2是变量s1和s2分别服从高斯分布[5,0.6]、[20,0.7]得到的300个数据;模态3是变量s1和s2分别服从高斯分布[16,1.5]、[20,0.7]得到的300个数据;模态4是和模态2在相同参数(工况)下产生的300个数据,用于检验三种方法能否准确地获取实际的工况状态。
将生成数据用
图2

图2 仿真多模态过程数据标准化
Fig.2 Normalization of multi-modal process simulation data
图3

图3 仿真多模态过程数据的聚类中心决策图
Fig.3 Clustering center decision diagram of process data for simulating multiple operating modes
表1 仿真多模态过程的工况识别结果
Table 1
| 项目 | 工况个数 | 每种工况的先验概率 | 每种工况下变量x1, x2, x3的平均值 | 相对偏差 |
|---|---|---|---|---|
| 实际值 | 3 | 0.25 | 11.777,296.288,12.410 | — |
| 0.25 | 20.467,192.899,354.307 | — | ||
| 0.5 | 10.351,19.900,152.718 | — | ||
| 本文方法 | 3 | 0.25 | 11.777,296.288,12.410 | 0,0,0 |
| 0.25 | 20.467,192.899,354.307 | 0,0,0 | ||
| 0.5 | 10.351,19.900,152.718 | 0,0,0 | ||
K-均值法 (K = 3) | 3 | 0.25 | 11.777,296.288,12.410 | 0,0,0 |
| 0.25 | 20.467,192.899,354.307 | 0,0,0 | ||
| 0.5 | 10.351,19.900,152.718 | 0,0,0 | ||
K-均值法 (K = 4) | 4 | 0.25 | 11.777,296.288,12.410 | 0,0,0 |
| 0.136 | 21.4211,209.428,388.063 | 4.66,8.57,9.53 | ||
| 0.114 | 19.3326,173.233,314.144 | 5.54,10.2,11.34 | ||
| 0.5 | 10.3508,19.900,152.718 | 0,0,0 | ||
GMM(F-J)法 (K = 4) | 4 | 0.25 | 11.777,296.288,12.410 | 0,0,0 |
| 0.203 | 10.0372,15.8427,152.52 | -2.84,-19.7,0.01 | ||
| 0.25 | 20.467,192.899,354.307 | 0,0,0 | ||
| 0.297 | 10.5662,22.6857,152.853 | 1.88,13.03,-0.05 | ||
GMM(F-J)法 (K = 5) | 4 | 0.25 | 11.777,296.288,12.410 | 0,0,0 |
| 0.203 | 10.0372,15.8426,152.52 | -3.03,-20.39,-0.13 | ||
| 0.25 | 20.467,192.899,354.307 | 0,0,0 | ||
| 0.297 | 10.5662,22.6857,152.853 | 2.08,14,0.09 |
2.2 TE过程
Tennessee Eastman(TE)工业过程是由美国Eastman化学品公司开发的复杂工业过程的仿真平台,它包括六种工作模态,每种模态具有不同的产品比例(G/H),该流程包含12个操作变量、22个连续过程测量变量和19个组成测量变量[28-30]。本文选取TE过程中模态1~模态4作为多模态过程,选取41个测量变量作为工况识别的变量,其中每种模态取300个数据为1组,第5组和第3组为相同模态下的数据,具体模态选取情况见表2。
表2 TE过程的模态选取情况
Table 2
| 项目 | 模态 | G/H比例 | 产品生产率 |
|---|---|---|---|
| 第1组 | 1 | 50/50 | 7038 kg/h G和7038 kg/h H |
| 第2组 | 2 | 10/90 | 1048 kg/h G和12669 kg/h H |
| 第3组 | 3 | 90/10 | 10000 kg/h G 和1111 kg/h H |
| 第4组 | 4 | 50/50 | 最大生产率 |
| 第5组 | 3 | 90/10 | 10000 kg/h G 和1111 kg/h H |
将过程数据用
图4

图4 4个TE过程变量的标准化
Fig.4 Normalization of 4 TE process variables
图5

图5 TE多模态过程数据的聚类中心决策图
Fig.5 Clustering center decision diagram of TE multi-modal process
表3 TE多模态过程的工况个数及先验概率的识别结果
Table 3
| 项目 | 实际值 | 本文方法 | K-均值法(K = 4) | K-均值法(K = 5) | K-均值法(K = 6) | GMM(F-J)法(K ≥ 4) |
|---|---|---|---|---|---|---|
| 工况个数 | 4 | 4 | 4 | 5 | 6 | 无法得到参数 |
| 每种工况的先验概率 | 0.2 | 0.2 | 0.2 | 0.2 | 0.06 | 无法得到参数 |
| 0.2 | 0.2 | 0.2 | 0.2 | 0.08 | ||
| 0.4 | 0.4 | 0.4 | 0.106 | 0.06 | ||
| 0.2 | 0.2 | 0.2 | 0.094 | 0.2 | ||
| 0.4 | 0.4 | |||||
| 0.2 |
表4 TE多模态过程变量的识别结果
Table 4
| 变量 | 本文方法 | K-均值法(K = 4) | ||||
|---|---|---|---|---|---|---|
| 平均相对偏差 | 最大相对偏差 | 最小相对偏差 | 平均相对偏差 | 最大相对偏差 | 最小相对偏差 | |
| D物料流量 | -0.081 | -0.4104 | -0.0225 | -0.0814 | -0.412 | -0.0225 |
| 回收流量 | 0.0912 | 0.2786 | 0.0062 | 0.0909 | 0.2778 | 0.0062 |
| 放空率 | -1.3681 | -4.748 | -0.9476 | -1.4371 | -4.9847 | -0.9567 |
| 反应器进料量 | 0.0645 | 0.1505 | 0.0357 | 0.0644 | 0.1503 | 0.0357 |
| 产品分离器压力 | -0.0043 | -0.0148 | -0.0014 | -0.0043 | -0.0148 | -0.0014 |
| 汽提塔温度 | 0.0189 | 0.2343 | 0.0613 | 0.0186 | 0.2337 | 0.0613 |
| 压缩机工作功率 | 0.1075 | 0.3217 | 0.0441 | 0.1071 | 0.3207 | 0.0441 |
| 反应器组分B流量 | -0.1046 | -0.4776 | -0.1074 | -0.1054 | -0.4799 | -0.1075 |
| 放空气体中G组分流量 | -0.0142 | -0.9356 | 0.1306 | -0.0173 | -0.9444 | 0.1305 |
| 产品中组分H流量 | -0.0424 | 0.4618 | 0.1825 | -0.0438 | 0.4597 | 0.1821 |
从表3可以看出本文方法得到的历史工况的个数和先验概率与实际值一致;K-均值法的结果则取决于设定的聚类数量K,当K与实际一致(K = 4)时也可以较准确获取历史工况的个数及先验概率,但是当K = 5和K = 6时,其结果与实际相差较大。GMM(F-J)法则无法获取到工况的参数。
三种方法过程变量的识别结果见表4,可以看出本文提出的方法识别结果的平均相对偏差在 -0.0043~-1.3681,最大相对偏差为-4.748,最小相对偏差为-0.0014;K-均值法识别结果的平均相对偏差在-0.0043~-1.4371,最大相对偏差为-4.9847,最小相对偏差为-0.0014。结合表3、表4可以看出GMM(F-J)法不适合本案例的工况识别,本文方法和给定准确聚类数量的K-均值法都可以较准确地识别出工况特征,但K-均值法的准确性依赖于聚类数量的选择,而本文方法则没有这种约束。
3 结 论
针对目前工况识别方法的不足,提出将人工智能领域的CFSFDP-HD技术与GMM模型结合用于对多模态过程的历史工况进行识别的方法,避免了K-均值法需要预先提供准确聚类数量的缺点,并利用案例对本文所提方法进行了验证,结果表明:GMM(F-J)法不能保证准确地识别工况,K-均值法只有在给定正确工况数量的前提下才能获得较好的结果,而本文方法则可方便、有效地对历史多工况进行准确识别,具有更强的实用性。
符 号 说 明
| 过程变量的个数 | |
| g(x | θi ) | 第i个高斯模型所对应的高斯密度函数 |
| 聚类的数量,也是高斯模型的数量 | |
| 第k个高斯模型,也表示第k个数据 | |
| P(s)(Ck|xj ) | 第j个样本点第s次迭代属于第k个高斯模型的概率 |
| P(di,dj,t) | 样本点i到j的转移概率 |
| p(x|θ) | 概率密度函数 |
| 高斯核密度估计函数的带宽 | |
| 样本数据矩阵,n为样本数,d为变量数 | |
| 变量i的第j个样本数据 | |
| 变量i的最大样本数据 | |
| 变量i的最小样本数据 | |
| 样本点到附近高密度点的距离 | |
| 第i个高斯模型的参数 | |
| 第i个高斯分量的变量平均值 | |
| 样本点的密度 | |
| 第i个高斯分量的方差 | |
| 第i个高斯分量的权重 |

- 刚刚!2026年中科院分区,公布!本次看点:中科院分区变更为新锐分区;不再单独发布预警期刊;37种期刊“under review”~
- 这些重要报纸理论版都支持邮箱投稿!回复极快!
- GB/T 7714-2025与GB/T 7714-2015相比,变更了哪些,对期刊参考文献格式有什么影响?
- 别被这个老掉牙的报纸理论版投稿邮箱误导了!最新核实91个报纸理论版投稿邮箱通道,一次集齐
- 喜报!《中国博物馆》入选CSSCI扩展版来源期刊(最新CSSCI南大核心期刊目录2025-2026版)!新入选!
- 2025年中科院分区表已公布!Scientific Reports降至三区
- 国内核心期刊分级情况概览及说明!本篇适用人群:需要发南核、北核、CSCD、科核、AMI、SCD、RCCSE期刊的学者
- CSSCI官方早就公布了最新南核目录,有心的人已经拿到并且投入使用!附南核目录新增期刊!
- 北大核心期刊目录换届,我们应该熟知的10个知识点。
- 注意,最新期刊论文格式标准已发布,论文写作规则发生重大变化!文字版GB/T 7713.2—2022 学术论文编写规则

